

Abstract
The common pheasant, a game species widely introduced throughout the world, can be considered as an ideal model to study the effects of introduction events on local adaptations, biogeographic patterns, and genetic divergence processes. We aimed to assess the origin, spatial patterns of genetic variation, and demographic history of the introduced populations in the contact zone of Central and Southeast Europe, using mitochondrial DNA control region sequences and microsatellite loci. Both types of molecular markers indicated relatively low to moderate levels of genetic variation. The mtDNA analyses revealed that common pheasants across the study area are divided into two distinct clades: B (mongolicus group) and F (colchicus group). Analyses of the microsatellite data consistently suggested a differentiation between Hungary and Serbia, with the pheasant population in Hungary being much more genetically homogeneous, while that of Serbia has much more genetic mixture and admixture. This cryptic differentiation was not detected using a non-spatial Bayesian clustering model. The analyses also provided strong evidence for a recent population expansion. This fundamental information is essential for adequate and effective conservation management of populations of a game species of great economic and ecological importance in the studied geographical region.
Subject terms: Ecology, Genetics
Introduction
Genetic variation plays a central role in the evolution and ability of species to adapt to continuous environmental changes, and in their long-term persistence in the face of an increasing and constant anthropogenic disturbances1,2. Characterizing the genetic diversity of populations, understanding the spatial patterns of this variation in the landscape, and investigating possible historical and current causes for these patterns, is fundamental knowledge for an informed conservation management of wildlife, which is especially critical for threatened populations3–5.
The spatial patterns of genetic variation and population structure of species may be influenced by geographic distance6, natural and anthropogenic barriers7–9, migration behaviour and sex-biased dispersal10, climate change11, and human introductions and hybridization12–14. The introduction of species to areas outside of their historic range is a widespread management action to support harvest in wildlife, fisheries, and forestry15. However, translocating species may lead to genetic admixture between taxa due to hybridization, and therefore change spatial patterns of genetic variation and population structure of native species, or cause gradual dilution of autochthonous genetic diversity and reduce individual fitness due to outbreeding1,16. Unrecorded releases of individuals from different subspecies for hunting purposes , besides possibly being detrimental to natural populations (e.g. outbreeding depression), further complicate our understanding of the genetic profile of introduced populations17–20.
The common pheasant (Phasianus colchicus L.), a non-migratory gallinaceous bird, can be considered as an ideal model for studying the effects of introduction events on local adaptations, biogeographic patterns, and possible speciation processes21. The common pheasant, with 31 described subspecies based on morphology, colour patterns, and range discontinuities22, is considered native from eastern Siberia to China, Iran, the Caucasus and the south-eastern Balkans22,23. The subspecies inhabit significantly different landscapes and climatic niches, from montane ecosystems to isolated oases in semi-desert regions, exhibiting distinct phenotypes and genotypes24,25. Although the common pheasant is widespread and relatively common over most of its range, local and regional populations are facing declines mainly due to over-hunting and habitat loss26. For example, P. c. talischensis, from Azerbaijan and northwest Iran bordering the southwest of the Caspian Sea, is now a very rare subspecies27 comprising a total population of 200–300 individuals28.
The common pheasant has been introduced to Europe, North America, and Australia26. The first known introductions of the species into Europe, consisting of South Caucasus pheasants (P. c. colchicus), date back to 500–800 AD29. Much later, already in the eighteenth century, Mongolian (P. c. mongolicus) and Chinese ring-necked pheasants (P. c. torquatus) were also brought in to Europe29. The European populations are therefore descended from several subspecies and possibly from hybridization between them22. Therefore, the identity of these subspecies and the genetic composition of the introductions still need to be investigated because some common pheasant morphological subspecies are not supported by molecular data30, possibly as a result of recent range expansions and subspecies admixture31. Hybrids of different subspecies may also have been released in areas with native subspecies in Southeast Europe, which may lead to the extinction of the latter by genetic swamping32, as apparently in the case of the indigenous South Caucasus pheasant populations in Bulgaria22.
In Europe, the common pheasant is historically considered as one of the most important game species for recreational hunting33. It is especially prized by hunters for its meat and for being suitable for group hunting with dogs34. Non-random removal of individuals from wildlife populations by recreational hunting may affect the genetic structure, morphology, life history, and, ultimately, the viability of the target population35–38. Moreover, the common pheasant in Europe has long had extensive re-stocking to maintain populations and for hunting purposes, in which released individuals are mostly of non-local origin and farm-reared17,22,24,33,39. These individuals may have low genetic diversity, maladaptive alleles, and lower fitness in the local natural environment than indigenous individuals. Hybridization and introgression of maladaptive alleles into local populations can degrade autochthonous genetic heritage and disrupt coadapted gene complexes, making these populations less adapted to their environment15. It is likely that a large percentage of captive-bred individuals released recently and today, due to their possibly lower ecological fitness in foreign natural conditions, have been quickly removed by hunters and predators and generally have low survival and reproduction. Therefore, it is probable that the reproductive contribution of captive-bred individuals to the next generations is less than could be expected, and their greatest impact may be the transmission of livestock diseases and parasites. The combined effects of the selective removal of individuals (e.g. hunter bias for males) and hybridization and introgression with individuals of lower fitness are likely to have a profound impact on the evolution, genetic health, and long-term persistence of native game populations16,37,38,40.
It has been suggested that processes of introduction, stocking, and restocking in the common pheasant may lead to genetic differentiation between locations, likely enhanced by founder effects and genetic drift associated with small propagules, and that is subsequently maintained by limited interpatch gene flow41. Thus, the genetic structure of introduced common pheasant populations should be strongly shaped by founder effects, increased genetic drift, small to modest effective population sizes (Ne), and inbreeding41.
Despite the long history of the common pheasant as one of the most important game birds in Europe, nothing is known about the genetic variation and structure of the European populations. From a genetic point of view, the species has been studied essentially in terms of phylogeography and subspecies taxonomy throughout its distribution across Asia30,31,42–44, with the most recent data supporting eight major clades in this extant native range45. Evaluating genetic variation and structure in common pheasant populations, and identifying those with low and high levels of genetic diversity, is crucial for effective conservation and management of the species, for example to inform translocation efforts.
In this study, we begin the investigation of the origin, genetic diversity and structure, and demographic history of the common pheasant in Europe, with the analysis of populations in the contact zone between Central and Southeast Europe. We also compared the genetic diversity in the study area with that which has been reported in Asian populations, and assessed the hypothesis that the studied populations are derived exclusively from introductions from Asia. To this end, we analysed variation in a fragment of mitochondrial DNA (mtDNA), a molecular marker of excellence for phylogeography46 and for assessing the geographic origin of introduced lineages47,48, and in a set of polymorphic nuclear microsatellites, which are known to be powerful markers for studying genetic structure and processes at small temporal and spatial scales49. It is recognized that the combined analysis of mtDNA and microsatellites can be very informative for phylogeographic and population genetic studies of natural populations50,51.
Results
Mitochondrial DNA
Genetic diversity and phylogenetic analyses
A 825 base pairs (bp) fragment of the mtDNA control region was sequenced for 69 P. colchicus individuals, 29 samples from Hungary and 40 samples from Serbia (Fig. 1). Additional sequences available on GenBank were included in the data set, resulting in a total of 271 sequences and 137 haplotypes (Table S1). Among our samples we detected 10 haplotypes, three previously reported and seven novel. In these 69 sequences, 20 of the 825 sites were polymorphic, nine of them singletons and 11 parsimony-informative.
Figure 1.

Sampling localities of the common pheasant in the contact zone of Central and Southeast Europe. Green circles and red squares indicate clades B and F, respectively, and the numbers next to these symbols denote the haplotypes found in each sampling locality, according to the numbering assigned to them (see Figs. 2 and 3 for details). Map
source: ESRI. The map was generated using ArcGIS 10.4.1 by ESRI (available online at: http://www.esri.com/).
The ML and BI phylogenetic analyses of the 137 P. colchicus haplotypes plus the three P. versicilor outgroup sequences yielded identical topologies, indicating the presence of six main lineages with significant support from bootstrap values and Bayesian posterior probabilities (Fig. 2). Focusing on the 69 individuals analyzed here, the results suggest that the common pheasant mitochondrial haplotypes in the contact zone of Central and Southeast Europe belong exclusively to clades B and F (Fig. 2). Clade F is much more frequent and geographically widespread, while clade B is mainly present in Serbia, where the geographic overlap between the two clades is much more significant (Fig. 1). Within clade B, the new haplotypes H2 and H10, together with H31 (= haplotype C83 from Zhaosu, China, assigned to P. c. mongolicus;42) and H51 (previously detected by Qu et al.42 in an individual from Xianghai, China, assigned to P. c. pallasi, and in an individual from Libo, China, assigned to P. c. decollatus; see Table S1 for details) are closely related and form a small clade in the phylogenetic tree (Fig. 2). Haplotype H6, the third new haplotype in clade B, also formed a small clade with haplotypes H47 (= haplotype C66 from Anyang, China, assigned to P.c. torquatus;42) and H79 (= haplotype C24 from Xinyang, China, assigned to P.c. torquatus;42) (Fig. 2).
