

Abstract
Background
The infodemic created by the COVID-19 pandemic has created several societal issues, including a rise in distrust between the public and health experts, and even a refusal of some to accept vaccination; some sources suggest that 1 in 4 Americans will refuse the vaccine. This social concern can be traced to the level of digitization today, particularly in the form of social media.
Objective
The goal of the research is to determine an optimal social media algorithm, one which is able to reduce the number of cases of misinformation and which also ensures that certain individual freedoms (eg, the freedom of expression) are maintained. After performing the analysis described herein, an algorithm was abstracted. The discovery of a set of abstract aspects of an optimal social media algorithm was the purpose of the study.
Methods
As social media was the most significant contributing factor to the spread of misinformation, the team decided to examine infodemiology across various text-based platforms (Twitter, 4chan, Reddit, Parler, Facebook, and YouTube). This was done by using sentiment analysis to compare general posts with key terms flagged as misinformation (all of which concern COVID-19) to determine their verity. In gathering the data sets, both application programming interfaces (installed using Python’s pip) and pre-existing data compiled by standard scientific third parties were used.
Results
The sentiment can be described using bimodal distributions for each platform, with a positive and negative peak, as well as a skewness. It was found that in some cases, misinforming posts can have up to 92.5% more negative sentiment skew compared to accurate posts.
Conclusions
From this, the novel Plebeian Algorithm is proposed, which uses sentiment analysis and post popularity as metrics to flag a post as misinformation. This algorithm diverges from that of the status quo, as the Plebeian Algorithm uses a democratic process to detect and remove misinformation. A method was constructed in which content deemed as misinformation to be removed from the platform is determined by a randomly selected jury of anonymous users. This not only prevents these types of infodemics but also guarantees a more democratic way of using social media that is beneficial for repairing social trust and encouraging the public’s evidence-informed decision-making.
Keywords: infodemiology, misinformation, algorithm, social media, plebeian, natural language processing, sentiment analysis, sentiment, trust, decision-making, COVID-19
Introduction
The internet is a powerful tool for spreading information; as such, it follows that it is equally powerful for spreading misinformation. In 2019, the number of social media users worldwide was 3.484 billion [1], with that number increasing year-by-year by an average of 9% [1,2]. With this increased use, the “power-user” or microinfluencer phenomenon has arisen, where popular social media accounts are able to reach large numbers of readers. This is increasingly important as more people begin to use social media as a source for news [3]. This news comes from a third party by a popular influencer, not posted or moderated by the social media companies themselves. Past analyses examining online misinformation often classify posts as misinformation using a “Point-And-Shoot” algorithm; this is the status quo. However, some algorithms will be better at combating misinformation than others. The Plebeian Algorithm creates criteria that social media websites should take into account when designing their algorithms to reduce misinformation. This reduction of misinformation is thought to be achieved by examining the correlation between sentiment and misinformation; it has been found that posts containing misinformation tend to have more negative sentiment when compared categorically to other posts covering the same issue [4]. Due to this correlation, it is hypothesized that an algorithm that encourages positive interactions will also reduce the amount of misinformation present on the platform through a democratic manner.
Misinformation is a key problem, yet many terms are confused in studies. Herein, the authors shall define several key terms that are often used interchangeably but whose definitions are specific and distinct. First, misinformation shall be defined as the spread, intentional or otherwise, of false information [5]. The intentions of the individuals spreading the information is irrelevant. Second, disinformation is the purposeful spread of false information [5]. A similar yet distinct definition is malinformation, which is the malicious spread of false or misleading information [5]. Finally, fake news is defined as any misinformation (with or without intention) that readers interpret as trustworthy news [5]. For this study, misinformation will be studied in-depth; however, it should be noted that future supplemental studies could conduct a similar investigation focused on disinformation, malinformation, or fake news. Infodemics can additionally be applied to the realm of health care; infodemics have the potential to intensify outbreaks when there is uncertainty among the public concerning evidence-informed preventative and protective health measures [6].
Prior to investigating the spread of misinformation, it is pertinent to define the concept of infodemiology and misinformation. This research paper defines an infodemic according to the World Health Organization (WHO) as “too much information including false or misleading information in digital and physical environments during a disease outbreak,” which “causes confusion and risk-taking behaviours that can harm health [and] also leads to mistrust in health authorities and undermines the public health response” [6]. The study of the spread of infodemics on a large scale, especially pertaining to medical misinformation, is known as infodemiology. The WHO has additionally linked the rapid surge of such infodemics during the COVID-19 pandemic to “growing digitization,” which can support the global reach of information but can also quickly amplify malicious or fabricated messages [6]. The second relevant definition is that of the concept of misinformation, which has been defined similarly to the definition used by the WHO in relation to the infodemic [6], but specifically refers to the distinct lack of verity in information related to a specific field.
At their core, most social media websites aim to maximize the amount of time that users spend on their platforms. This maximization of user page time leads to companies using highly specialized and trained machine learning to advertise content on users’ feeds [7]. At the same time, this can have unintended adverse effects such as maximizing the time a user engages with content that is not verified for accuracy. The proposed solution to this disparity between engagement and integrity is to create democratically moderated spaces. Democratic spaces and recommendations to posts with more positive sentiment are integral concepts in the Plebeian Algorithm, based on the latest evidence that misinformation tends to be more negative [5]. The Plebeian Algorithm is an algorithm, described herein, for the purpose of the control of the spread of misinformation on social media. It is beneficial compared to other existing algorithms, as will become evident. The currently implemented point-and-shoot algorithms are hypertuned to specific sources of misinformation surrounding specific topics. However, they are not adaptable to the fluidity of the definition of true information.
As mentioned earlier, most social media platforms work on a model similar to Twitter, Facebook, or YouTube where content is recommended based on user engagement [7]; however, this is not true to the same extent for all websites. One example of a website that breaks the expectations for social media algorithms is 4chan. 4chan is an excellent epitome of ephemeral social media, where content is completely anonymous and is rapidly discarded regardless of popularity [8]; in addition, there is close to no moderation and the content tends to be more negative in sentiment. This is also exemplified in Parler, an alternative social media platform established in September 2018 that aimed to bring forth a platform with total freedom of speech. Consequently, Parler attracted those who were banned from other social media websites, creating “echo chambers, harbouring dangerous conspiracies and violent extremist groups” [9] such as those who were involved in raiding the US Capitol on January 6, 2021. Reddit also has a forum-based system similar to 4chan. However, individual fora on these platforms have moderators who work to combat negative sentiment throughout the website. Reddit’s issue lies in its incredibly isolated fora, as tailoring one’s feed to be a vast majority of explicitly handpicked fora is a part of the experience; this allows for some fora to have little to no moderation [10].
There have been several related works of research in the field of misinformation detection on social media platforms. These works include studies on the connection between misinformation and cognitive psychology [11], the analysis of geospatial infodemiology [12], the effect of recommendation algorithms on infodemiology [13], the use of distributed consensus algorithms to curb the spread of misinformation [14], and the naming conventions used for viruses [15]. Although these works are in alignment with this study, they do not propose the same solution. The study that offers a solution closest to that proposed by the Plebeian Algorithm discusses the efficacy of curbing the spread of misinformation through layperson judgements [16]. Notably, this work discusses the merits surrounding a layperson algorithm but does not make suggestions for its implementation.
The objective of the study will be to determine the optimal social media algorithm to reduce the spread of misinformation while ensuring personal freedoms. The investigation conducted in this paper will have far-reaching implications that will alter how misinformation in social media platforms is addressed.
The three major implications include:
The creation of a more open and democratic environment on social media platforms
An overall reduction in political divisiveness and extremist sentiment both online and offline
An increase in informed users who can make well-informed opinions on subjects
Methods
A detailed step-based methodology was used to analyze data throughout the research process. Python 3.9 (Python Software Foundation) was the language of choice through all aspects of the project. All libraries used can be accessed using pip. The visualization of data was performed using the matplotlib and seaborn libraries in Python. Application programming interfaces (APIs) were used from Twitter, Reddit, and 4chan, gathering data regarding username, date, post, and text. Furthermore, two data sets were gathered from academic sources, containing post data from Twitter [17] and Parler [9]. Various Python libraries were used to interact and connect with the APIs, including twarc, urllib3, and basc_py4chan. The following Python libraries were used to clean the data: beautifulsoup4, demoji, and pyenchant. The pandas library for Python was used to retrieve and store third-party data sets [8,17-20], and the numpy library was used for various array operations. Finally, the nltk library was used to perform sentiment analysis, and sklearn was used to perform regressions.
Python was selected due to its ease of connectivity to the various APIs; it is well supported among a strong community, and as such, connecting to various APIs was done through prewritten libraries. This reduced the programming time while increasing the efficiency and reliability of the code.
In three of the social media services for which APIs were used (ie, Twitter, Reddit, and 4chan), four steps were performed: (1) gather data using the API and the associated Python library; (2) clean data to create a Python set of strings, containing no URLs (removed using regular expressions), HTML (removed using beautifulsoup4), usernames (removed using regular expressions), emojis (replaced with text using demoji), or non-English language (removed using pyenchant); (3) perform sentiment analysis using nltk’s SentimentIntensityAnalyzer class; and (4) save the cleaned and sentiment analyzed data frame as a pickle file. A visualization script was then programmed to display the sentiment data gathered from the social media post data. To ensure confidentiality of users, only aggregate data was displayed. Plotting a histogram with a kernel density estimation (KDE) resulted in the various graphs produced by the research team. Data for which sentiment analysis returned inconclusive due to textual limitations was removed from visualization. Limiting the language to English has the benefit of statistical comparison congruence. One notable platform that did not use an API is Facebook. The reason for this is due to the restrictions placed on the Facebook API, in terms of depth and breadth of research.
The six social media services analyzed (4chan, Twitter, Parler, Reddit, YouTube, and Facebook) had various amounts of associated data. A breakdown of the data analyzed herein is described in Figure 1.
Figure 1.

Social media data breakdown.
