
Fig. 1.
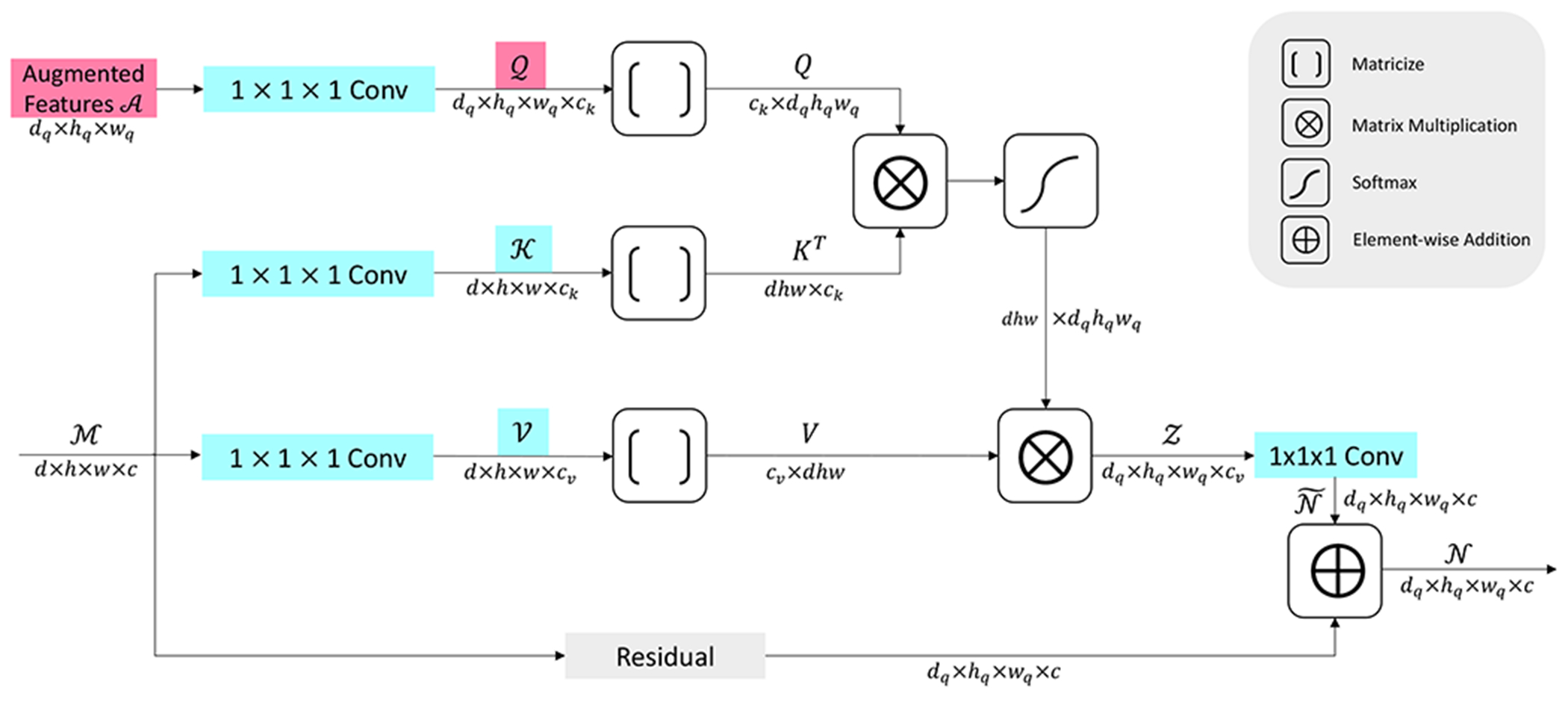
An illustration of the proposed feature augmentor (FA) as detailed in Section III-A. For each operation, the generated tensor/matrix and the dimensions are marked aside the corresponding arrow. The operations for converting tensors back to matrices are not included for simplification. The augmented features tensor contains free parameters and is trained during the whole learning process to capture shared patterns of cleft features. The query tensor is obtained by performing a 1 × 1 × 1 convolution on . The depth, height, and the width of the output tensor are determined by those of or . These dimensions can be flexibly adapted per design requirements. Hence, the proposed FA can replace any commonly-used operation like pooling or deconvolution, and can be integrated to any deep architecture with high flexibility.