Figure 2.
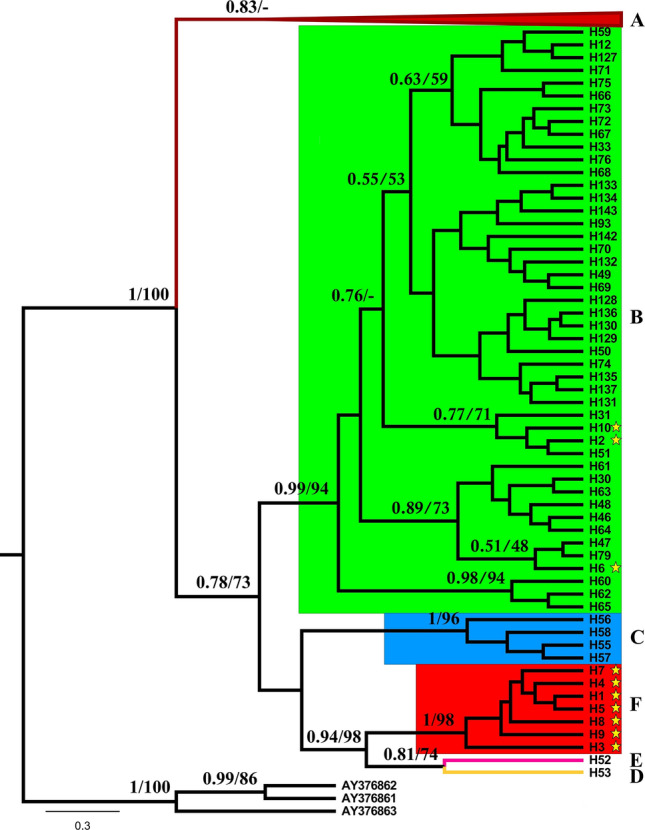
Phylogenetic relationships of common pheasant from the contact zone of Central and Southeast Europe with other common pheasants, based on the analyzed 825-bp fragment of the mtDNA control region and rooted with the green pheasant (P. versicolor; AY376861-3). The numbers on nodes are Bayesian posterior probabilities and ML bootstrap values, respectively. Yellow stars indicate haplotypes detected in this study. See Table S1 for details on haplotypes.
The median-joining network also recovered the haplotype groups identified in the phylogenetic trees (Fig. 3). The number of haplotypes in clades B (9 individuals) and F (60 individuals) were three and seven, respectively (Table 1). Haplotype H1 was the most common (Fig. 3) and being shared by 54 individuals across the study area. The second most common haplotype was H2, which was shared by seven individuals and also found over a relatively wide geographical area. The two main mitochondrial lineages exhibited relatively low haplotype and nucleotide diversities in the study area (Table 1).
Figure 3.

Median-joining haplotype network of common pheasant from the contact zone of Central and Southeast Europe and other common pheasants, based on the analyzed 825-bp fragment of the mtDNA control region. The sizes of the circles reflect the haplotype frequency, and the colours correspond to those of clades on Fig. 2. The groups of haplotypes corresponding to the clades in Fig. 2 are bounded by rectangles with dashed lines. Numbers next to the lines connecting haplotypes are present when the mutational steps separating them are > 1. Small orange circles represent undetected putative haplotypes. The 10 haplotypes found in this study are identified (H1-H10).
Table 1.
Genetic diversity summary statistics and results of neutrality tests and mismatch distribution analyses for clades (or BAPS clusters) B and F in the study area, based on the 825-bp fragment of the mtDNA control region.
| n | h | Hd (SD) | Π (SD) | K | P | Fu’s FS | Tajima's D | SSD | Hri | |
|---|---|---|---|---|---|---|---|---|---|---|
| Clade B | 9 | 3 | 0.417 (0.191) | 0.00108 (0.00062) | 0.8889 | 4 | 0.134 | − 1.609* | 0.025 | 0.255 |
| Clade F | 60 | 7 | 0.192 (0.068) | 0.00041 (0.00019) | 0.3333 | 10 | − 5.411** | − 2.339** | 0.001 | 0.482 |
| Total | 69 | 10 | 0.381 (0.073) | 0.00322 (0.00076) | 2.640 | 20 | − 0.155 | − 1.112 | 0.021 | 0.320 |
n number of samples, h number of haplotypes, Hd haplotype diversity, π nucleotide diversity, K mean number of nucleotide differences, P variable sites, SD standard deviation, SSD sum of squared differences in mismatch analysis, Hri Harpending’s raggedness index.
*p < 0.05, significant; **p < 0.01, highly significant.
Population structure
The BAPS analysis assigned sequences of common pheasant from the study area to two clusters, where sequences belonging to each mitochondrial clade (B and F) fell into a distinct cluster (Figure S1). The AMOVA estimated that 96.07% of the mtDNA variation in the study area is due to the differentiation between the two populations (p < 0.0001) and, accordingly, the FST fixation index was extremely high (Table 2).
Table 2.
AMOVA of the mtDNA variation in the study area taking into account the genetic structure represented by the two detected clusters (B and F).
| Source of variation | d.f | Percentage of variation | Fixation index | p-value |
|---|---|---|---|---|
| Among populations | 1 | 96.07 | FST = 0.9607 | p < 0.000 |
| Within populations | 67 | 3.94 | ||
| Total | 68 |
Demographic analyses and neutrality tests
The EBSP indicated an increase in maternal effective population sizes for both detected clusters (B and F) since approximately the last 10,000 years (Fig. 4). The mismatch distribution analysis indicated a unimodal distribution for both clusters B and F (Fig. 4), fitting to the sudden expansion model. The sums of squared differences (SSD) and raggedness indices (Hri) were not significant (P > 0.05) in any of the cases (Table 1), also supporting population expansion for the population. The values of the Tajima’s D and Fu’s FS statistics were mostly negative for the clusters B and F and total sequences in the study area (Table 1), indicating, respectively, an excess of rare nucleotide variants and of rare haplotypes relative to those expected under mutation-drift equilibrium. While both tests were significant for clade F, only the Tajima's test was significant for clade B.
Figure 4.

Above: Extended Bayesian skyline plot indicating demographic size changes in the mitochondrial genetic clusters B (a) and F (b) of the common pheasant from the contact zone of Central and Southeast Europe. Time is given in units of millions of years before present. The central dotted line represents the median value of effective population size, and solid lines indicate the 95% highest posterior density (HPD) interval. Below: Mismatch distributions of the genetic clusters B (c) and F (d). The solid red curves represent the frequencies of the observed pairwise differences and dotted black lines indicate the expected distributions under a sudden expansion model.
Microsatellite analysis
Hardy–Weinberg and linkage disequilibrium tests
Of the 10 loci, we did not include the results for two of them in the data set for analysis because one (PC5) was monomorphic and the other (PC1) had a high proportion of missing data. The global test indicated significant deviations from HWE after Bonferroni correction (P values < 0.0009) and heterozygote deficit in three loci (PC4, PC7, and PC10). However, in separate tests for each of the two countries, these three loci showed significant deviation from HWE and heterozygote deficit only for Serbia, not for Hungary. This suggests that the data for these loci may not be affected by intrinsic problems, such as null alleles or allelic dropout, but that the significant test results in Serbia may be due to underlying genetic structure (Wahlund effect). Accordingly, estimates of the frequency of null alleles at these loci were generally small (< 0.2; Table S2). We therefore retained these loci in the data set. No signs of significant linkage disequilibrium between loci were detected after Bonferroni correction, both in the global test and in the analyses separately by country.