The sentiment analysis dictionary selected for the analysis performed herein is the Valence Aware Dictionary and Sentiment Reasoner (VADER). This dictionary was selected as it is the industry standard for a wide array of general statement analyses and is especially recognized for producing highly accurate results with social media platforms. As such, VADER is the optimal dictionary for the purposes of this research. Although ideal algorithms should implement various checks and balances for the sentiment analysis system implemented, this paper shall focus on strictly the VADER dictionary, which is solely positive and negative sentiment. Other sentiment analysis tools exist to examine specific emotions (including anger, fear, surprise, happiness, etc).
Key term analysis was used for the data cleaning process to determine which strings were classified as relating to a specific topic. The key terms were gathered using a list of the most commonly held terms gathered from Twitter that were directly associated with misinformation.
To confirm the academic literature [5] regarding the correlation between negative sentiment and verity of information, the analysis was performed using Twitter. Data was filtered such that only Tweets containing a set of potentially misinformative keywords were assigned to be assessed using a sentiment analysis. Both were plotted through histogram, and the KDEs were compared (relative to each respective maxima).
Misinformation is directly correlated to negativity. A misinformative post is often negative in sentiment. However, this is not a certainty. As such, when determining an optimal algorithm, it will be critical to use sentiment analysis to narrow the potential misinformative candidates and then to use further methods—a jury process—to accurately detect misinformation.
The study defines several mathematical terms. Many of the histograms and KDEs as previously described form a bimodal distribution. The polarity score upon which the two peaks are centered is termed μ+ and μ–, where the sign indicates whether the term refers to the positive or negative peak. The other variable defined is the skewness of the distribution as a whole, which is described using the symbol γ. When the positive peak is the major mode, then γ ∈ (0, ∞). Contrarily, when the positive peak is the minor mode, then γ ∈ (–∞, 0). The frequency function f describes the frequency curve represented by the KDE (such that f(p) represents the frequency of strings with polarity score p). The skewness is calculated using the following equation:
 |
This equation for skewness was derived using the following derivation:
 |
Results
The results of the analysis will be divided by the social media platform. They will be presented in the following order:
Reddit
4chan
Facebook
YouTube
Parler
Twitter
When analyzing Reddit’s data, a series of subreddits were selected. The subreddits selected were r/AskReddit, r/AskThe_Donald, r/conspiracy, r/covid, r/kindness, r/movies, r/politics, and r/EnoughTrumpSpam. These subreddits were selected as an array of options, allowing an analysis of probable misinformative, probable truthful, and unknown sources. The data was gathered using the Python library urllib3. The first subreddit to be examined herein is r/AskReddit. This subreddit tends to contain a wide variety of posts from a myriad of conversation topics. As such, it is relatively indicative of Reddit overall. r/AskReddit’s histogram can be found in Figure 2. The bimodal distribution was μ–≈–0.54, μ+≈0.48, and γ≈–0.03214.
Figure 2.
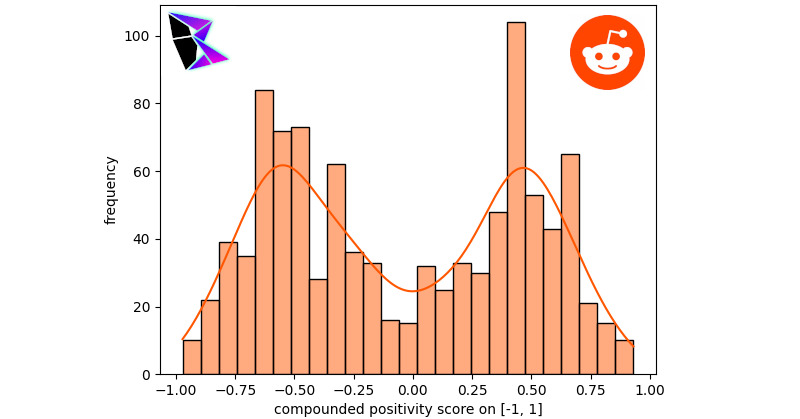
Reddit r/AskReddit frequency of positivity histogram.
It should be noted that the extremal frequencies of the bimodal distribution were approximately equal between the negative and positive peaks. Another notable subreddit examined was r/politics, which provided a sample of posts potentially swayed by the political leaning of Reddit users. The histogram and KDE for this analysis is displayed in Figure 3. The bimodal distribution for r/politics was μ–≈–0.56, μ+≈0.43, and γ≈–0.37776.
Figure 3.

Reddit r/politics frequency of positivity histogram.
r/politics’s content had a stronger negative skew as is apparent by the KDE. The final subreddit to be examined is an avant-garde subreddit: r/conspiracy. In this community, users share various conspiracy theories. When one scrolls through r/conspiracy, plenty of misinformation can easily be noted, including misinformation surrounding Flat Earth Theory and QAnon. The histogram for r/conspiracy is found in Figure 4. The bimodal distribution for r/conspiracy was μ–≈–0.56, μ+≈0.39, and γ≈–0.33904.
Figure 4.
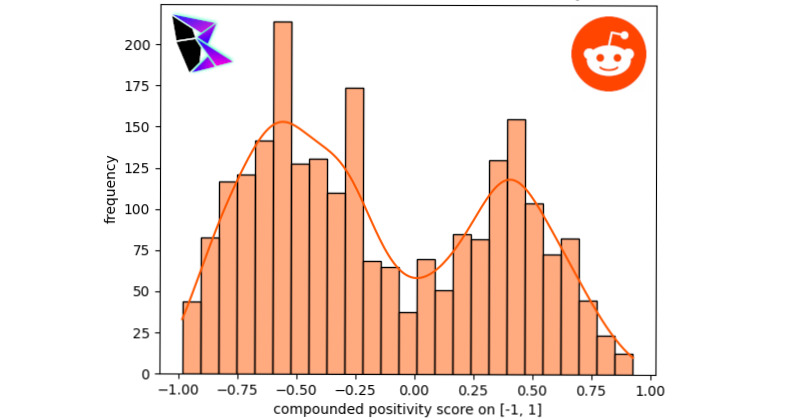
Reddit r/conspiracy frequency of positivity histogram.
As can be noted by r/conspiracy, the conspiratorial posts (which are known to contain a large volume of misinformation) are more often negative. This can be noted due to the difference in the peaks of the bimodal distribution.
4chan
To analyze the 4chan data, five boards were selected: /b/, /a/, /v/, /pol/, and /r9k/. These five boards were selected due to their high post frequency compared to other 4chan boards. The data was gathered using basc_py4chan. For each of these boards, a histogram was plotted (with an overlayed KDE) with 30 bins. A visualization for the histogram for /b/’s sentiment can be found in Figure 5. /b/ is described as the random board, containing a wide mixture of conversation from across 4chan. The bimodal distribution for /b/ was μ–≈–0.55, μ+≈0.46, and γ≈0.11380.
Figure 5.
The 4chan /b/ frequency of positivity histogram.
Another board to be visualized in this report is the visualization for the sentiment of /pol/, which can be found in Figure 6; /pol/ contains political discussion. The bimodal distribution for /pol/ was μ–≈–0.61, μ+≈0.38, and γ≈–0.16559.
Figure 6.
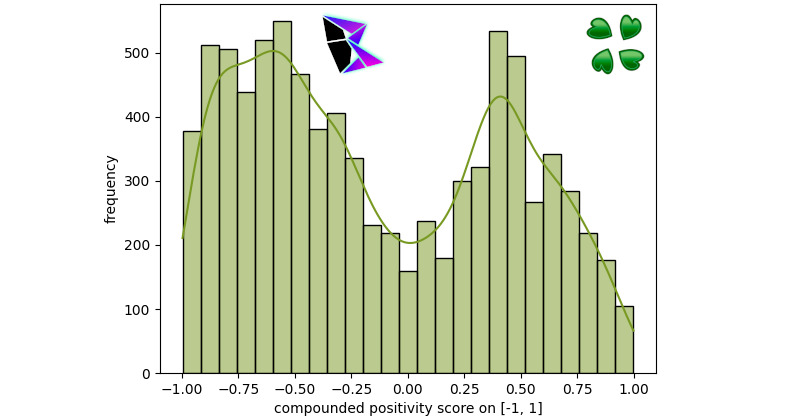
The 4chan /pol/ frequency of positivity histogram.
It should be noted that the levels of extreme negative sentiment (ie, with a polarization score of less than 0.75) are substantially higher in /pol/ compared to /b/. This demonstrates that political topics tend to be more negative on 4chan.
Overall, it should be noted that 4chan consistently contains a large number of negative posts, which is greatly dependent upon the topic of the board. Boards which pertain to specific recreational activities (eg, /v/ for video games or /a/ for anime) have a lesser degree of negative polarity.
It is pertinent for this paper to perform an analysis on Facebook, which is currently the social platform with the largest user base of 2.8 billion active monthly users [21]. Facebook has proven to be the social media platform with the highest user base, and as such it is pertinent for this paper to perform analysis on data collected for Facebook. A data set that specifically contains data predating the COVID-19 pandemic was accessed to broaden the scope of the sentiment analysis [22]. The data set includes data gathered from Facebook’s inception until 2017. A data set with a random selection of Facebook comments from the temporal range [22] was selected for sentiment analysis using VADER.
In Figure 7, a histogram was plotted with 30 bins, depicting the frequency of Facebook comments at various sentiment analytic levels. A KDE was overlayed onto the plot to show the general trend.
Figure 7.
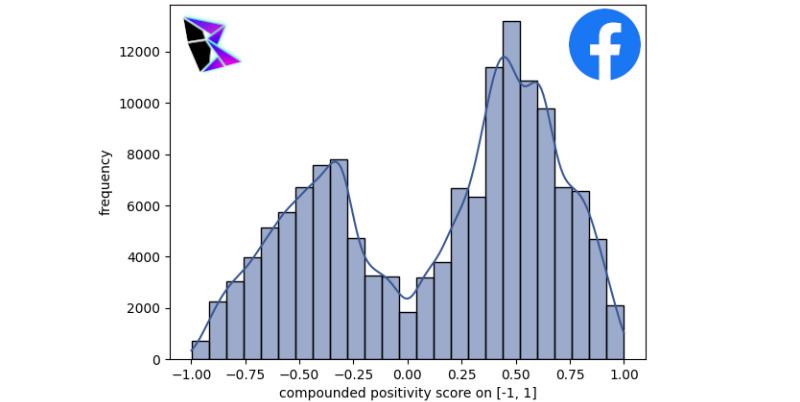
Facebook frequency of positivity histogram.
