
Fig. 1.
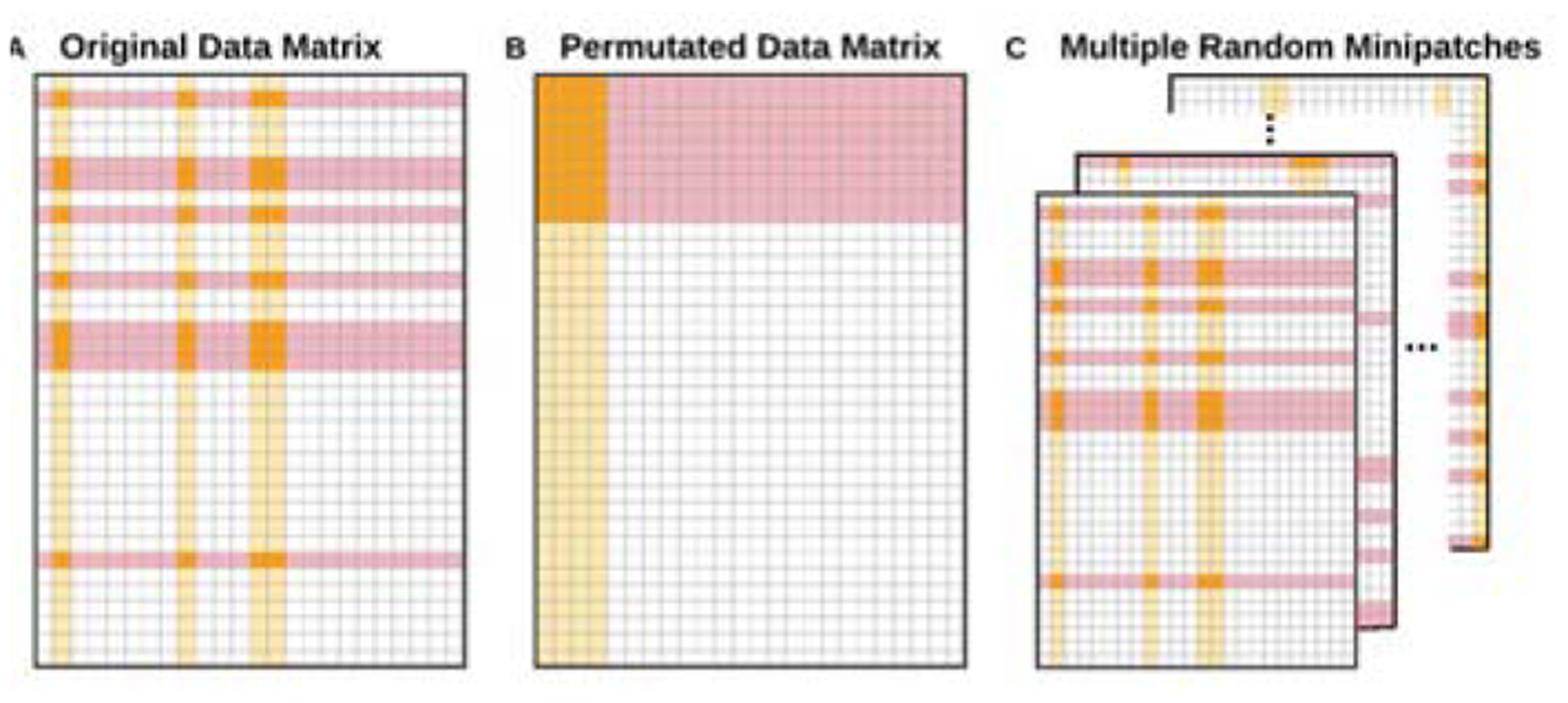
A. Simultaneous random subsampling of examples (rows in red) and features (columns in yellow) without replacement from the original data matrix yields a “minipatch” (orange). B. The same minipatch in A is a random submatrix of the data matrix after a permutation. C. Minipatch learning is an ensemble of learners trained on many random minipatches.