Genetic structure and population differentiation
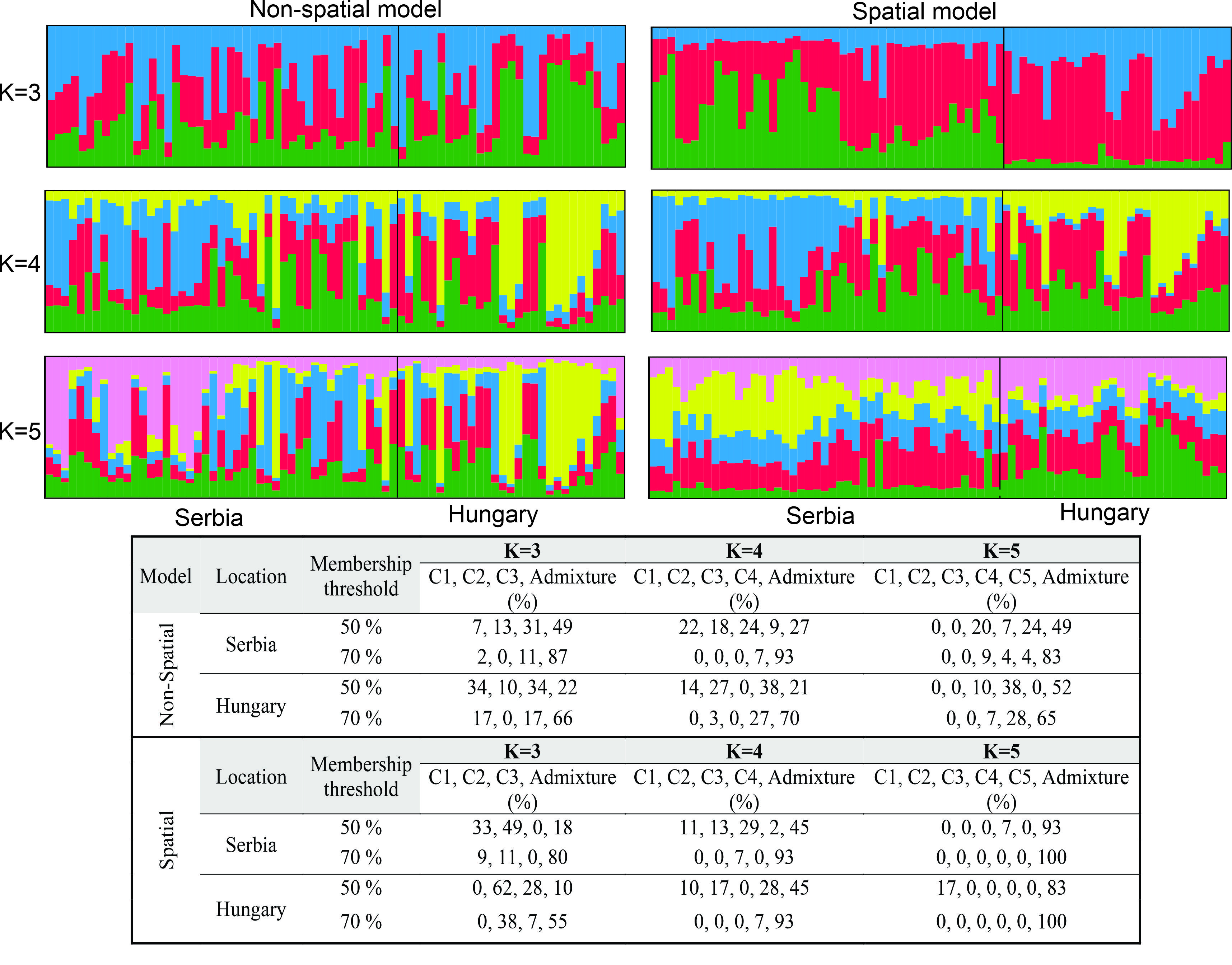
In the STRUCTURE analysis, both LnP(D) and ΔK suggested the presence of two genetic clusters (K = 2) with either the model with prior information on the sampling location of individuals or the non-spatial model (Fig. 5). With the model using information on sampling location and applying a membership probability threshold of 50%, all Hungarian samples grouped in the same cluster, whereas in Serbia the individuals were approximately divided equally into each cluster (53% in the same cluster as the Hungarians, and 47% in the other). When applying a stricter threshold of 70%, the results for the Hungarian samples were the same as for the 50% threshold, while most Serbian samples (64%) could not be assigned to any cluster (of the remaining 36%, 18% were assigned to one cluster and 18% to the other). The analyses using the non-spatial model did not detect any clear geographic structure in the data. Specifically, considering the 50% threshold for cluster membership, 55% of the Hungarian samples and 53% of the Serbian samples were assigned to the same cluster, with the remaining 45% and 47%, respectively, grouping into the other cluster. With a threshold of 70%, 73% of the Hungarian samples and 76% of the Serbian samples had intermediate assignment probabilities to both clusters. As a great number of Serbian samples were not assigned to any of the two clusters in both spatial and non-spatial models, we studied cluster membership probabilities for models with more than two clusters to understand admixture patterns and fine-scale genetic structuring. However, the spatial models with K > 2 (K = 3, 4, and 5) and membership threshold of 70% showed that none of the admixture Serbian samples identified with K = 2 were assigned to a specific cluster, confirming the absence of discrete subpopulations whthin Serbian samples and high degree of admixture (Figure S2).
Figure 5.
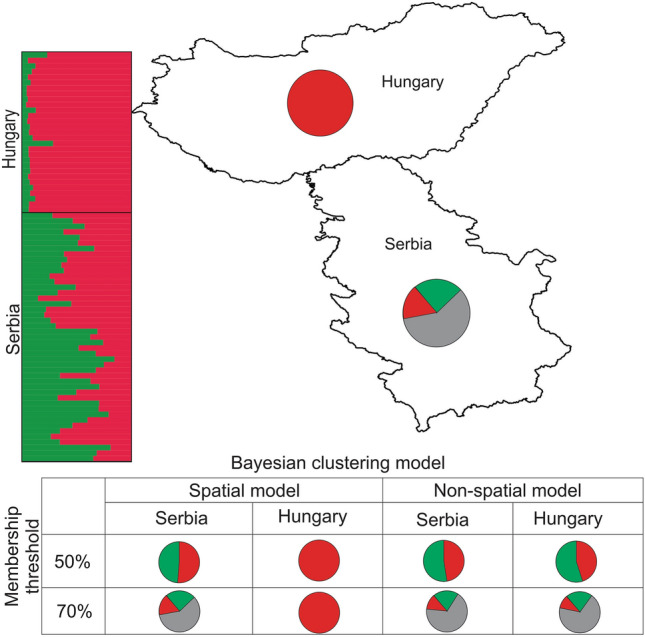
STRUCTURE assignment of common pheasant individuals into two (K = 2) genetic clusters. The bar plot on the left and the pie chart in each country refer to the analyses using information on sampling location and the membership probability threshold of 70%. In the bar plots, each individual is depicted by a column that is partitioned into K segments, which length is proportional to the membership coefficient of the individual for each cluster. Grey in the pie charts represents the percent of individuals that could not be assigned to any cluster. The results of non-spatial model and the membership probability threshold of 50% is given in the attached table. Map
source: ESRI. The map was generated using ArcGIS 10.4.1 by ESRI (available online at: http://www.esri.com/).
The Bayesian spatial clustering of individuals performed in BAPS also supported the presence of two clusters (K = 2) as the most likely (Fig. 6). Most of the samples from Hungary were allocated to one cluster (shown in green) while the majority of samples from Serbia grouped in the other cluster (in red). The MEMGENE analysis identified two significant variables (Fig. 7). The first (MEMGENE1) suggests a significant genetic structure that mostly corresponds to a differentiation between the common pheasant populations in Hungary and Serbia (Fig. 7a). The second (MEMGENE2) supports the pattern of genetic differentiation between Hungary and Serbia suggested by MEMGENE1, and indicates the presence of genetic mixture in Serbia, which, in turn, appears to be essentially absent in Hungary (Fig. 7b). The estimated amount of genetic structure explained by spatial patterns was modest (R2adj = 0.072), indicating that much of the spatial genetic pattern can be explained by IBD.
Figure 6.

Bayesian spatial clustering of individuals in BAPS for K = 2. The figure shows a Voronoi tessellation of the distribution of sample locations in the study area), in which the tessellation cells are coloured according to cluster membership of samples.
Figure 7.

The results of the first two MEMGENE variables (a MEMGENE1, b MEMGENE2) for 74 common pheasants in Hungary and Serbia. Circles of similar size and colour indicate individuals with similar scores (large black and white circles describe opposite extremes on the MEMGENE axes). Map
source: ESRI. The map was generated using ArcGIS 10.4.1 by ESRI (available online at: http://www.esri.com/).
The spatial autocorrelation analysis showed significant coefficients (p < 0.01) for the smallest distance class (i.e. 0–50 km; Fig. 8), suggesting an IBD pattern at this spatial scale. A marginally significant positive correlation was also found in the distance class 140–155 km, and no other significant positive correlation was detected in the remaining distance classes. The Mantel test indicated the presence of a modest global pattern of IBD (r = 0.136; p = 0.0004; upper limit of a 95% confidence interval = 0.219. Contraty to the global pattern of IBD in the whole dataset, we didn’t find a significant relation between geographic and genetic distance in the Serbian samples (r = 0.078; p = 0.081).
Figure 8.

Correlogram of the autocorrelation coefficient r. r is a measure of the genetic similarity between pairs of individuals falling within a given distance class. The red dashed lines represent the 95% confidence envelope for the hypothesis of no spatial genetic structure as determined by permutation. The error bars show the 95% confidence intervals about r obtained by bootstrapping.