Notable features of the bimodal histogram include the sharp positive peak and wide negative peak. It should be noted that the integral for the KDE is as follows:
Furthermore, the following values were extracted from the KDE: μ+≈0.43, μ–≈–0.29, and γ≈0.49858.
YouTube
YouTube is based entirely on long-form video content and tends itself toward more in-depth topics. A preselected data set of YouTube comments [23], after sentiment analysis, has been visualized and presented in Figure 8.
Figure 8.

YouTube COVID-19 frequency of positivity histogram.
The data set [22] was collected in 2017 and, as such, does not contain misinformation related to COVID-19. This helps to broaden the temporal scope of this analysis and ensure that the present trends hold in data outside of the COVID-19 pandemic (ie, prior to January 2020). It was also limited in geographic scope to the United States, the United Kingdom, and Canada. This limitation was due to the availability of data. It should be noted that these three countries represent the English-speaking members of the Group of Seven, a group of the seven most democratic, affluent, and pluralist nations in the world.
As can be noted, there was a strong positive skewness in the data, with μ+≈0.67, μ–≈–0.52, and γ≈0.66593. The high positive skewness should be noted for these YouTube comments. Potential explanations for this trend will be discussed in a later section.
Parler
The analysis of Parler was a transition from the traditional analyses of Reddit and 4chan, due to the fact that Parler is not broken down into communities to which users subscribe but is a single news feed–style system. The analysis of Parler should be contrasted to the analysis of Twitter in the subsequent section, as users migrated from Twitter to Parler due to a perception of limitations placed on their freedom of expression on Twitter.
When analyzing Parler, data was collected into a data set throughout the COVID-19 pandemic and the period surrounding the events of January 6, 2021 [9]. Figure 9 contains a visualization of the COVID-19–related parleys posted between January 2020 and March 2020. The bimodal distribution was μ–≈–0.53, μ+≈0.45, and γ≈0.22063.
Figure 9.
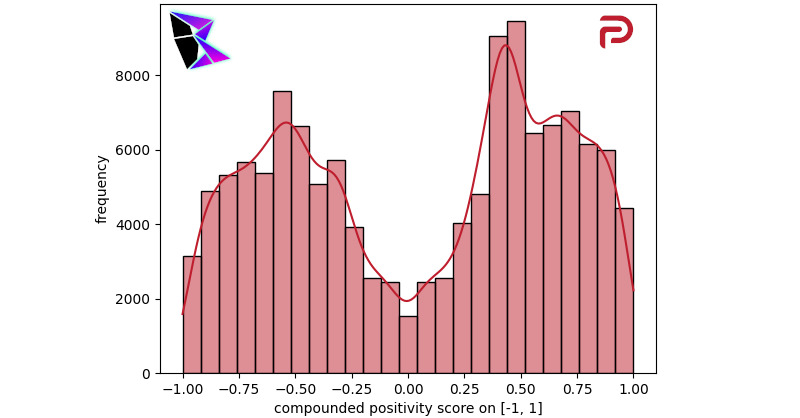
Parler COVID-19 frequency of positivity histogram.
The majority of the analysis performed through this paper was on the social media service Twitter. The reason for this is due to the high amount of data regarding misinformation on the platform, the overall popularity of the platform as a general case study, and the generality of the platform (compared to some other unorthodox data sources such as YouTube comments).
Similar to Parler, Twitter tweets are made at-large to the public. There are no channels, boards, or subreddits of any sort. However, due to the Twitter algorithm, there is an allowance of individuals’ feeds to be in an echo chamber. Evidently, echo chambers should be avoided wherever possible. Echo chambers are a large contributor to the rampant spread of misinformation that is seen surrounding the COVID-19 pandemic [24].
This study used a combination of both data gathered from the Twitter API and a data set of pregathered COVID-19 tweets [17,18,20]. The interface used to connect the Python code (and sentiment analysis) to the Twitter API was twarc. The reason for this duplication of analysis was to ensure that the data used was accurate. Precision must be maintained in both data collected by APIs and over a long duration.
In both studies (using the API and the data set [17]), the study analyzed the broad sentiment of COVID-19–related tweets and filtered the data by keyword. The keywords used included terms concerning misinformation surrounding COVID-19, including “China Virus,” “Bioweapon,” and “Microchip.” The filtered data then underwent sentiment analysis. Both sentimentally analyzed data were plotted on the standard histogram with overlaid KDE.
For the discussion, the study focused on the data gathered from the Twitter API, since a similar methodology was used for gathering data for the other social media platforms studied. However, it should be noted that similar results were attained using the data set [17]. Figure 10 is a graph of the Twitter API’s gathered tweets pertaining to COVID-19 (the broad topic), where the sentiments of the tweets are plotted on a histogram with a KDE. A random sample of the data was taken for this analysis, as there were too many tweets to reasonably analyze the population. The bimodal distribution was μ–≈–0.36, μ+≈0.47, and γ≈0.86500.
Figure 10.

Unfiltered COVID-19 Twitter application programming interface frequency of positivity histogram.
As can be noted, the positive peak for the KDE is nearly double the negative peak. This indicates that the number of positive tweets far exceeds the number of negative tweets. Comparatively in Figure 11, the negative peak of the bimodal distribution is on par with the positive peak. This figure is a histographic representation of the polarity score for tweets after being filtered. The tweets selected only contain terms that are known to pertain to COVID-19 misinformation. The bimodal distribution was μ–≈–0.42, μ+≈0.47, and γ≈0.80080 between the two Twitter measurements.
Figure 11.

Filtered COVID-19 Twitter API frequency of positivity histogram. API: application programming interface.
The study’s discussion of the reasoning behind this proportional increase in the negative peak compared to the positive peak will be discussed further in the subsequent section. Again, it must be noted that the same results can be seen when performing an identical analysis on the data gathered from the data set [17].
Discussion
In the Discussion section, not only will an analysis of the results and errors be explored but also the Plebeian Algorithm and its benefits will be discussed, as well as how it compares to the algorithms of the social media platforms studied.
Results Analysis
Several critical notes must be made with regard to the analysis of the quantitative features produced in the Results section.
First, it is critical to note that 4chan was the only social media platform studied that had an overall positive γ, notably on the all-encompassing board of /b/. It was gathered by the observations that a system that provided users with the freedom to determine which content got promoted—as opposed to an artificial intelligence algorithm—improved the sentiment of the average post. This is a key point in the Plebeian Algorithm, which is described in a subsequent section. Second, Twitter had a more moderate skew (ie, closer to 0, or neutral) μ–, indicating that users tended to be more positive than users on the other social media platforms analyzed in the study.
It is also critical to recall that there was a strong correlation between polarity scores as determined by a sentiment analysis algorithm and the verity of the information communicated [5]. As such, the analysis provided herein can be applied to both the sentiment and the verity of a social media post.
Echo Chambers
In analyzing the data represented by the KDEs and the skew of the bimodal distribution of the data toward negative sentiment, a confirmation of the echo chamber effect (a theory that states “the Internet has produced sets of isolated homogeneous echo chambers, where similar opinions reinforce each other and lead to attitude polarization” [25]) was clearly shown, as negative sentiment has a clear association with emotions such as anger, which have been shown to “...[reinforce] echo chamber dynamics...in the digital public sphere” [25]. In fact, other studies have also predicted the link to this effect to be the impact of the specific algorithms used in the virtual space [26]. The link gives strong evidence to suggest that the algorithms currently deployed by social media companies are creating the optimal medium through which misinformed opinions and content can grow and go uncontested. These echo chambers ensure that users are unable to get access to arguments that conflict with their beliefs and expand their perspectives.
Sources of Error
Although the study attempted to limit error, there remained several sources of error stemming from the methodology of analysis used. The first source of error is the trouble with using key term searching, as it would give us results of posts of not only individuals spreading misinformation but also those trying to bring attention to the issue of misinformation and those who spread it. Furthermore, the sentiment analysis would also have been unable to differentiate between a misinformed post and one that tried to bring attention to the problem. This is because some of the true tweets demonstrate overall negative emotions. The final problem with the key term search is that some of the key terms determined to be misinformative may in the future be proven to be accurate information.
A further source of potential error comes in the form of the social media platforms used. One problem is that only four social media platforms were assessed, thus limiting the scope of the study. It could be that the trends found in the research will not show up in other social media platforms (eg, Facebook). Another issue from the sources assessed was that they were all only textually based and thus the method proposed may not be replicable for more graphically based social media platforms (eg, YouTube, Instagram, or Snapchat).
Definition and Implementation of the Plebeian Algorithm
As described previously, the Plebeian Algorithm is a novel algorithm for identifying and removing misinformation through democratic means. It works in two distinct phases: the Flag Phase, to determine which posts are misinformative, and the Jury Phase, to judge the information to determine if removal is appropriate.
Flag Phase
The Flag Phase is tasked with the determination of possible misinformed posts. In doing so, the algorithm selects posts that have a large number of views and then performs sentiment analysis on both the original post and a “without-replacement simple random sample” [27] of comments or replies to the post. If the overall sentiment leans negative, then the post is flagged as being potentially misleading. The posts flagged will then be passed into the Jury Phase.
Jury Phase
The Jury Phase is tasked with the trial and removal of truly misinformative posts. These posts are removed from the home page or news feed of the user. During the Jury Phase, flagged posts are sent to a random selection of anonymous users known as jurors. This selection should provide a diverse group, consisting of varying political opinions to give the post a fair trial. The selection of jurors uses a “without-replacement simple random sample” of a population [27]. The number of jurors selected is exactly 10% of the number of viewers of a post, rounded up. It should be noted, however, that jurors are not forced to participate or vote. It is assumed that the number of voting jurors will be far less than the total number of jurors. Thus, selecting 10% of the population allows room for the uncertainty of juror engagement. The jurors are then asked to vote either for or against the removal of the post. Once the deliberation has lasted a set duration (or a threshold of response has been met), the results will be counted and the post will remain on the site or be removed by the algorithm.
For reference, a summative flowchart detailing the Plebeian Algorithm as described can be found in Figure 12. The areas colored in magenta constitute the Flag Phase, while the areas colored in mint green constitute the Jury Phase.
Figure 12.

Flowchart of the Plebeian Algorithm.
