
Fig. 3.
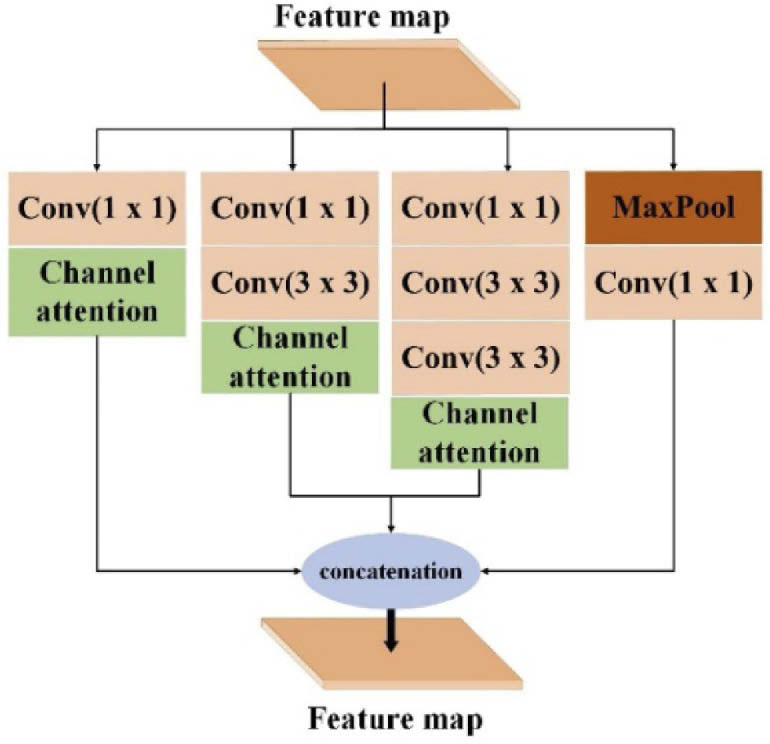
The details of the multi-scale attention layer. This layer is incorporated into each down-sampling attention block. The feature map through the previous down-sampling operation as input is fed into this layer. This layer contains four branches, which each branch extracts different scale features by convolutions with a different receptive field, i.e., 1 ×1, 3 × 3, and 5 × 5. Then, the attention features through the channel attention layer of all branches are concatenated to get the final feature map of the current down-sampling operation.