Genetic diversity and bottleneck tests
Across all individuals, a total of 68 alleles were detected, with the number of alleles per locus ranging from four to 19 (mean 8.5), and the mean number of effective alleles, HO and HE were 3.82, 0.580 and 0.651, respectively (Table 3). Estimates of the different genetic diversity parameters were generally similar between the two countries. The most notable differences were in the number of private alleles, which were almost double in Serbia (although it also should be noted that more Serbian samples were analyzed), whereas heterozygosity was higher in Hungary (Table 3).
Table 3.
Summary statistics of genetic diversity for all samples and by country.
| Samples | N | MNA | Ap | AR | NE | HO | HE | PIC | FIS |
|---|---|---|---|---|---|---|---|---|---|
| All | 74 | 8.5 | – | 8.44 | 3.82 | 0.580 | 0.651 | 0.410 | 0.110 |
| Serbia | 45 | 7.62 | 13 | 6.93 | 3.63 | 0.503 | 0.609 | 0.574 | 0.175 |
| Hungary | 29 | 6.87 | 7 | 6.83 | 3.66 | 0.701 | 0.686 | 0.634 | − 0.022 |
N number of samples, MNA mean number of alleles, AP number of private alleles, AR allelic richness, NE mean number of effective alleles, HO heterozygosity observed, HE heterozygosity expected, PIC polymorphic information content, FIS inbreeding coefficient.
Bold numbers indicate significant values after sequential Holm-Bonferroni correction.
No evidence of a recent genetic bottleneck was detected in any of the two data sets analysed (country-level and cluster-level), and under any of the three tested mutation models, based on the Wilcoxon’s signed rank test, except for the cluster 2 (all Hungarian and 53% of Serbian samples) under the IAM (which was significant at α = 0.05). Based on the sign test, the Serbia data set showed evidence of a recent genetic bottleneck only under the SMM (Table S3). Given that for fewer than 20 loci the Wilcoxon’s test may be the most appropriate and powerful, and that the TPM appears to be the most appropriate model for most microsatellites52, overall we interpret these results as indicating absence of a recent bottleneck. Concordantly, the ‘mode-shift’ test in the three data sets always found a normal L-shaped allele frequency distribution.
Discussion
Although several studies have investigated the genetic diversity, population structure and demographic history of the common pheasant across its native range in Asia30,31,43–45, there is a great lack of this kind of information on the populations introduced into Europe. This study provides the first detailed genetic assessment of common pheasants in their introduced European range, particularly in the contact zone of Central and Southeast Europe (Hungary and Serbia), and the results are essential information for the development of effective conservation and management strategies.
Mitochondrial diversity, phylogeography and demographic history
Mitochondrial diversity of common pheasants in the study area is relatively low (Hd = 0.192–0.417, π = 0.00041–0.00108), particularly when compared to that reported for native populations in Asia (e.g.37); Hd = 0.500–1, π = 0.0009–0.0130). The phylogenetic analysis, including both the new control region sequences generated here and those previously published, inferred the same clades already identified in previous studies (e.g.30,31) (Fig. 2). The mitochondrial sequences found in the study area belong to two well-supported clades: B (corresponding to several subspecies groups such as mongolicus, torquatus, and pallasi) and F (corresponding to the colchicus subspecies group)30,31,44.
Notably, clade F is much more frequent and geographically widespread, while clade B is mainly present in Serbia (Fig. 1), where the geographic overlap between the two clades is much more significant. Boev29 proposed that the first common pheasants introduced into Europe were colchicus (as early as 500 AD), and only much later (eighteenth century) other subspecies (mongolicus and torquatus) would have been introduced. Our results, given the much greater frequency and distribution of clade F in the study area, are consistent with the hypothesis that colchicus was long introduced, so that this lineage had ample time and opportunity to spread throughout the region. Haplotype H1 of clade F and haplotype H2 of clade B were the most frequent and widespread in the study area (Fig. 1). This, and the relatively low number of haplotypes found in the study area, when compared for example to the haplotype richness in clade B (Figs. 2 and 3), suggest introductions involving a small number of individuals, followed by demographic and range expansion. The apparently more recent introduction of clade B seems to have so far spread mainly only across Serbia.
The EBSP results indicated that P. colchicus likely experienced a long-term historical expansion based on detected clusters in the study area (Fig. 4). Morever, mismatch distribution analysis suggested evidence for unimodal distribution of the clusters B and F, which is relevant to the panmictic population undergone the sudden expansion model in its evolutionary history53,54. In addition, the results of the Fu’s and Tajima’s mutation-drift equilibrium tests and the star-shaped pattern in the haplotype network support the hypothesis of demographic expansion of clade F (Table 1; Fig. 3). Given the postulated timings of the introductions of the common pheasant in Europe29 and the time scale of the mtDNA mutation rate, this expansion signal likely reflects an older process that took place in the native range, but it is possible that some of the less frequent haplotypes differing by a single mutation from H1 are derived from mutations that occurred after introduction. Our result supporting the hypothesis of historical demographic expansion in the colchicus group is in line with results in Kayvanfar et al.31 and Liu et al.45. Also, we find evidence for the hypothesis of historical demographic expansion for clade B. This hypothesis is suggested for the torquatus group by several previous studies30,31,42,45.
Microsatellite diversity, genetic structure and bottleneck tests
The estimated moderate levels of microsatellite genetic diversity for common pheasants in the study area were similar to those reported for a sample of comparable size containing equal numbers of nine subspecies from China55. Therefore, possible genetic signals in the microsatellite diversity of founder effects associated with introductions (indicated by the relatively low nucleotide and haplotype diversity, Table 156) may have been erased as a result of a combination of factors such as the high mutation rate of microsatellites, rapid population growth, and the genetic enrichment resulting from the mixture of subspecies in the study area (e.g. high number of private alleles in Serbia, Table 3). Accordingly, the patterns of microsatellite variability did not show signs of effects of genetic bottlenecks.
Analyses of the microsatellite data using spatial Bayesian clustering and spatial genetic neighbourhood methods consistently suggested a differentiation between Hungary and Serbia, with the common pheasant population in Hungary being much more genetically homogeneous, while that of Serbia has much more genetic mixture and admixture (Figs. 5, 6, and 7). This cryptic differentiation was not detected using a non-spatial Bayesian clustering model. Therefore, the genetic differentiation between the common pheasant populations of the two countries is shallow. This may be due to gene flow resulting from the mobility of the species, since birds, due to their dispersal abilities, often show less population genetic structure than other vertebrates57–60. A similar pattern of low genetic structure was observed among populations of common pheasant in China55 and of silver pheasant in southern China61. Given that the European range of P. colchicus is larger than the contact zone, it may be worth noting at some point that studying the species at the European range scale may provide deeper insights into the population structure of the species. We found evidence of some influence of isolation-by-distance on the genetic structure. In particular, spatial autocorrelation analyses indicated non-random distribution of genotypes at scales up to 50 km. Further study is needed to investigate the issue of fine-scale genetic structure.
Conservation management implications
An important conclusion from our data, both mitochondrial and nuclear, is the fact that they strongly indicate that releases over time to the present day of captive-bred individuals have apparently not led to the establishment of other lineages/subspecies distinct from clades B and F. Also, the detection of neighborhood size up to a distance of 50 km is of practical relevance for the species’ management. Thus, wildlife management practice has traditionally treated this distance value as the basis for isolating pheasant populations. However, the known home range of common pheasants is much smaller: on average 0.05–0.1 km2 (range of 0.008–0.215 km2), and even less in the breeding season (0.02 km2)62,63. Our results, however, suggest that the scale of the genetic impact of releases of captive-bred individuals may be much larger than could be predicted by game managers based on the typical home range of the species. It has been observed and reported that the common pheasant populations of the two countries in the study area have been declining for the past 30 years. It is then apparent that the intended population reinforcements with captive-bred individuals have not helped to achieve the impact hoped for by wildlife farmers and could not prevent the decline in population size. However, in the absence of reference areas and populations, it is difficult to judge the exact impact of artificial releases. It may have even helped to strengthen natural populations, but at the same time it could only slowed the rate of population decline. But it may also have been negatively affected the population size trend by outbreeding depression, the introduction and faster spread of diseases and parasites due to birds introduced from foreign sources and the larger herd size, the increase in the number of predators and the neglected natural population due to supplementation.The results of this study provide essential information for conservation management, monitoring, and for comparison with future assessments of the genetic status of common pheasant populations in Central and Southeast Europe.
Material and methods
Sample collection and DNA extraction
We collected 74 fresh tissue samples in the contact zone of Central and Southeast Europe (Hungary and Serbia) between 2014 and 2015 (Fig. 1). Figures S3 and S4 show, respectively, wild-born and captive-bred pheasants from Hungary. The samples were obtained from legally hunted pheasants and stored in 96% ethanol. No animals were shot only for the purpose of this study. An ethics statement was not recquired for this work; collection was done in accordance with the countries’ national regulations and under hunting license. Genomic DNA was extracted using Roche High Pure PCR Template Preparation Kit (Roche Life Sciences) following the manufacturer's protocol.
