
Fig. 2.
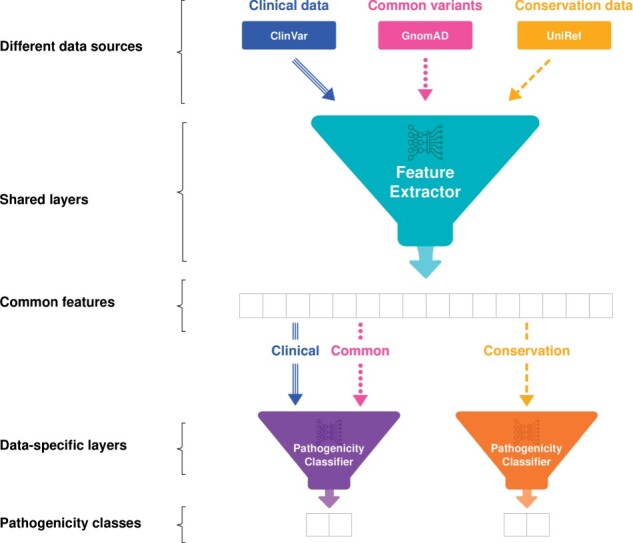
Multi-task learning between clinical data and conservation data. The feature extractor is trained by all data sources, including clinical data from the ClinVar database, common variants from the gnomAD database, and conservation data generated based on the UniRef database. Therefore, the extracted features become common features for different types of data. In contrast, pathogenicity classifiers are separated for specific data types. The clinical data and the common variants are used to train the pathogenicity classifier, while the other pathogenicity classifier is trained by conservation data. After training, the pathogenicity of a variant is determined by the classifier trained by clinical data