
FIGURE 3.
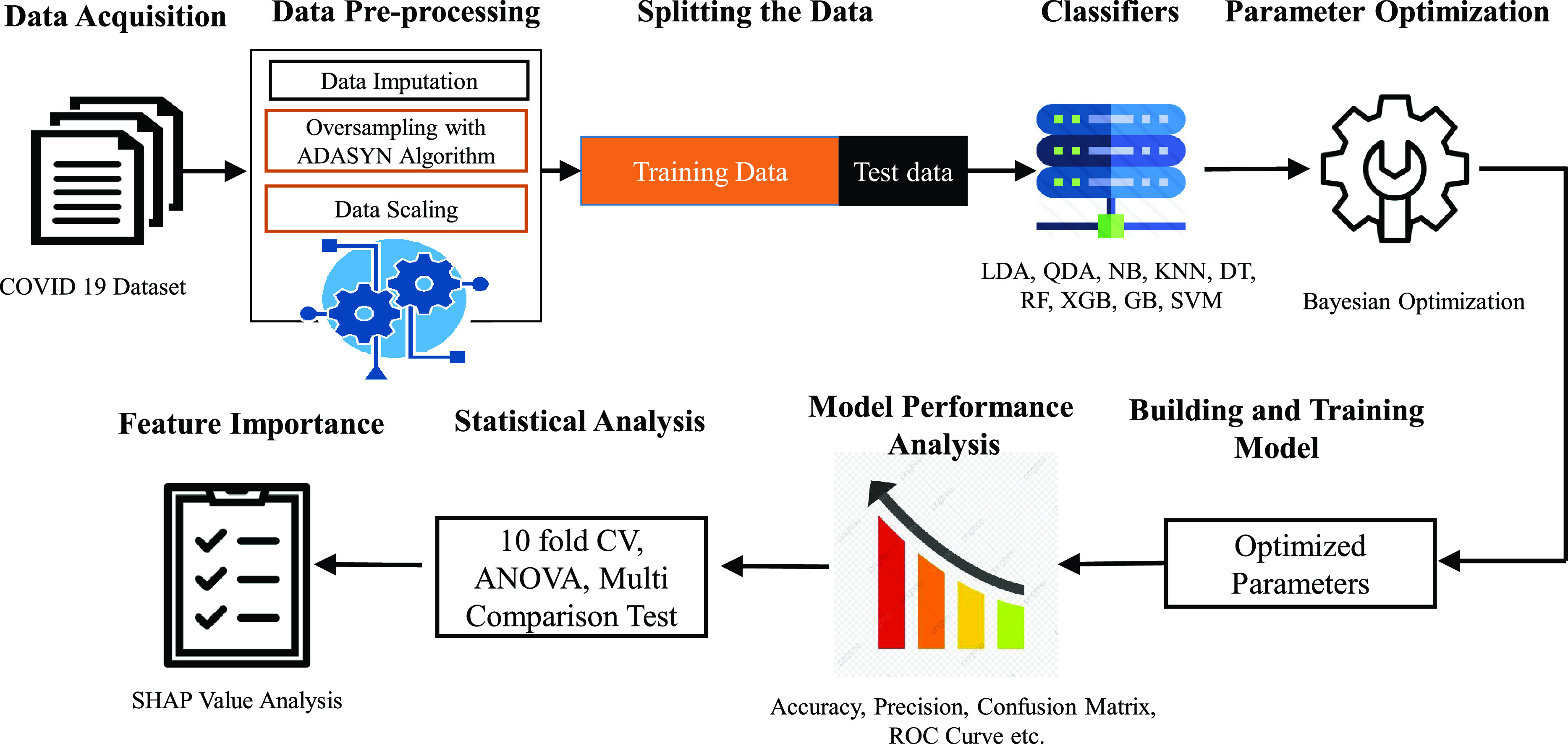
The overall workflow of the classification of COVID-19. The first phase is collecting raw data followed by pre-processing, where the raw data is imputed, scaled, and most importantly, the imbalanced data is balanced using ADASYN algorithm. Secondly, the pre-processed data are split into the train and test set used by different classifiers to measure the classification performance. In the next step, Bayesian optimization has been implemented to tune the hyperparameters of the classifiers. This optimized classification model is then tested, and different performance metrics (accuracy, precision, Confusion matrix, ROC, 10-fold cross-validation, ANOVA, and multi-comparison test) have been used for evaluation. Finally, the important features have been efficiently traced using SHAP analysis.