Mitochondrial DNA control region sequencing
A 825-bp fragment of the mitochondrial control region in 69 common pheasants was amplified using the primers PHDL (5’-AGGACTACGGCTTGAAAAGC-3’) and PHDH (5’-CATCTTGGCATCTTCAGTGCC-3’)64. Polymerase chain reactions (PCR) were carried out in a total volume of 25 μL, with the reaction mixture containing 30 to 50 ng of genomic DNA, 10 pmol/L of each primer, 1X PCR buffer (Qiagen, USA), 6.25 mmol/L MgCl2, 2.5 units of Taq polymerase (Qiagen, USA), and 10 pmol/L dNTPs. The PCR conditions were as follows: an initial denaturation at 94 °C for 2 min, followed by 30 cycles of 15 s at 94 °C, 15 s at 55 °C and 1 min at 72 °C, and a final extension for 10 min at 72 °C. PCR products were run on 2% agarose gels, stained with ethidium bromide, and visualized under ultraviolet (UV) light. PCR product purification and sequencing were carried out by Macrogen Europe. Sequences were assembled using SeqScape v.2.6 (Applied Biosystems) and aligned with ClustalW in MEGA 6.065. The substitution saturation was examined in DAMBE 666.
Microsatellite genotyping
Ten microsatellite loci (Table S4), previously developed for P. colchicus by Wang et al.55, were used to genotype 74 individuals from the study area. The PCRs consisted of 12.5 μL of Multiplex PCR Master Mix (QIAGEN), 0.3 μL of each primer (10 pmol/μL), 1 μL genomic DNA (15 ng/μL), and sterile water up to a final volume of 25 μL. Thermal cycling consisted of a 5 min initial denaturation at 95 °C, followed by 35 cycles consisting of denaturation at 94 °C for 30 s, annealing at 58 °C for 45 s, and extension at 72 °C for 1.5 min, and then a final extension at 72 °C for 10 min. The forward primers were labelled at the 5′ end with either 6-FAM, VIC, NED or PET fluorescent dyes (Table S4). Fragment analysis was performed on an ABI 3730XL DNA Analyser (Applied Biosystems). Genotypes were determined using Peak Scanner v1.0 (Applied Biosystems).
Mitochondrial DNA analysis
Genetic diversity and phylogenetic analyses
New sequences in the present study were combined with 202 GenBank sequences from previous studies (Table S1) to yield a dataset in order to estimate the phylogenetic relationships among common pheasants across the species range. The number of haplotypes, haplotype diversity (Hd), nucleotide diversity (π), and the number of polymorphic sites (P) were calculated using DnaSP 5.10.167. The best-fit models of nucleotide substitution were selected using jModeltest 0.1.168 under the corrected Akaike Information Criterion (AICc) and the Bayesian Information Criterion (BIC). IQ-TREE 1.6.1269 was used to infer a maximum likelihood (ML) tree under a HKY + I + G model70, and clade support was assessed using 10,000 bootstrap replicates. BEAST 2.6.471 was used to reconstruct a Bayesian inference (BI) tree under a HKY + I + G model, based on 40 million generations of Markov Chain Monte Carlo (MCMC) chains and sampling every 100 generations. Three sequences of the green pheasant (Phasianus versicolor) (GenBank accession numbers AY376861, AY376862 and AY376863) (Zhan and Zhang, unpublished) were included as outgroups. A median-joining network72, estimated in Network 10.0 (available at: http://www.fluxus-engineering.com), was used to infer and visualize possible genealogical relationships among haplotypes.
Population structure
We used the Bayesian model-based clustering algorithm implemented in BAPS 6.0 (Bayesian Analysis of Population Structure)73, to estimate the presence of mitochondrial genetic clusters within the new sequences of P. colchicus. BAPS was run setting the method of ”clustering for linked loci” with two independent runs, and the maximum number of clusters (K) to 10. To examine genetic differentiation among clusters, analysis of molecular variance (AMOVA) and fixation indexes (FST) were calculated using Arlequin 3.5.2.274 with 10,000 permutations to test for significance.
Demographic analyses and neutrality tests
We constructed extended Bayesian skyline plots (EBSPs)75 in BEAST 2.6.471 to explore the demographic dynamics of detected population of the common pheasant in the study area (clusters B and F detected by BAPS). The latter analyses were conducted using a HKY substitution model, a strict clock model, and the coalescent extended Bayesian skyline as tree prior. The MCMC chain was set to a total 400 million generations, and the Markov chain was sampled every 10,000 steps. Tracer was used to assess the convergence and stationarity of the EBSP values, and whether the effective sample sizes (ESS) were > 200. We performed multiple replicate runs to ensure MCMC convergence. EBSPAnalyzer 2.5.271 was employed to construct the EBSPs. We used R 3.1.276 to generate the visualizations.
Mismatch distribution analyses were used to examine demographic expansions in detected population clusters. To compare observed distributions with expected distributions under the expansion model, we estimated sums of squared deviations (SSD) and Harpending's raggedness index (RI) in Arlequin. Morever, we used the tests of Fu’s FS77 and Tajima’s D78, computed in Arlequin to test equilibrium of the population. A negative value of these statistics signify an excess of low frequency polymorphisms, and suggests a population size expansion and/or purifying selection of a population78. When we detect more than one distinct population cluster in the BAPS analysis, we carried out the EBSP analyses, mismatch distribution and neutrality tests for each cluster separately.
Microsatellite analysis
Hardy–Weinberg and linkage disequilibrium tests
We used exact tests in Genepop 4.279 to test loci for Hardy–Weinberg equilibrium (HWE) deviations and linkage disequilibrium (LD) between pairs of loci, based on the whole dataset and separately for each region (Hungary and Serbia). Probability values were assessed for significance using sequential Bonferroni correction for multiple comparisons and a nominal significance value of 0.0580.
Genetic structure and population differentiation
We used STRUCTURE 2.3.481 to investigate the likely number of genetic clusters (K) in the study area. STRUCTURE was run using the admixture ancestry model, correlated allele frequencies, K from 1 to 5, 10 independent simulations for each K, 100,000 iterations as burn-in, and 1,000,000 iterations for sampling. We conducted Bayesian clustering with (i.e. LOCPRIOR model; assuming two geographic populations; (Serbia and Hungary)82) and without prior information on sampling locations. We used STRUCTURE HARVESTER83 to process and visualize results from STRUCTURE, and we determined the most likely value of K based on the log probability of the data (Ln P(D)) and the ΔK statistic84. The membership probabilities (Q-values) were used to assign individuals to clusters considering a membership threshold of either 50% or 70% (e.g.85,86). CLUMPP 1.1.287 and DISTRUCT 1.188 were used to average the membership probabilities over the 10 runs for each K and to plot the results, respectively. The number of genetic clusters present in the study area and the degree of admixture between them was also investigated using the spatial mixture model in BAPS 673,89. We tested K values from 1 to 5, and subsequently performed a separate analysis in the ‘fixed K’ mode with K = 2. Additionally, we used MEMGENE 1.0.190 to complement the analyses with STRUCTURE and BAPS and to visualize spatial genetic neighbourhoods. MEMGENE performs a spatially explicit ordination technique free of linkage and Hardy-¬Weinberg equilibria assumptions; in particular it uses Moran’s Eigenvector Maps (MEM) to detect weak genetic structure90. Spatial autocorrelation analyses were used to detect fine-scale patterns of genetic structure across the study area8,91,92. We divided the individuals into 22 geographic distance classes of equal sample size. A correlation coefficient r between geographic and genetic distance was calculated among individuals in each class. Significance tests were performed using 10,000 permutations to test the null hypothesis of no spatial autocorrelation. Confidence intervals around the estimates of r were determined using bootstrapping with 10,000 replicates. The results were plotted in a correlogram. Finally, we used the Mantel test within the R package Vegan version 2.5-793 to assess the hypothesis of isolation-by-distance (IBD)94. For this, we calculated genetic and log-transformed geographic distances among all pairs of individuals in GenAlEx 6.595. A total of 10,000 replicates were used to determine the significance of the test relative to the 95% quantile of the distribution of permutations.
Genetic diversity and bottleneck tests
We quantified genetic diversity using basic genetic variation statistics, including observed (HO) and expected (HE) heterozygosity, mean number of alleles (MNA), allelic richness (AR), effective number of alleles (NE), private allele frequency (AP), and polymorphic information content (PIC). The estimates and 95% confidence intervals were obtained for the total sample and separately for each country (Hungary and Serbia) using GenAlEx, FSTAT v.2.9.3.296, and POPGENE 1.3297. The inbreeding coefficient (FIS) was estimated using GENETIX4.0598 and the significance of values was evaluated based on 10,000 permutations. BOTTLENECK v1.2.026952 was used to test for evidence of recent bottlenecks in effective population size at two levels including cluster-level (STRUCTURE-inferred clusters based on the spatial model and membership probability threshold of 50%) and country-level (Hungary and Serbia). We ran BOTTLENECK using 1000 iterations and three different mutation models: the infinite alleles model (IAM), the stepwise mutation model (SMM), and the two-phase model (TPM; variance for TPM = 12% and proportion of SSM in TPM = 95%, following recommendations of Piry et al.52 for microsatellites). The statistical tests applied in BOTTLENECK were the Wilcoxon signed-rank test99, sign test, and the ‘mode-shift’ indicator100.
