
FIGURE 2.
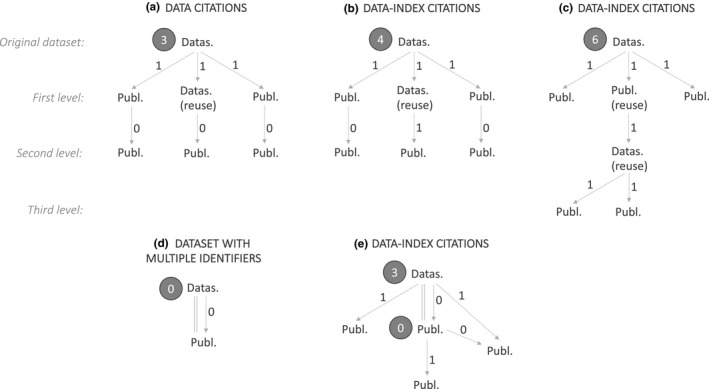
Diagrams showing that (a) data citations are calculated by summing the first‐level citations of a dataset, whereas (b, c) data‐index citations are calculated by summing the first‐level citations of a dataset or publication that contains an original dataset and any higher‐level citations of datasets or publications that have reused data from the original dataset or publication. (d, e) In cases where the same dataset has multiple identifiers (e.g. if the dataset has a unique identifier and a publication describing it has a different unique identifier), existing citation mapping software can be used to automatically group them and therefore avoid the same dataset being double‐counted; parallel lines show datasets and publications that are grouped. Abbreviations are as follows: Datas. = dataset, Publ. = publication, Datas./Publ. (reuse) = dataset or publication that has reused data from the original dataset. Arrows show the direction of citation, and numbers in black show the value this citation gives to calculating the citation score of the original dataset. White numbers in gray circles show the (a) data citation and (b–e) data‐index citation scores of the datasets beside them. Citation levels for (a–c) are shown on the left