Existing Algorithms
In the following section, each of the algorithms will be detailed for Reddit, 4chan, Parler, and Twitter. These analyses will be based on academic journal articles [10-12,28,29]. It is pertinent to analyze these on a case-by-case basis, as it must be ensured that the user base remains loyal to the brand and platform [30]. Prevalent existing algorithms include the PageRank and Hits algorithms [31].
Before dissecting the individual social media algorithms that are currently being used for the various platforms, it is critical to mention that most of these algorithms have an identical goal: to get users to stay on the platform, thus ensuring a continued revenue for their organization. This objective contradicts the goal of preventing misinformation from spreading on the platform, as preventing misinformation requires some censorship, resulting in a reduction of revenue. This, however, is not to indicate that the Plebeian Algorithm is of little value to site entrepreneurs. It is critical to give note that the ultimate goal of social media companies (with the exception of Parler) have already shown themselves interested in curbing and moderating their own social media platforms through their implementation of “point-and-shoot” algorithms as well as censorship of high-profile posts and accounts (eg, Twitter banning @realDonaldTrump). However, as has already been described, these algorithms are not effective at accomplishing their mission of reducing misinformation and, further, have caused users to become disillusioned with the service. This has led to many users joining platforms that capitalize on this disillusionment (eg, Parler). Hence, by implementing the Plebeian Algorithm, these social media companies finally have a method that carefully balances moderation with freedom of expression that will reinspire a sense of awe within their user base and bring back the notion of social media being a fun online space where people can collaborate and share freely.
The algorithm used for Reddit is a simple upvote/downvote system, as was described in the Introduction section. Users of Reddit are encouraged to upvote content they like and are encouraged to downvote content that they do not like. Posts with more upvotes are more widely shared, whereas the opposite is true with posts with more downvotes. In Reddit, users are allowed to vote on the original post and any comments. “Comment trees” are inherently created by the system as users comment on comments (thereby chaining comments together into a treelike formation).
The Reddit algorithm is tailored to the interests of the Reddit user. Through a system of subscriptions to various topics of conversations or subreddits. Users will receive a mixture of content from the subreddits to which they have subscribed, with additional, sporadic advertisement.
The system is essentially tailored to the specific user. This contrasts with the Plebeian Algorithm, which emphasizes the democratic process for the determination of verity by the user base. Currently, Reddit contains no user-controlled means to fight misinformation aside from the “Report” button, which brings the issue to the attention of a staff person at Reddit. This process is considered a manual review by the corporation, and as such, it does not constitute something similar to the Plebeian Algorithm. For Reddit to implement a Plebeian Algorithm, it must ensure that the process of the misinformation determination remains in the hands of the user base.
Although Reddit currently appears to be a democratic system, it is more of a fiefdom [29]. For example, in 2013 the r/FindBostonBombers subreddit slandered the Brown family by connecting them with the 2013 attack on the Boston Marathon at the direction of the moderators of the subreddit [32]. Examples like this resonate throughout Reddit through incidents such as “the Fappening,” where nude photographs were released to the public unbeknown to victims. Incidents like these make apparent the crux of the fundamental issue with Reddit: the moderators. This promotes content moderation by a few elite members of communities, instead of by the members of the said community as a whole.
It should be noted that Reddit is a platform that is built on a sense of anonymity. Users are not required to add their personal email addresses or their real names. As is the case in all the implementations of the Plebeian Algorithm, it is important that the social media company critically analyzes the existing market served and existing qualities that users may be drawn to. An implementation of the Plebeian Algorithm on Reddit should preserve user anonymity and should still not require the use of personal emails or real full names.
4chan
The 4chan algorithm is similar to that of Reddit; it uses a system whereby the audience determines whether or not content is viewable to its users. In contrast to Reddit, 4chan uses an ephemeral system for its content [10]. 4chan is also divided into several boards that encapsulate distinct topics of conversation. Furthermore, any content can be posted on the /b/ board, as this board’s topic is described as “Random” [10]. A second critical aspect of the 4chan algorithm is the notion of anonymity. 4chan encourages its user base to remain anonymous through their posts. Over 90% of posts and comments on /b/, the most popular board on 4chan, are anonymous [10].
4chan is the algorithm that is nearest to the proposed Plebeian Algorithm; however, there are subtle yet notable differences. The Plebeian Algorithm does not incorporate any notions of anonymity nor ephemerality. Content must be both traceable and permanently recorded. This will help assure that the goals of the social media companies at-large (which often differ from the goals of 4chan) remain consistent. Keeping the goals consistent for each individual social media platform will be essential to ensure that the users of the platform remain loyal while gaining the added benefits that the Plebeian Algorithm offers.
For 4chan’s algorithm to become a Plebeian Algorithm, it should remove its ephemerality. This would be essential to ensure that content has the time to undergo the process. Content posted on 4chan’s /b/ often lasts less than 1 minute [10]. As such, the Plebeian Algorithm would not have the time to undergo both two phases (the Flag and Jury Phases), a critical step that is necessary to the algorithm’s democratic approach.
Facebook is a valuable selection, demonstrating a powerful social media platform and a tailored user experience; its popularity makes it useful for analysis. Although the Facebook company is not wholly transparent [9], the company has announced it highly favors personalized content of users (eg, posts from close friends and private groups) to that of public groups and pages to which the user likes and follows [33,34]. This presented a limitation for the analysis of Facebook data, as ideally, data had to be collected through preselected data sets for quantitative analysis [24].
There are many differences between the Facebook algorithm and the Plebeian Algorithm. The method used by Facebook, particularly during the COVID-19 pandemic, aims to combat the spread of misinformation and is based on neural networks trained to search for key terms in textual elements (including posts, comments, and statuses). It should also be noted that Facebook’s algorithm includes a large amount of human work, which is easily biased. As has been stated in prior sections, there are several issues with this method of misinformation censorship; most notably, the Facebook algorithm is limited in scope to a specific subset of misinformation topics. Algorithms of this nature will detect specific key terms such as “COVID” included in the text of a post to provide additional information and resources for viewers; these algorithms will also provide information to the user sharing the post before publicizing the post. On the contrary, the Plebeian Algorithm is proactive in nature: it is universally applicable to all forms of misinformation and works to combat infodemics before they become widespread. As stated previously, infodemics of misinformation have led to the problem of pandemics becoming exacerbated and thus harder to control for public health workers. By implementing the Plebeian Algorithm, public health will be improved, especially concerning future pandemics, as potentially dangerous misrepresentations or falsehoods about the situation will be contained to a smaller percentage of the populace, and thus ensures that reliable and trustworthy information is more accessible and widespread. The Plebeian Algorithm also requires less maintenance by developers, actively running automatically without the requirement of hard coding key terms to flag.
For Facebook to implement a Plebeian Algorithm, a high degree of planning would be required. Since Facebook is the most prevalent social media platform, a gradual implementation based on a rolling basis is recommended. AB testing should be used to ensure a smooth and successful implementation. Facebook should automate and democratize their home page algorithm to implement a Plebeian Algorithm for its service.
YouTube
Due to the inherent difficulty in performing visual sentiment analysis for videos, comments of YouTube videos were analyzed. This does not give a complete picture of the YouTube algorithm, which attempts to keep users engaged longer on the website by presenting a tailored feed; the end goal being that the algorithm can predict videos the user would like to watch before they search [35]. This algorithm looks at a range of user data including watch time, closing a video tab, the user’s interests, freshness, and user interactions with the video [35]. This algorithm has proven highly effective at finding and distributing viral content.
By aligning with the user’s sentiment, the algorithm can effectively produce more positive comments, as seen in Figure 8. A sentiment filter used by YouTube includes the removal of videos that do not meet advertiser guidelines [36]. The main difference between YouTube’s current content moderation approach and a Plebeian Algorithm’s implementation of content moderation is the democratic aspect of content removal. This is made clear with many of YouTube’s controversies within their community revolving around a lack of communication and censorship of larger creators [37].
The moderation system of YouTube is already a form of the Plebeian Algorithm with users being able to like and dislike comments or videos, in addition to reporting them if they are unwanted. The main disconnect between this and the Plebeian Algorithm is that, when a comment or video is reported, there is no public jury phase where the community decides if it stays. This has become clear with YouTube’s controversies within the community revolving around issues such as the lack of communication and censorship of YouTube influencer Logan Paul. Should YouTube implement the Plebeian Algorithm, a Jury Phase is required after content is reported and prior to its removal process. It should also be noted that YouTube’s jurors are not a random distribution. The moderation algorithms are programmed by humans, and as such, it is extremely difficult to ensure that the correct decisions are consistently being made. Artificial intelligence forms the basis of the YouTube algorithm, but the plebeian jury is replaced with a judge, who may be easily persuaded or hold personal biases. The wisdom of the crowd phenomenon (quod vide) plays a substantial role in the use of the jury for the Plebeian Algorithm.
Parler
Parler uses a more typical algorithm. It limits posts to 1000 characters and circulates them to the user base at-large. Thus, unlike Reddit and 4chan, there are no communities in which content is posted on Parler. Parler was founded as a promoter of the freedom of speech, and as such, its user base is highly concerned with a lack of censorship on their posts [11].
Although this may at face value appear to be in direct opposition to the implementation of any algorithm, it is important to note that the Plebeian Algorithm ensures that any and all decisions regarding the verity of information remain in the users’ hands. Parler would still benefit from implementing a Plebeian Algorithm, as it would preserve Parler’s ultimate goal (to promote freedom of expression) while limiting the spread of misinformation.
For Parler to implement a Plebeian Algorithm, it must implement both the Flag and Jury Phases of the Plebeian Algorithm. Notably, the preservation of the freedom of expression on the platform must be ensured above all. This will ensure that the user base remains loyal and supportive of the change and does not boycott Parler or switch to a new social media platform (as they have already migrated from Twitter). The Parler user base is notably precarious, and it must ensure that the user base remains loyal to the platform. This should be done through proper marketing of the transition, which is to be discussed later.