Supplementary Information
{kind=link}
{kind=link}
Acknowledgements
The authors are grateful to all hunters and managers participating in sample collection. Ethics statement was not required. Authors would like to acknowledge the support from EU Framework Horizon 2020 through the COST Action 18134 ‘Genomic Biodiversity Knowledge for Resilient Ecosystems’-GBIKE. C. Aguayo was supported by Tempus Public Foundation within the Stipendium Hungaricum Programme and by the Ecuadorian Goverment through the Institute for Promotion of Human Talent. C. Fernandes thanks the support of cE3c through an assistant researcher contract (FCiência.ID contract #366) and FCT (Fundação pa-ra a Ciência e a Tecnologia) for Portuguese National Funds attributed to cE3c within the strategic project UID/BIA/00329/2020; C. Fernandes also thanks FPUL for a contract of invited assistant professor.
Author contributions
Conceptualization, Sz.K.; Methodology, M.R.A., R.K., C.F., Sz.K.; Formal Analysis, M.R.A. and R.K.; Investigation, Sz.K. C.A., Z.B. B.M.; Resources, Sz.K; L.Sz.; V.L., D.B.; Data Curation, Sz.K., C.A., B.M.; Writing—original draft preparation, M.R.A., R.K., C.F., Sz.K.; Writing—review and editing, M.R.A., R.K., C.F., Sz.K.; Visualization, M.R.A., R.K., C.F., Sz.K.; Supervision, Sz.K.; Funding, Sz.K.; Acquisition, Sz.K. All authors have read and agreed to the published version of the manuscript.
Data availability
All haplotypes are available from the Genbank database (accession number (s) KY474094- KY474103 for the mtDNA control region.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-021-00567-1.
References
- 1.Frankham R, Ballou JD, Briscoe DA. Introduction to Conservation Genetics. Cambridge University Press; 2002. p. 617. [Google Scholar]
- 2.Spielman D, Brook BW, Frankham R. Most species are not driven to extinction before genetic factors impact them. PNAS. 2004;101:15261–15264. doi: 10.1073/pnas.0403809101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ahmadi M, et al. Evolutionary applications of phylo-genetically-informed ecological niche modelling (ENM) to explore cryptic diversification over cryptic refugia. Mol. Phylogenet. Evol. 2018;127:712–722. doi: 10.1016/j.ympev.2018.06.019. [DOI] [PubMed] [Google Scholar]
- 4.Ashrafzadeh MR, et al. Large-scale mitochondrial DNA analysis reveals new light on the phylogeography of Central and Eastern-European Brown hare (Lepus europaeus Pallas, 1778) PLoS ONE. 2018;13:e0204653. doi: 10.1371/journal.pone.0204653. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Tóth B, et al. Genetic diversity and structure of common carp (Cyprinus carpio L.) in the Centre of Carpathian Basin: Implications for conservation. Genes. 2020;11:1268. doi: 10.3390/genes11111268. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Broquet T, Ray N, Petit E, Fryxell JM, Burel F. Genetic isolation by distance and landscape connectivity in the American marten (Martes americana) Landsc. Ecol. 2006;21:877–889. doi: 10.1007/s10980-005-5956-y. [DOI] [Google Scholar]
- 7.Cushman SA, McKelvey KS, Hayden J, Schwartz MK. Gene flow in complex landscapes: testing multiple hypotheses with causal modeling. Am. Nat. 2006;168:486–499. doi: 10.1086/506976. [DOI] [PubMed] [Google Scholar]
- 8.Khosravi R, et al. Effect of landscape features on genetic structure of the goitered gazelle (Gazella subgutturosa) in Central Iran. Conserv. Genet. 2018;19:323–336. doi: 10.1007/s10592-017-1002-2. [DOI] [Google Scholar]
- 9.Adavodi R, Khosravi R, Cushman SA, Kaboli M. Topographical features and forest cover influence landscape connectivity and gene flow of the Caucasian pit viper, Gloydius caucasicus (Nikolsky, 1916), Iran. Landsc. Ecol. 2019;34:2615–2630. doi: 10.1007/s10980-019-00908-6. [DOI] [Google Scholar]
- 10.Moussy C, et al. Migration and dispersal patterns of bats and their influence on genetic structure. Mammal Rev. 2013;43:183–195. doi: 10.1111/j.1365-2907.2012.00218.x. [DOI] [Google Scholar]
- 11.Theodoridis S, et al. Evolutionary history and past climate change shape the distribution of genetic diversity in terrestrial mammals. Nat. Commun. 2020;11:1–11. doi: 10.1038/s41467-020-16449-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Barilani M, et al. Detecting introgressive hybridisation in rock partridge populations (Alectoris graeca) in Greece through Bayesian admixture analyses of multilocus genotypes. Conserv. Genet. 2007;8:343–354. doi: 10.1007/s10592-006-9174-1. [DOI] [Google Scholar]
- 13.Randi E. Detecting hybridization between wild species and their domesticated relatives. Mol. Ecol. 2008;17:285–293. doi: 10.1111/j.1365-294X.2007.03417.x. [DOI] [PubMed] [Google Scholar]
- 14.Kusza S, Ashrafzadeh MR, Tóth B, Jávor A. Maternal genetic variation in the northeastern Hungarian fallow deer (Dama dama) population. Mamm. Biol. 2018;93:21–28. doi: 10.1016/j.mambio.2018.08.005. [DOI] [Google Scholar]
- 15.Laikre L, Schwartz MK, Waples RS, Ryman N, GeM Working Group Compromising genetic diversity in the wild: Unmonitored large-scale release of plants and animals. Trends Ecol. Evol. 2010;25:520–529. doi: 10.1016/j.tree.2010.06.013. [DOI] [PubMed] [Google Scholar]
- 16.Söderquist P, et al. Admixture between released and wild game birds: a changing genetic landscape in European mallards (Anas platyrhynchos) Eur. J. Wildl. Res. 2017;63:98. doi: 10.1007/s10344-017-1156-8. [DOI] [Google Scholar]
- 17.Robertson PA, et al. Pheasant release in Great Britain: Long-term and large-scale changes in the survival of a managed bird. Eur. J. Wildlife Res. 2017;63:100. doi: 10.1007/s10344-017-1157-7. [DOI] [Google Scholar]
- 18.Mank JE, Carlson JE, Brittingham MC. A century of hybridization: Decreasing genetic distance between American black ducks and mallards. Conserv. Genet. 2004;5:395–403. doi: 10.1023/B:COGE.0000031139.55389.b1. [DOI] [Google Scholar]
- 19.Blanco-Aguiar JA, et al. Assessment of game restocking contributions to anthropogenic hybridization: The case of the Iberian red-legged partridge. Anim. Conserv. 2008;11:535–545. doi: 10.1111/j.1469-1795.2008.00212.x. [DOI] [Google Scholar]
- 20.Sanchez-Donoso I, et al. Are farm-reared quails for game restocking really common quails (Coturnix coturnix)? a genetic approach. PLoS ONE. 2012;7:e39031. doi: 10.1371/journal.pone.0039031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Liu Y, et al. Genome assembly of the common pheasant Phasianus colchicus: A model for speciation and ecological genomics. Genome Biol. Evol. 2019;11:3326–3331. doi: 10.1093/gbe/evz249. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Braasch T, Pes T, Michel S, Jacken H. The subspecies of the common pheasant Phasianus colchicus in the wild and captivity. Int. J. Galliformes Conserv. 2011;2:6–13. [Google Scholar]
- 23.Robertson DHP, Hill DA. The Pheasant: Ecology, Management and Conservation. Blackwell Scientific Publication; 1988. p. 281. [Google Scholar]
- 24.Hill DA, Robertson P. Hand reared pheasants: how do they compare with wild birds. Game Conserv. Ann. Rep. 1986;17:76–84. [Google Scholar]
- 25.Pfarr J. True Pheasants: A Noble Quarry. Hancock House Publishers Ltd; 2012. p. 248. [Google Scholar]
- 26.BirdLife International. Phasianus colchicus. The IUCN Red List of Threatened Species 2016: e.T45100023A85926819. 10.2305/IUCN.UK.2016-3.RLTS.T45100023A85926819.en
- 27.Ashoori A, et al. Habitat modeling of the common pheasant Phasianus colchicus (Galliformes: Phasianidae) in a highly modified landscape: application of species distribution models in the study of a poorly documented bird in Iran. Eur. Zool. J. 2018;85:372–380. doi: 10.1080/24750263.2018.1510994. [DOI] [Google Scholar]
- 28.Del Hoyo J, Elliott A, Sargatal J. Handbook of the Birds of the World: New World Vultures to Guineafowl. Lynx Edicions; 1994. p. 638. [Google Scholar]
