
Fig. 3.
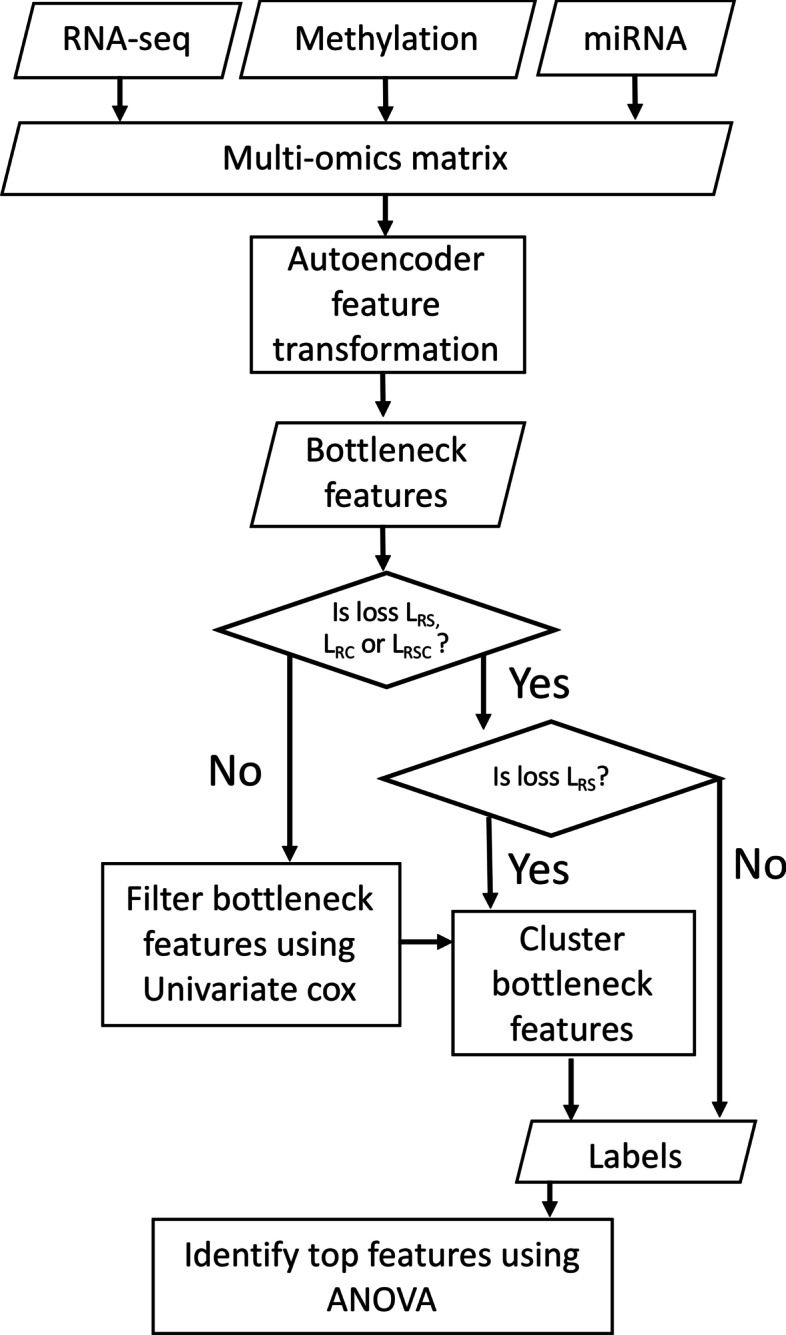
A flowchart of the autoencoder training process. The flowchart demonstrates how multi-omics data is combined into a single matrix, before being transformed by the autoencoder to produce bottleneck features. If the loss is BCE or MSE these bottleneck features are reduced by univariate Cox models as in the baseline before clustering to create group labels. For LRC and LRSC group labels from the final iteration of autoencoder training are used whereas for LRS group labels are derived by clustering all bottleneck features. Using the identified cluster labels the top original omics features are identified for the run using ANOVA