
FIGURE 1.
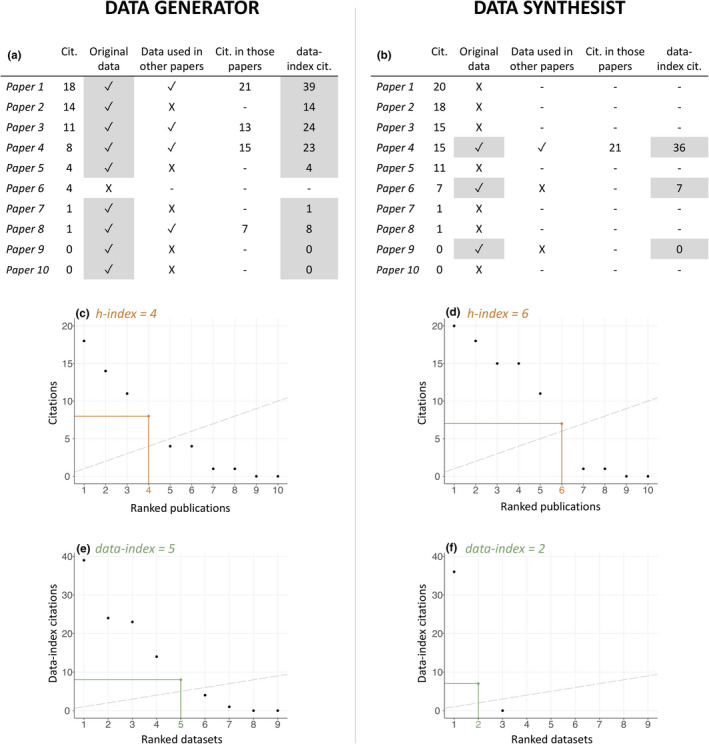
A composite figure with a hypothetical example that shows how the h‐index and data‐index for a data generator (i.e. someone who generates data, e.g. by conducting experiments) and data synthesist (i.e. someone who synthesizes research, e.g. through systematic reviews) at a similar career stage might differ. The h‐index is equal to the number of publications (np ) that have n p or more citations, whereas the data‐index is equal to the number of datasets (nd ) that have nd or more data‐index citations. For both indices, publications or datasets are considered the same whether the author was primary author or coauthor. (a, b) Tables showing example data used to calculate the h‐index and data‐index shown in plots (c–f). (a, b) Papers with original data (highlighted in gray) are the only ones included in the calculation of the data‐index. Scatterplots with (c, d) publications ranked by citations to calculate the h‐index and (e, f) datasets ranked by data‐index citations to calculate the data‐index. Dashed lines show identity lines, and colored lines show the final publication/dataset used to calculate the index value, which is also colored. In this hypothetical example, the data generator has a lower h‐index (4) than the data synthesist (6), but a higher data‐index (6 vs. 2). Cit. is an abbreviation for citation