- 29.Boev ZN. Late Pleistocene and Holocene avifauna from three caves in the vicinity of Tran (Pernik District-W Bulgaria) In: Delchev P, Shanov S, Benderev A, editors. Proceedings of the First National Conference on Environment and Cultural Heritage in Karst, Sofia, Bulgaria, 10–12 November 2000. Earth and Man National Museum, Association of Environment and Cultural Heritage in Karst; 2001. [Google Scholar]
- 30.Qu H, et al. Subspecies boundaries and recent evolution history of the common pheasant (Phasianus colchicus) across China. Biochem. Syst. Ecol. 2017;71:155–162. doi: 10.1016/j.bse.2017.02.001. [DOI] [Google Scholar]
- 31.Kayvanfar N, Aliabadian M, Niu X, Zhang Z, Liu Y. Phylogeography of the common pheasant Phasianus colchicus. Ibis. 2017;159:430–442. doi: 10.1111/ibi.12455. [DOI] [Google Scholar]
- 32.Todesco M, et al. Hybridization and extinction. Evol. Appl. 2016;9:892–908. doi: 10.1111/eva.12367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Santilli F, Bagliacca M. Factors influencing pheasant Phasianus colchicus harvesting in Tuscany, Italy. Wildl. Biol. 2008;14:281–287. doi: 10.2981/0909-6396(2008)14[281:FIPPCH]2.0.CO;2. [DOI] [Google Scholar]
- 34.Lavadinović V, Beuković D, Popović Z. Common Pheasant (Phasianus colchicus L.1758) management in Serbia. Contemp. Agric. 2019;68:71–79. doi: 10.2478/contagri-2019-0012. [DOI] [Google Scholar]
- 35.Fenberg PB, Roy K. Ecological and evolutionary consequences of size-selective harvesting: How much do we know? Mol. Ecol. 2008;17:209–220. doi: 10.1111/j.1365-294X.2007.03522.x. [DOI] [PubMed] [Google Scholar]
- 36.Allendorf FW, Hard JJ. Human-induced evolution caused by unnatural selection through harvest of wild animals. PNAS. 2009;106:9987–9994. doi: 10.1073/pnas.0901069106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Darimont CT, et al. Human predators outpace other agents of trait change in the wild. PNAS. 2009;106:952–954. doi: 10.1073/pnas.0809235106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Madden JR, Whiteside MA. Selection on behavioural traits during ‘unselective’harvesting means that shy pheasants better survive a hunting season. Anim. Behav. 2014;87:129–135. doi: 10.1016/j.anbehav.2013.10.021. [DOI] [Google Scholar]
- 39.Csányi S. The effect of hand-reared pheasants on the wild population in Hungary: A modelling approach. Hung. Small Game B. 2000;5:71–82. [Google Scholar]
- 40.Queirós J, Gortázar C, Alves PC. Deciphering anthropogenic effects on the genetic background of the Red deer in the Iberian Peninsula. Front. Ecol. Evol. 2020;8:147. doi: 10.3389/fevo.2020.00147. [DOI] [Google Scholar]
- 41.Giesel JT, Brazeau D, Koppelman R, Shiver D. Ring-necked pheasant population genetic structure. J. Wildl. Manag. 1997;61:1332–1338. doi: 10.2307/3802134. [DOI] [Google Scholar]
- 42.Qu J, Liu N, Bao X, Wang X. Phylogeography of the ring-necked pheasant (Phasianus colchicus) in China. Mol. Phylogenet. Evol. 2009;52:125–132. doi: 10.1016/j.ympev.2009.03.015. [DOI] [PubMed] [Google Scholar]
- 43.Liu Y, Zhan X, Wang N, Chang J, Zhang Z. Effect of geological vicariance on mitochondrial DNA differentiation in Common Pheasant populations of the Loess Plateau and eastern China. Mol. Phylogenet. Evol. 2010;55:409–417. doi: 10.1016/j.ympev.2009.12.026. [DOI] [PubMed] [Google Scholar]
- 44.Zhang L, An B, Backström N, Liu N. Phylogeography-based delimitation of subspecies boundaries in the Common Pheasant (Phasianus colchicus) Biochem. Genet. 2014;52:38–51. doi: 10.1007/s10528-013-9626-5. [DOI] [PubMed] [Google Scholar]
- 45.Liu S, et al. Regional drivers of diversification in the late Quaternary in a widely distributed generalist species, the common pheasant Phasianus colchicus. J. Biogeogr. 2020;47:2714–2727. doi: 10.1111/jbi.13964. [DOI] [Google Scholar]
- 46.Avise JC. Phylogeography: The History and Formation of Species. Harvard University Press; 2000. p. 464. [Google Scholar]
- 47.Corin SE, Lester PJ, Abbott KL, Ritchie PA. Inferring historical introduction pathways with mitochondrial DNA: the case of introduced Argentine ants (Linepithema humile) into New Zealand. Divers. Distrib. 2007;13:510–518. doi: 10.1111/j.1472-4642.2007.00355.x. [DOI] [Google Scholar]
- 48.Oskarsson MC, et al. Mitochondrial DNA data indicate an introduction through Mainland Southeast Asia for Australian dingoes and Polynesian domestic dogs. Proc. R. Soc. B. 2012;279:967–974. doi: 10.1098/rspb.2011.1395. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Garrett LJ, et al. Spatio-temporal processes drive fine-scale genetic structure in an otherwise panmictic seabird population. Sci. Rep. 2020;10:1–12. doi: 10.1038/s41598-019-56847-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Brito PH. Contrasting patterns of mitochondrial and microsatellite genetic structure among Western European populations of tawny owls (Strix aluco) Mol. Ecol. 2007;16:3423–3437. doi: 10.1111/j.1365-294X.2007.03401.x. [DOI] [PubMed] [Google Scholar]
- 51.Suárez NM, et al. Phylogeography and genetic struc-ture of the Canarian common chaffinch (Fringilla coelebs) inferred with mtDNA and microsatellite loci. Mol. Phylogenet. Evol. 2009;53:556–564. doi: 10.1016/j.ympev.2009.07.018. [DOI] [PubMed] [Google Scholar]
- 52.Piry S, Luikart G, Cornuet JM. Computer note. BOTTLENECK: A computer program for detecting recent reductions in the effective size using allele frequency data. J. Hered. 1999;90:502–503. doi: 10.1093/jhered/90.4.502. [DOI] [Google Scholar]
- 53.Rogers AR, Harpending H. Population growth makes waves in the distribution of pairwise genetic differences. Mol. Biol. Evol. 1992;9:552–569. doi: 10.1093/oxfordjournals.molbev.a040727. [DOI] [PubMed] [Google Scholar]
- 54.Slatkin M, Hudson RR. Pairwise comparisons of mitochondrial DNA sequences in stable and exponentially growing populations. Genetics. 1991;129:555–562. doi: 10.1093/genetics/129.2.555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Wang B, et al. Development and characterization of novel microsatellite markers for the Common Pheasant (Phasianus colchicus) using RAD-seq. Avian Res. 2017;8:4. doi: 10.1186/s40657-017-0060-y. [DOI] [Google Scholar]
- 56.Grant WAS, Bowen BW. Shallow population histories in deep evolutionary lineages of marine fishes: Insights from sardines and anchovies and lessons for conservation. J. Hered. 1998;89:415–426. doi: 10.1093/jhered/89.5.415. [DOI] [Google Scholar]
- 57.Barrowclough GF, Johnson NK, Zink RM. In: Current Ornithology. Johnston RF, editor. Springer; 1985. pp. 135–154. [Google Scholar]
- 58.Zink RM. Phylogeographic studies of North American birds. In: Mindell DP, editor. Avian Molecular Evolution and Systematics. Academic Press; 1997. pp. 301–324. [Google Scholar]
- 59.Payne RB. Natal dispersal and population structure in a migratory songbird, the Indigo Bunting. Evolution. 1991;45:49–62. doi: 10.1111/j.1558-5646.1991.tb05265.x. [DOI] [PubMed] [Google Scholar]
- 60.Stenzel LE, et al. Long-distance breeding dispersal of snowy plovers in western North America. J. Anim. Ecol. 1994;63:887–902. doi: 10.2307/5266. [DOI] [Google Scholar]
- 61.Zhu C, et al. Genetic structure and population dynamics of the silver pheasant (Lophura nycthemera) in southern China. Turk. J. Zool. 2020;44:31–43. doi: 10.3906/zoo-1909-45. [DOI] [Google Scholar]
- 62.Faragó S. Élőhelyfejlesztés az Apróvad-Gazdálkodásban: A Fenntartható Apróvad-Gazdálkodás Környezeti Alapjai. Mezőgazda Kiadó; 1997. p. 341. [Google Scholar]
- 63.Faragó S, Náhlik A. A Vadállomány Szabályozása: A Fenntartható Vadgazdálkodás Populációökológiai Alapjai. Mezőgazda kiadó; 2011. p. 347. [Google Scholar]
- 64.Randi E, Lucchini V. Organization and evolution of the mitochondrial DNA control region in the avian genus Alector-is. J. Mol. Evol. 1998;47:449–462. doi: 10.1007/PL00006402. [DOI] [PubMed] [Google Scholar]