Finally, Twitter uses a similar algorithm (in opposition still to Reddit and 4chan) in that posts and content are released to the user base at-large. The techniques of this algorithm particularly means that misinformation is more likely to spread on Twitter (and Parler) compared to other platforms (eg, Reddit and 4chan). The large user base on Twitter and the widespread availability of data must be taken into account, as it will be crucial that the culture and atmosphere of Twitter are maintained to ensure that the user base remains content with any algorithmic changes. Twitter’s executives most likely would be interested in increasing their reach by attempting to regain the trust of those who migrated to Parler. These individuals are highly concerned with a decrease in censorship and an increase in the freedom of expression. They believe that the social media platform should remain separate from the process of promotion and demotion of content [11].
For Twitter to implement a Plebeian Algorithm, it must attempt to promote the freedom of expression and a decrease in censorship while also maintaining their reliability. This is done using the Plebeian Algorithm, which takes advantage of both concerns. Layperson algorithms have proven effective at curbing the spread of misinformation and at increasing reliability [18]. According to the definition by Epstein et al [16], the Plebeian Algorithm would be classified as a type of layperson algorithm. Twitter would need to place a level of trust in the layperson to provide the user base with liberty while maintaining truth in the content posted.
Condorcet’s Jury Theorem
As was researched in the 18th century by the Marquis de Condorcet, the Condorcet’s jury theorem [38] clearly justifies the need for the Jury Phase in the Plebeian Algorithm. The theorem describes the behavior of a larger number of individuals selected to sit on a jury to judge the crimes of another individual. Proposed by Condorcet (and later proven by numerous mathematicians and statisticians in the late 20th century), the theorem explains that two scenarios may unfold when attempting to determine the truth by means of polling a sample of the population [38]. First, if the sample’s understanding of the topic is poor, their judgement will not be certain. In this situation, the optimal sample size would be a single individual, as increasing the number of jurors will only increase the uncertainty [38].
However, a jury implemented in the Plebeian Algorithm should take Condorcet’s jury theorem into account, by ensuring that the jury falls into the second scenario. The second type of jury would occur when the jury’s knowledge of the subject is relatively high or is perceived as relatively high [38]. As such, an optimal Plebeian model would be passive, instead of aggressive, in its UI/UX. It should be ensured that acting as a juror is entirely optional and is opt-in instead of opt-out. The user interface should be minimal to ensure that the public reception of the implementation of the Plebeian Algorithm is positive. Although this will likely decrease the percentage of the sample who opt-in to act as jurors, consistence will be achieved due to the positive reception of the algorithm implementation. An ideal Plebeian Algorithm implementation to secure the second subset of juried defined by Condorcet’s jury theorem may go unnoticed for the average user.
Assuming that an implementation of the Plebeian Algorithm can secure its jury into the latter jury type, it would secure the wisdom of the crowd. Increasing the sample selected as potential jurors will increase the certainty. This phenomenon has been described as “wisdom of the crowd” [39]. As the sample size increases, the certainty of the decision that the jury comes to also increases. Thus, taking a sample size of 1% has a higher possibility of accidentally selecting a group of the most extreme individuals, compared to randomly selecting a sample size of 10%.
Eradication Versus Containment
One of the benefits of the Plebeian Algorithm in comparison to the status quo is the difference between eradication and containment. The algorithms of the current system tend to use an eradication approach. They view the issue of the spread of misinformation with a narrow perspective [35], and as such, they tend to implement a “Point-And-Shoot” algorithm. With this system, media companies determine which posts contain misinformation and eradicate them on a case-by-case basis. For example, many social media companies use a COVID-19 key term search and flag posts that contain them. They then link to a government website with information on the pandemic to the post.
This is in stark contrast to the Plebeian Algorithm, which takes a containment-based approach to the spread of misinformation. It should be noted that the technology to remove all instances of misinformation does not exist [40]. Instead, it is important that the algorithm detects as many cases of misinformation as possible and brings the rest to the broad public. This essentially “pops” any filter bubbles and echo chambers [26]. It allows for positive discussion from the community, which tends to lead toward a decrease in misinformation [4].
Reduced Censorship
Another massive benefit of the Plebeian Algorithm is the reduction of censorship. With regard to the COVID-19 pandemic, a majority of misinformed posts has been spread by those with politically right ideologies, or Republicans. A total 48% of US Republicans believe that SARS-CoV-2 is no more dangerous than the common influenza [41] (compared to 25% of US Democrats [41]), and 42% of Republicans believe that hydroxychloroquine—a treatment for malaria—is an effective treatment for SARS-CoV-2 [41] (compared to 5% of Democrats [41]). Furthermore, Republicans (or those with political right ideologies) tend to be more concerned with the preservation of the freedoms of speech and expression. Thus, it is evident that we must preserve these freedoms for any algorithmic change to be effective. The Plebeian Algorithm goes further than this: it works to increase the rights of the individuals with respect to cross-region community matching freedom of expression. Individuals have the right to post and speak as they please and promote the spread of the information they deem to be pertinent. Additionally, they have the right to decide what content they want to see on the platform and what they do not. These benefits will help to ensure that the public reacts in a positive light to the change. Implementing a Plebeian Algorithm is a net positive; it is a positive change for both the containment of infodemics and the promotion of freedom of expression among social media users. Furthermore, under the Plebeian Algorithm, social media companies are still permitted to analyze user activity according to their privacy policies to provide appropriate advertisements tailored to the user. This will ensure that the revenues for social media companies will not be reduced in the process.
Viral Naming Conventions
One subtopic explored herein is viral naming conventions and the connection between the name used to describe COVID-19 in relation to the level of verity in social media posts. For the purpose of this analysis, only posts on COVID-19 were considered; thus, social media platforms for which the data used herein was collected before 2020 were not analyzed (ie, Facebook and YouTube). Parler was examined at length since it uses a relatively standard social media algorithm, comparable to that of Twitter. A pickle file of Parler data, filtered to COVID-19, was generated from the Parler data set [9]. Additional filters were applied to the pickle file, as are described later.
To simplify the analysis, three categories of parleys were created on which analysis was performed separately. First, all posts mentioning COVID-19 using any naming conventions were gathered. The posts were collected using no additional filters, labelled “None.” Second, from the COVID-19 parleys, a filter was applied to gather all parleys containing viral names referring to locations including, but not limited to, “Wuhan Virus,” “China Virus,” and “Indian Variant.” All these terms have been described by the US Centers for Disease Control and Prevention (CDC) to potentially propagate misinformation and xenophobia [42,43]. This filter was termed “Locational Taxonomy” [44]. The final filter, “Biological Taxonomy” [44], refers to the biological names for COVID-19, or officially approved names by the WHO, including, but not limited to, “SARS-CoV-2,” “Alpha Variant,” and “B.1.617.” This nomenclature is used and promoted by the CDC [38] to limit xenophobia. As such, it was hypothesized that parleys using these terms would be less likely to be misinformative and more likely to have a positive sentiment [45].
Sentiment analysis was performed on all three filtered data sets, and the results were plotted as a violin plot in Figure 13. Each subplot portrays the three filters as discrete categories along the x-axis (ie, “None,” “Locational Taxonomy,” and “Biological Taxonomy”) against the compounded polarity score on [–1, 1]. Each subplot visualizes a KDE that is rotated vertically for ease of visualization and a pictorial representation of the median, mean, first quartile, and third quartile.
Figure 13.
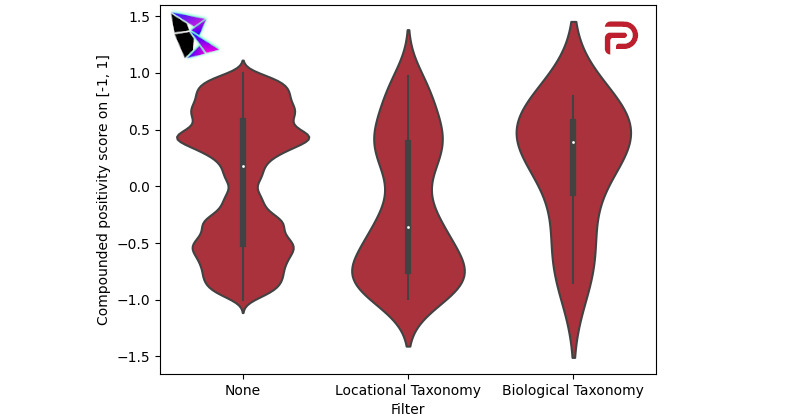
Viral naming conventions on Parler: violin plot.
This visualization provides exceptionally relevant results. The data filtered to COVID-19 at-large was similar to the KDEs plotted for all of the social media algorithms discussed in the Results section, demonstrating a precise bimodal distribution with a positive and negative peak, and a neutral trough. The violin plots for the locational and biological taxonomies verified the hypothesis. The locational taxonomy filter showed strong negative sentiment, implying a higher likelihood of misinformation. In contrast, the biological taxonomy filter showed a strong positive sentiment, implying a greater degree of verity.
It is important to note that the findings are not limited to COVID-19. Similar findings were discovered (not pertaining to social media) relating to the 2009 H1N1/09 pandemic [46,47] and the 1918 Spanish Flu pandemic [15], among others [48,49], for which there were concerns surrounding xenophobic viral nomenclature. It is also pertinent to discuss the specific limitation surrounding the use of COVID-19 data for this analysis. It is often difficult for populations to alter their vocabulary to change the reference of a xenophobic initial name to an accurate descriptor [50]. Specifically, with regard to COVID-19 variants of concern (VoCs), many scientific sources still note the location of the VoC’s discovery. This brings two significant points to the forefront of discussion: first, national health agencies need to provide precise and nonxenophobic nomenclature from the onset of pandemics, and second, the use of locational taxonomy should not automatically flag a post (ie, it should be flagged through sentimental analysis solely). The Plebeian Algorithm assists in this analysis, as it does not consider specific search terms, but rather pure sentiment. This handles issues surrounding truthful posts containing locational taxonomy. The lack of consensus among the scientific community should be noted regarding the potential benefits and drawbacks of using locational taxonomy [15,45].
Geolocation
There exists a critical connection between the virtual and physical worlds as it pertains to the spread of misinformation and various consequences therefrom. Several studies have been conducted hereupon. One fundamental limitation posed by the use of social media platforms to track the spread of misinformation is the inability to deal with the spread of misinformation in more personal settings (eg, face-to-face interactions, videoconferencing, and direct messaging). Thus, a thorough study of the translation of misinformation from social media platforms to real-world phenomena will be conducted.
Myriad studies have been conducted surrounding infodemics [51-53]. This includes the correlation between geolocation of social media connections and various social determinants (eg, race, sex, and socioeconomic status) [51], and a study [54] determining optimal methods of geolocation on social media. Two additional studies discussed the sociological consequences of geolocation in the context of social media, namely, the detection and reduction of youth cannabis consumption [52] and the applications of geolocation to urban planning [53].
Furthermore, studies suggest that there exists a strong correlation between trends on social media and events such as COVID-19 [12,51]. Evidently, any change on social media will have real-world impacts. Thus, it is apparent that a reduction in the amount of misinforming content in a social media user’s home page corresponds with a reduction in the likelihood that they will propagate misinformative statements when having in-person conversations. Successful implementation of the Plebeian Algorithm will limit the spread of misinformation on social media platforms and in the lives of their users.
Public Reaction
Skeptics of the Plebeian Algorithm might be concerned that such a massive alteration of the social media algorithm will incite hesitancy from the public. Whether this hesitance takes the form of negative feedback or boycotting, it is extremely legitimate and must be dealt with. Many will point to the 4chan platform as a negative example of an algorithm that offers user discretion regarding the promotion of content instead of a corporate algorithm.
Marketing
This paper will first argue that the major difference between the two strategies lies within the realm of marketing. Marketing is a critical aspect of any social media company, especially when undergoing massive changes. In fact, some broad-scale social changes require marketing strategies [55]. Companies must ensure that the Plebeian Algorithm is adapted to meet the specific needs and goals of the social media company and its user base. For this reason, the Plebeian Algorithm is simply a suggested implementation, with a footnote that the algorithm must be highly adapted to the unique situation. Every social media company has varying objectives, such as Facebook’s aim to connect friends, Reddit’s goal to create conversations between like-minded individuals, and Parler’s goal of preserving freedom of expression.
An effective marketing strategy for the transition to the Plebeian Algorithm ensures that users are aware that the overall atmosphere of the social media platform will not be altered. Promotion of the current atmosphere must take priority, lest the change face backlash by users. There is a potential, should improper marketing be implemented, that overly moderated individuals may leave the social media platform, leaving those with more extreme (and often misinformed) views to take over the widespread content of the platform. However, adequate marketing that emphasizes the static nature of the culture and social atmosphere of the platform during the transition alleviates this concern.
Feedback of Current Algorithms
Second, this paper will discuss the feedback on the current algorithms as provided by the community. This feedback consists of discussions on social media platforms about each platform’s algorithm. An analysis of preselected opinion pieces was performed [33,34,56-62]. These opinion pieces were sourced from well-known news or magazine sources, discussing the various social media platforms analyzed herein.
Overall, there is substantial desire for social media platforms to be more democratic in their algorithm. It is also widely believed among many social media users that, to improve algorithms, companies should implement a more transparent algorithm. Currently, algorithms vary widely and the functionality of most are not publicly available information. Changes improving transparency tend toward positive user feedback on the platform.
It is also critical to note that, for any implementation of the Plebeian Algorithm, a post must exceed a popularity threshold to be flagged in the Flag Phase. It is essential for the social media platforms to adapt their current algorithm to the determination of this popularity threshold. The goal of most current algorithms is to show users popular content that they may enjoy based on past interests. This can be done through a plethora of metrics, including likes, views, comments, recency of the post (termed “freshness”) [35], and more. For example, the Twitter algorithm tends to prioritize the number of comments, whereas the YouTube algorithm prioritizes freshness.
Implementation
Another concern of a potential implementing platform of the Plebeian Algorithm would be the technological requirements of the implementation, including storage and processing power required to conduct the Plebeian Algorithm on their millions of posts. Furthermore, this application of the Plebeian Algorithm would need to be a continuous process, ensuring that the algorithm continually updates when new comments are added to a post. As has been shown herein, the inclusion of comments increases the level of detail. All the data analyses visualized herein included comments and the text of the original post. As such, the computational power required appears to be great. There are, however, many alterations that can be made to the Plebeian Algorithm to reduce computation costs.
First, the Plebeian Algorithm does not need to be updated with the post of every new comment. It can be performed on intervals, whereby a subsection of posts is checked for new comments at every time interval. These new comments (and only the new comments) are then sent through sentiment analysis. In terms of data storage, it may prove useful for the social media platform to store a single additional byte of data for each post. The bit of highest significance, referred to as the “Flag of Need Determination,” represented as ϕd can be defined using the following equation:
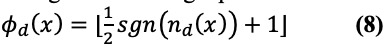 |
such that:
 |
where nd represents the value of determination (which is not scaled), x represents a thread, xi represents a specific comment or post within a thread, ν is a Boolean function returning a high value if the comment is new and low if it has been analyzed, sgn represents the signum function, vact and vthres represent the actual and threshold popularity of a thread in number of views, and N represents the number of posts or comments in the thread.
If high, the post or thread can be safely skipped by the algorithm. If low, the post or thread will be analyzed to ensure that no misinformation goes undetected. The remaining seven bits of the data represent the sentiment of the entire thread, represented using βN, where N is the number of comments in the post, excluding the original post. These bits can be calculated using the following equations:
 |
In some circumstances, it may be more computationally convenient to calculate βN recursively, which may be done using the following:
 |
These equations demonstrate that a byte can be associated with each thread to decrease the processing requirements to execute the Plebeian Algorithm on a large scale.
It should also be noted that the Plebeian Algorithm is a machine learning model. It can be built to work in tandem with existing machine learning algorithms, thus decreasing the computing power required. Data storage is minimized using the one-byte storage method previously described. As is the case with all neural networks, the Plebeian Algorithm’s Flag Phase will increase in accuracy over time by manipulating the string data as a validation set. Thus, the neural network will improve in accuracy over time. Due to time and resource limitations, the paper used the VADER; however, to increase Flag Phase precision over time, it is recommended that platforms implement the VADER sentiment analysis tool initially but build on it to adapt to the specific lexicon of the social media platform at the period of time. This accounts for minor differences in various social media algorithms and for lexical changes over time.
It is critical that a public release of the Plebeian Algorithm should be done through a process of AB testing. To efficiently fix any inevitable bugs present in the implementation of the algorithm (including any potential philosophical issues surrounding a specific realization/implementation), AB testing will be vital in the assurance that users consuming media under the new algorithm remain loyal to the brand and minimize any potential negative impacts. It will allow user feedback to be gathered for the small subsection of users presented with the Plebeian Algorithm implementation.
Limitations
Although the Plebeian Algorithm is a great replacement for the current attempts by social media platforms to reduce the spread of misinformation, it is limited by several key factors. First, as stated earlier, the algorithm was only confirmed applicable for strictly text-based social media platforms and posts. Thus, the moderation of videos or images are outside of the scope of its use. Second, private sources of media such as chat rooms and servers are not within the scope of the algorithm, and thus, the algorithm is limited to public communication media. Third, the determination of a popularity threshold can be problematic. On Twitter, for example, a significant number of retweets are done passively (ie, they are not done for the express purpose of sharing with others but are done subconsciously by the user). Passive sharing may cause issues in the determination of whether a piece of content meets a popularity threshold. Finally, it is limited in the sense that it cannot determine what is misinformation at an instantaneous time selection, and as such, misinformation cannot be extracted from the algorithm at any time.
Conclusions
The implications of this research are significant as to provide social media platforms with a new flagging method that uses sentiment analysis. This will be critical in the detection and prevention of infodemics and using a democratic approach that gives the power to the social media user to ultimately decide what content should be on the platform based on accuracy. The Plebeian Algorithm directly reduces political polarization and extremist ideas, which create a divide among users and improve cooperation on resolving key issues and problems plaguing humanity and restoring the trust between the public and experts.
Additionally, it is predicted that this will result in more reliable social media platforms, leading to an overall reduction of ignorance and misinformed opinions among users. Finally, the model created will lead to users expressing themselves without concern of the political viewpoint of the social media platform. Inherently, this also minimizes the impact of external biases, such as political climate, as those who vote will be completely random and anonymous.
Many areas of research remained unanalyzed. These topics include, but are not limited to:
Conducting a study on the use of the Plebeian Algorithm on a selection of social media platforms and detecting the amount of misinformation over time after its implementation (ie, a real-world tested example) that would then be compared to current methods used, such as the aforementioned “Point-And-Shoot” Algorithm
Creating a type of sentiment analysis for graphical content that could examine the emotion within an image to determine if it could be misinformation (eg, Snapchat, Instagram, and TikTok) [63,64]
Determining the spread of misinformation correlated with the spread of viruses—this could be useful in predetermining locations (and users by extension) who are at higher risk of being exposed to or expounding misinformation
Exploring the applicability of the Plebeian Algorithm in surveillance contexts, including for criminal investigations, employee onboarding, and health care [65-68]
Analyzing the spread of misinformation through online vendors such as Amazon or eBay. In particular, recent audits of Amazon (as of 2021) show a dangerous disregard for reliable information, for example, presenting vaccine misinformation books along with well-cited vaccine information books in generic searches for vaccine information [69-73]
Applying models of higher sophistication for data analysis and visualization (which requires access to more in-depth data), including term frequency–inverse document measures [74] and Levenshtein distances [75] among others [76]
Examining the optimal method of implementation and integration for the Plebeian Algorithm with various existing networking systems and infrastructures
Continuing analysis of data collected to corroborate to prior studies on behavioral impacts of the sentiment of informative posts on social media
Analyzing the role of corporate social media platforms (ie, Slack) in the dissemination of misinformation, especially in private chat channels
Examining the misinformation containment models using juries, including the jury system implemented by Wikipedia
Analyzing the rise of audio-form content, including podcasts, Clubhouse, and Spotify Greenroom audio-chat rooms, for the potential spread of misinformation—many of these media are becoming increasingly influential sources of news and information for many [77]
Exploring the connection between location-based social media apps (eg, Foursquare) at the spread of geographic misinformation [78]
COVID-19 has had substantial impacts upon modern society. Optimists hoped these impacts would prove to unite a polarized world in the spirit of cooperation and global security. Although this has happened, their hopeful unity to the political schism has not. The Plebeian Algorithm is not a vaccine for an infodemic; however, it is a treatment to help curb and prevent the virus of misinformation from continuing to spread and grow out of control. This has the critical side-effect of putting power back in the hands of the people and removing the potential domination of a single entity (eg, a social media company) who may be swayed by external forces when deciding if content should be removed. All in all, it is recommended that social media executives consider the implementation of a variation of the Plebeian Algorithm, explicitly modified to adapt to the specifics of the platform. This will help curb misinformation both with regard to the COVID-19 infodemic and to prevent future infodemics.