- 65.Tamura K, Stecher G, Peterson D, Filipski A, Kumar S. MEGA6: molecular evolutionary genetics analysis version 6.0. Mol. Biol. Evol. 2013;30:2725–2729. doi: 10.1093/molbev/mst197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Xia X. DAMBE6: New tools for microbial genomics, phylogenetics, and molecular evolution. J. Hered. 2017;108:431–437. doi: 10.1093/jhered/esx033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Librado P, Rozas J. DnaSP v5: A software for comprehensive analysis of DNA polymorphism data. Bioinformatics. 2009;25:1451–1452. doi: 10.1093/bioinformatics/btp187. [DOI] [PubMed] [Google Scholar]
- 68.Posada D. jModelTest: Phylogenetic model averaging. Mol. Biol. Evol. 2008;25:1253–1256. doi: 10.1093/molbev/msn083. [DOI] [PubMed] [Google Scholar]
- 69.Nguyen LT, Schmidt HA, Von Haeseler A, Minh BQ. IQ-TREE: a fast and effective stochastic algorithm for estimating maximum-likelihood phylogenies. Mol. Biol. Evol. 2015;32:268–274. doi: 10.1093/molbev/msu300. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Hasegawa M, Kishino H, Yano TA. Dating of the humanape splitting by a molecular clock of mitochondrial DNA. J. Mol. Evol. 1985;22:160–174. doi: 10.1007/BF02101694. [DOI] [PubMed] [Google Scholar]
- 71.Bouckaert R, et al. BEAST 2: A software platform for Bayesian evolutionary analysis. PLoS Comput. Biol. 2014;10:e1003537. doi: 10.1371/journal.pcbi.1003537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Bandelt HJ, Forster P, Röhl A. Median-joining networks for inferring intraspecific phylogenies. Mol. Biol. Evol. 1999;16:37–48. doi: 10.1093/oxfordjournals.molbev.a026036. [DOI] [PubMed] [Google Scholar]
- 73.Corander J, Marttinen P, Sirén J, Tang J. Enhanced Bayesian modelling in BAPS software for learning genetic struc-tures of populations. BMC Bioinform. 2008;9:1–14. doi: 10.1186/1471-2105-9-539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Excoffier L, Lischer HE. Arlequin suite ver 3.5: A new series of programs to perform population genetics analyses under Linux and Windows. Mol. Ecol. Resour. 2010;10:564–567. doi: 10.1111/j.1755-0998.2010.02847.x. [DOI] [PubMed] [Google Scholar]
- 75.Heled J, Drummond AJ. Bayesian inference of population size history from multiple loci. BMC Evol. Biol. 2008;8:289. doi: 10.1186/1471-2148-8-289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Team, R.C . R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; 2014. [Google Scholar]
- 77.Fu YX. Statistical tests of neutrality of mutations against population growth, hitchhiking and background selection. Genetics. 1997;147:915–925. doi: 10.1093/genetics/147.2.915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Tajima F. The effect of change in population size on DNA polymorphism. Genetics. 1989;123:597–601. doi: 10.1093/genetics/123.3.597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Rousset F. Genepop’007: A complete re-implementation of the genepop software for Windows and Linux. Mol. Ecol. Resour. 2008;8:103–106. doi: 10.1111/j.1471-8286.2007.01931.x. [DOI] [PubMed] [Google Scholar]
- 80.Holm S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979;6:65–70. [Google Scholar]
- 81.Pritchard JK, Stephens M, Donnelly P. Inference of population structure using multilocus genotype data. Genetics. 2000;155:945–959. doi: 10.1093/genetics/155.2.945. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Hubisz MJ, Falush D, Stephens M, Pritchard JK. Inferring weak population structure with the assistance of sample group information. Mol. Ecol. Resour. 2009;9:1322–1332. doi: 10.1111/j.1755-0998.2009.02591.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Earl DA. STRUCTURE HARVESTER: A website and program for visualizing STRUCTURE output and implementing the Evanno method. Conserv. Genet. Resour. 2012;4:359–361. doi: 10.1007/s12686-011-9548-7. [DOI] [Google Scholar]
- 84.Evanno G, Regnaut S, Goudet J. Detecting the number of clusters of individuals using the software STRUCTURE: A simulation study. Mol. Ecol. 2005;14:2611–2620. doi: 10.1111/j.1365-294X.2005.02553.x. [DOI] [PubMed] [Google Scholar]
- 85.Langguth T, et al. Genetic structure and phylogeogra-phy of a European flagship species, the white-tailed sea eagle Haliaeetus albicilla. J. Avian Biol. 2013;44:263–271. doi: 10.1111/j.1600-048X.2012.00075.x. [DOI] [Google Scholar]
- 86.Väli Ü, Dombrovski V, Dzmitranok M, Maciorowski G, Meyburg BU. High genetic diversity and low differentia-tion retained in the European fragmented and declining Greater Spotted Eagle (Clanga clanga) population. Sci. Rep. 2019;9:1–11. doi: 10.1038/s41598-019-39187-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Jakobsson M, Rosenberg NA. CLUMPP: A cluster matching and permutation program for dealing with label switching and multimodality in analysis of population structure. Bioinformatics. 2007;23:1801–1806. doi: 10.1093/bioinformatics/btm233. [DOI] [PubMed] [Google Scholar]
- 88.Rosenberg NA. DISTRUCT: A program for the graphical display of population structure. Mol. Ecol. Notes. 2004;4:137–138. doi: 10.1046/j.1471-8286.2003.00566.x. [DOI] [Google Scholar]
- 89.Corander J, Sirén J, Arjas E. Bayesian spatial modeling of genetic population structure. Comput. Stat. 2008;23:111–129. doi: 10.1007/s00180-007-0072-x. [DOI] [Google Scholar]
- 90.Galpern P, Peres-Neto PR, Polfus J, Manseau M. MEMGENE: Spatial pattern detection in genetic distance data. Methods Ecol. Evol. 2014;5:1116–1120. doi: 10.1111/2041-210X.12240. [DOI] [Google Scholar]
- 91.Peakall R, Ruibal M, Lindenmayer DB. Spatial autocorrelation analysis offers new insights into gene flow in the Aus-tralian bush rat, Rattus fuscipes. Evolution. 2003;57:1182–1195. doi: 10.1111/j.0014-3820.2003.tb00327.x. [DOI] [PubMed] [Google Scholar]
- 92.Mullins J, et al. The influence of habitat structure on genetic differentiation in red fox populations in north-eastern Poland. Acta Theriol. 2014;59:367–376. doi: 10.1007/s13364-014-0180-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Oksanen, J. Vegan: R Functions for Vegetation Ecologists. http://cc.oulu.fi/_jarioksa/softhelp/vegan.html. (2005).
- 94.Wright S. Isolation by distance. Genetics. 1943;28:114. doi: 10.1093/genetics/28.2.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Peakall R, Smouse PE. GenAlEx 6.5: Genetic analysis in Excel. Population genetic software for teaching and re-search: An update. Bioinformatics. 2012;28:2537–2539. doi: 10.1093/bioinformatics/bts460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96.Goudet, J. FSTAT, A Program to Estimate and Test Gene Diversities and Fixation Indices, Version 2.9. 3. http://www2.unil.ch/popgen/softwares/fstat.htm (2001).
- 97.Yeh, F. C. et al. POPGENE version 1.32. Computer Program and Documentation Distributed by the Author. http://www.ualberta.ca/~fyeh/popgene.html (accessed on 23 January 2013).
- 98.Belkhir K, Borsa P, Chikhi L, Bonhomme F. Genetix 4.05: WindowsTM Software for Population Genetics. Laboratoire Genome de Populations University of Montpelier II; 1996. [Google Scholar]
- 99.Luikart G, Sherwin WB, Steele BM, Allendorf FW. Usefulness of molecular markers for detecting population bottlenecks via monitoring genetic change. Mol. Ecol. 1998;7:963–974. doi: 10.1046/j.1365-294x.1998.00414.x. [DOI] [PubMed] [Google Scholar]
- 100.Luikart G, Allendorf FW, Cornuet JM, Sherwin WB. Distortion of allele frequency distributions provides a test for recent population bottlenecks. J. Hered. 1998;89:238–247. doi: 10.1093/jhered/89.3.238. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
All haplotypes are available from the Genbank database (accession number (s) KY474094- KY474103 for the mtDNA control region.