Acknowledgments
The authors would like to acknowledge the assistance in ideation from Anish R Verma from the STEM Fellowship. In addition, the authors are grateful for the assistance provided by Vinayak Nair concerning refinement of arguments from a data science perspective. Sponsors for the Undergraduate Big Data Challenge 2021, including JMIR Publications, Roche, SAS, Canadian Science Publishing, Digital Science, and Overleaf, made it possible for this research to be conducted.
Abbreviations
- API
application programming interface
- CDC
Centers for Disease Control and Prevention
- KDE
kernel density estimation
- VADER
Valence Aware Dictionary and Sentiment Reasoner
- VoC
variant of concern
- WHO
World Health Organization
Footnotes
Conflicts of Interest: None declared.
References
- 1.Karim F, Oyewande AA, Abdalla LF, Chaudhry Ehsanullah R, Khan S. Social media use and its connection to mental health: a systematic review. Cureus. 2020 Jun 15;12(6):e8627. doi: 10.7759/cureus.8627. http://europepmc.org/abstract/MED/32685296 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Kim HH. The impact of online social networking on adolescent psychological well-being (WB): a population-level analysis of Korean school-aged children. Int J Adolescence Youth. 2016 Jun 16;22(3):364–376. doi: 10.1080/02673843.2016.1197135. https://www.tandfonline.com/doi/full/10.1080/02673843.2016.1197135 . [DOI] [Google Scholar]
- 3.Watson A. Share of adults who use social media as a source of news in selected countries worldwide as of February 2020. Statista. 2020. [2021-07-14]. https://www.statista.com/statistics/718019/social-media-news-source/
- 4.Walsh DR. Neutral isn't neutral: an analysis of misinformation and sentiment in the wake of the capitol riots. The Research Repository @ WVU. 2021. May 10, [2021-07-14]. https://researchrepository.wvu.edu/etd/8055/
- 5.Wardle C, Derakhshan H. Information disorder: toward an interdisciplinary framework for research and policy making. Counc Europe Rep. 2017 Dec 27;2017(09):1–109. https://rm.coe.int/information-disorder-toward-an-interdisciplinary-framework-for-researc/168076277c . [Google Scholar]
- 6.Bradd S. Infodemic. World Health Organization. [2021-07-14]. https://www.who.int/health-topics/infodemic#tab=tab_1 .
- 7.Hazelwood K, Bird S, Brooks D, Chintala S, Diril U, Dzhulgakov D, Fawzy M, Jia B, Jia Y, Kalro A, Law J, Lee K, Lu J, Noordhuis P, Smelyanskiy M, Xiong L, Wang X. Applied machine learning at Facebook: a datacenter infrastructure perspective. Facebook Inc. 2017. [2021-07-14]. https://research.fb.com/wp-content/uploads/2017/12/hpca-2018-facebook.pdf .
- 8.Berstein M, Monroy-Hernández A, Harry D, André P, Panovich K, Vargas G. 4chan and /b/: an analysis of anonymity and ephemerality in a large online community. Fifth International AAAI Conference on Weblogs and Social Media; July 17-21, 2021; Barcelona, Catalonia, Spain. 2011. Jul 17, p. A. https://www.researchgate.net/publication/221297869_4chan_and_b_An_Analysis_of_Anonymity_and_Ephemerality_in_a_Large_Online_Community . [Google Scholar]
- 9.Aliapoulios M, Bevensee E, Blackburn J, Bradlyn B, De Cristofaro E, Stringhini G, Zannettou S. An early look at the Parler online social network. arXiv. Preprint posted online on January 11, 2021. https://arxiv.org/pdf/2101.03820.pdf . [Google Scholar]
- 10.Massanari A. #Gamergate and The Fappening: how Reddit’s algorithm, governance, and culture support toxic technocultures. New Media Soc. 2016 Jul 09;19(3):329–346. doi: 10.1177/1461444815608807. [DOI] [Google Scholar]
- 11.Kumar KPK, Geethakumari G. Detecting misinformation in online social networks using cognitive psychology. Hum-centric Computing Inf Sci. 2014 Sep 24;4(1):1–22. doi: 10.1186/s13673-014-0014-x. [DOI] [Google Scholar]
- 12.Stephens M. A geospatial infodemic: mapping Twitter conspiracy theories of COVID-19. Dialogues Hum Geography. 2020 Jun 23;10(2):276–281. doi: 10.1177/2043820620935683. [DOI] [Google Scholar]
- 13.Fernández M, Bellogín A, Cantadlr I. Analysing the effect of recommendation algorithms on the amplification of misinformation. arXiv. Preprint posted online on March 26, 2021. https://arxiv.org/abs/2103.14748 . [Google Scholar]
- 14.Plaza M, Paladino L, Opara I, Firstenberg M, Wilson B, Papadimos T, Stawicki S. The use of distributed consensus algorithms to curtail the spread of medical misinformation. Int J Academic Med. 2019;5(2):93. doi: 10.4103/ijam.ijam_47_19. [DOI] [Google Scholar]
- 15.Hoppe T. "Spanish Flu": when infectious disease names blur origins and stigmatize those infected. Am J Public Health. 2018 Nov;108(11):1462–1464. doi: 10.2105/AJPH.2018.304645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Epstein Z, Pennycook G, Rand D. Will the crowd game the algorithm? Using layperson judgments to combat misinformation on social media by downranking distrusted sources. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems; CHI '20; April 25-30, 2020; Honolulu, HI. 2020. Apr 25, https://dl.acm.org/doi/10.1145/3313831.3376232 . [DOI] [Google Scholar]
- 17.Kaushik S. Covid vaccine tweets. Kaggle. 2021. [2021-07-14]. https://www.kaggle.com/kaushiksuresh147/covidvaccine-tweets .
- 18.Memon SA, Carley KM. CMU-MisCov19: a novel Twitter dataset for characterizing COVID-19 misinformation. Zenodo. 2020. Sep 19, [2021-07-14]. https://zenodo.org/record/4024154 .
- 19.Gruzd A, Mai P. Inoculating against an infodemic: a canada-wide Covid-19 news, social media, and misinformation survey. SSRN J. Preprint posted online on May 11, 2020. doi: 10.2139/ssrn.3597462. [DOI] [Google Scholar]
- 20.Palachy S. Twitter datasets. GitHub. 2020. [2021-07-14]. https://github.com/shaypal5/awesome-twitter-data .
- 21.Tankovska H. Number of monthly active Facebook users worldwide as of 1st Quarter 2021. Statista. 2021. [2021-07-14]. https://www.statista.com/statistics/264810/number-of-monthly-active-facebook\-users-worldwide .
- 22.Span J. FacebookR comments. GitHub. 2017. [2021-07-14]. https://github.com/jerryspan/FacebookR .
- 23.Mitchell J. Trending YouTube video statistics and comments. Kaggle. 2017. [2021-07-14]. https://www.kaggle.com/datasnaek/youtube .
- 24.Rhodes Sc. Filter bubbles, echo chambers, and fake news: how social media conditions individuals to be less critical of political misinformation. Political Commun. 2021 May 01;:1–22. doi: 10.1080/10584609.2021.1910887. https://www.openicpsr.org/openicpsr/project/135024/version/V2/view . [DOI] [Google Scholar]
- 25.Wollebæk D, Karlsen R, Steen-Johnsen K, Enjolras B. Anger, fear, and echo chambers: the emotional basis for online behavior. Soc Media Soc. 2019 Apr 09;5(2):205630511982985. doi: 10.1177/2056305119829859. [DOI] [Google Scholar]
- 26.Pariser E. The filter bubble: what the internet is hiding from you. Standford HCI Group. 2011. [2021-07-14]. https://hci.stanford.edu/courses/cs047n/readings/The_Filter_Bubble.pdf .
- 27.Frerichs RR. Simple random sampling. Jonathan and Karin Fielding School of Public Health. [2021-07-14]. https://www.ph.ucla.edu/epi/rapidsurveys/RScourse/RSbook_ch3.pdf .
- 28.Rosenberg H, Syed S, Rezaie S. The Twitter pandemic: The critical role of Twitter in the dissemination of medical information and misinformation during the COVID-19 pandemic. CJEM. 2020 Jul 06;22(4):418–421. doi: 10.1017/cem.2020.361. http://europepmc.org/abstract/MED/32248871 .S1481803520003619 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Auerbach David. Reddit Scandals: Does Reddit Have a Transparency Problem? Slate. [2021-07-14]. https://slate.com/technology/2014/10/reddit-scandals-does-the-site-have-a-transparency-problem.html .
- 30.DeVito M, Gergle D, Bernholtz J. Algorithms ruin everything: RIPTwitter, folk theories, and resistance to algorithmic change in social media HCI and collective action. Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems; CHI '17; May 6-11, 2017; Denver, CO. 2017. May 02, pp. 3163–3174. [DOI] [Google Scholar]
- 31.Comparative study of HITS and PageRank Link based ranking algorithms. Cornell University Blog Service. 2015. Oct 27, [2021-07-14]. https://blogs.cornell.edu/info2040/2015/10/27/comparative-study-of-hits-and-pagerank-link-based-ranking-algorithms/
- 32.McIntyre MM. Relational agency, networked technology, and the social media aftermath of the Boston Marathon bombing. ProQuest. 2015. Sep 16, [2021-07-14]. https://www.proquest.com/openview/f3b73d2fae6805d92eed81229392053b/1?cbl=18750&parentSessionId=hkM46Px9ikwBr%2FfL65fe%2FaUV3N0iqN0Q4j6bazFyTvE%3D&pq-origsite=gscholar&accountid=47192 .
- 33.Hutchinson A. The pros and cons of Facebook's coming news feed changes-from a page perspective. Social Media Today. 2018. Jan 17, [2021-07-14]. https://www.socialmediatoday.com/news/the-pros-and-cons-of-facebooks-coming-newsfeed-changes-from-a-page-pers/514776/
- 34.Cooper P. How the Facebook algorithm works in 2021 and how to make it work for you. Hootsuite Blog. 2021. Feb 10, [2021-07-14]. https://blog.hootsuite.com/facebook-algorithm/
- 35.Covington P, Adams J, Sargin E. Deep neural networks for YouTube recommendations. Proceedings of the 10th ACM Conference on Recommender Systems; RecSys '16; September 15-19, 2016; Boston, MA. 2016. Sep 15, pp. 1–8. https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf . [DOI] [Google Scholar]
- 36.Terms of service. YouTube. 2021. [2021-07-14]. https://www.youtube.com/static?template=terms .
- 37.Southerton C, Marshall D, Aggleton P, Rasmussen ML, Cover R. Restricted modes: Social media, content classification and LGBTQ sexual citizenship. N Media Soc. 2020 Feb 13;23(5):920–938. doi: 10.1177/1461444820904362. [DOI] [Google Scholar]
- 38.Austen-Smith D, Banks JS. Information aggregation, rationality, and the Condorcet jury theorem. Am Polit Sci Rev. 2014 Aug 01;90(1):34–45. doi: 10.2307/2082796. [DOI] [Google Scholar]
- 39.Yi S, Steyvers M, Lee MD, Dry MJ. The wisdom of the crowd in combinatorial problems. Cogn Sci. 2012 Apr;36(3):452–70. doi: 10.1111/j.1551-6709.2011.01223.x. [DOI] [PubMed] [Google Scholar]
- 40.Ghoshal AK, Das N, Das S. Influence of community structure on misinformation containment in online social networks. Knowledge-Based Syst. 2021 Feb;213:106693. doi: 10.1016/j.knosys.2020.106693. [DOI] [Google Scholar]
- 41.Cox DA, Halpin J. Conspiracy theories, misinformation, COVID-19, and the 2020 election tech. The Survey Center on American Life. 2020. Oct 13, [2021-07-14]. https://www.americansurveycenter.org/research/conspiracy-theories-misinformation-covid-19-and-the-2020-election/
- 42.Abdool Karim SS, de Oliveira T, Loots G. Appropriate names for COVID-19 variants. Science. 2021 Mar 19;371(6535):1215. doi: 10.1126/science.abh0836.371/6535/1215 [DOI] [PubMed] [Google Scholar]
- 43.Scientific Nomenclature. Centers for Disease Control and Prevention. 2014. [2021-07-14]. https://wwwnc.cdc.gov/eid/page/scientific-nomenclature .
- 44.Hull R, Rima B. Virus taxonomy and classification: naming of virus species. Arch Virol. 2020 Nov;165(11):2733–2736. doi: 10.1007/s00705-020-04748-7.10.1007/s00705-020-04748-7 [DOI] [PubMed] [Google Scholar]
- 45.Masters-Waage TC, Jha N, Reb J. COVID-19, coronavirus, Wuhan virus, or China virus? Understanding how to "Do No Harm" when naming an infectious disease. Front Psychol. 2020;11:561270. doi: 10.3389/fpsyg.2020.561270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Vigsø O. Naming is framing: swine flu, new flu, and A(H1N1) Observatorio. 2010 Jan;4:1. [Google Scholar]
- 47.McCauley M, Minsky S, Viswanath K. The H1N1 pandemic: media frames, stigmatization and coping. BMC Public Health. 2013 Dec 03;13:1116. doi: 10.1186/1471-2458-13-1116. https://bmcpublichealth.biomedcentral.com/articles/10.1186/1471-2458-13-1116 .1471-2458-13-1116 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Sell TK, Hosangadi D, Trotochaud M. Misinformation and the US Ebola communication crisis: analyzing the veracity and content of social media messages related to a fear-inducing infectious disease outbreak. BMC Public Health. 2020 May 07;20(1):550. doi: 10.1186/s12889-020-08697-3. https://bmcpublichealth.biomedcentral.com/articles/10.1186/s12889-020-08697-3 .10.1186/s12889-020-08697-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Singh RP, Valkonen JPT, Gray SM, Boonham N, Jones RAC, Kerlan C, Schubert J. Discussion paper: the naming of Potato virus Y strains infecting potato. Arch Virol. 2008;153(1):1–13. doi: 10.1007/s00705-007-1059-1. [DOI] [PubMed] [Google Scholar]
- 50.Mallapaty S. Should virus-naming rules change during a pandemic? The question divides virologists. Nature. 2020 Aug;584(7819):19–20. doi: 10.1038/d41586-020-02243-2.10.1038/d41586-020-02243-2 [DOI] [PubMed] [Google Scholar]
- 51.Baucom E, Sanjari A, Liu X, Chen M. Mirroring the real world in social media: Twitter, geolocation, and sentiment analysis. Proceedings of the 2013 International Workshop on Mining Unstructured Big Data Using Natural Language Processing; UnstructureNLP '13; October 28, 2013; San Francisco, CA. 2013. Oct, pp. 61–68. https://dl.acm.org/doi/10.1145/2513549.2513559 . [DOI] [Google Scholar]
- 52.Chung T, Pelechrinis K, Faloutsos M, Hylek L, Suffoletto B, Feldstein Ewing SW. Innovative routes for enhancing adolescent marijuana treatment: interplay of peer influence across social media and geolocation. Curr Addict Rep. 2016 Apr 1;3(2):221–229. doi: 10.1007/s40429-016-0095-x. [DOI] [Google Scholar]
- 53.Milusheva S, Marty R, Bedoya G, Williams S, Resor E, Legovini A. Applying machine learning and geolocation techniques to social media data (Twitter) to develop a resource for urban planning. PLoS One. 2021;16(2):e0244317. doi: 10.1371/journal.pone.0244317. https://dx.plos.org/10.1371/journal.pone.0244317 .PONE-D-20-27914 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Williams E, Gray J, Dixon B. Improving geolocation of social media posts. Pervasive Mobile Computing. 2017 Apr;36:68–79. doi: 10.1016/j.pmcj.2016.09.015. [DOI] [Google Scholar]
- 55.Kotler P, Zaltman G. Social marketing: an approach to planned social change. J Mark. 1971 Jul;35(3):3–12. [PubMed] [Google Scholar]
- 56.Mayfield D. Social media algorithms 2021: updates and tips by platform. StoryChief. [2021-07-14]. https://storychief.io/blog/social-media-algorithms-updates-tips .
- 57.Settlage B. Pros and cons of the social media algorithm age. Amplimark. 2021. Feb 17, [2021-07-14]. https://www.amplimark.com/pros-and-cons-of-the-social-media-algorithm-age/2021 .
- 58.Disadvantages of the Facebook algorithm and how you can workaround it. On The Maps! Digital Marketing Company. 2020. Jul 01, [2021-07-14]. https://onthemaps.com/disadvantages-of-the-facebook-algorithm-and-how-you-can-workaround-it/
- 59.Thottam I. Pros and cons of Twitter's new algorithmic timeline. Paste Magazine. 2016. Feb 17, [2021-07-14]. https://www.pastemagazine.com/tech/twitter/pros-and-cons-of-twitters-new-algorithmic-timeline/
- 60.Curvelo R. The pros and Ccons of using Twitter as part of your digital marketing strategy. Matrix Internet. 2020. Feb 28, [2021-07-14]. https://www.matrixinternet.ie/the-pros-and-cons-of-twitter/
- 61.Casper H. Everything you need to know about Twitter's timeline algorithm. Click to Tweet. 2017. Mar 14, [2021-07-14]. https://clicktotweet.com/blog/everything-you-need-to-know-about-twitter-timeline-algorithm .
- 62.Beasing D. Does Facebook's new algorithm add up for radio? Radio World. 2018. Mar 02, [2021-07-14]. https://www.radioworld.com/news-and-business/does-facebooks-new-algorithm-add-up-for-radio .
- 63.Agung N, Darma G. Opportunities and challenges of Instagram algorithm in improving competitive advantage. Int J Innovative Sci Res Technol. 2019 Jan;4(1):1. [Google Scholar]
- 64.Alumnus Marc Faddoul discovers racial biases in TikTok’s algorithm. UC Berkeley School of Information. [2021-07-14]. https://www.ischool.berkeley.edu/news/2020/alumnus-marc-faddoul-discovers-racial-biases-tiktoks-algorithm .
- 65.Mateescu A, Brunton D, Rosenblat A, Patton D, Gold Z, Boyd D. Social media surveillance and law enforcement. Data Civil Rights N Era Policing Justice. 2015 Oct 27;:1–11. http://www.datacivilrights.org/pubs/2015-1027/Social_Media_Surveillance_and_Law_Enforcement.pdf . [Google Scholar]
- 66.Gupta A, Katarya R. Social media based surveillance systems for healthcare using machine learning: a systematic review. J Biomed Inform. 2020 Aug;108:103500. doi: 10.1016/j.jbi.2020.103500. https://linkinghub.elsevier.com/retrieve/pii/S1532-0464(20)30128-3 .S1532-0464(20)30128-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Bizzi L. Should HR managers allow employees to use social media at work? Behavioral and motivational outcomes of employee blogging. Int J Hum Resource Manage. 2017 Nov 14;31(10):1285–1312. doi: 10.1080/09585192.2017.1402359. [DOI] [Google Scholar]
- 68.Alexander Ec, Mader Drd, Mader Fh. Using social media during the hiring process: a comparison between recruiters and job seekers. J Global Scholars Marketing Sci. 2019 Jan 14;29(1):78–87. doi: 10.1080/21639159.2018.1552530. https://digitalcommons.kennesaw.edu/cgi/viewcontent.cgi?article=1203&context=ama_proceedings . [DOI] [Google Scholar]
- 69.Shin J, Valente T. Algorithms and health misinformation: a case study of vaccine books on Amazon. J Health Commun. 2020 May 03;25(5):394–401. doi: 10.1080/10810730.2020.1776423. [DOI] [PubMed] [Google Scholar]
- 70.Juneja P, Mitra T. Auditing e-commerce platforms for algorithmically curated vaccine misinformation. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems; CHI '21; May 8-13, 2021; Yokohama, Japan. 2021. May 06, pp. 1–27. https://dl.acm.org/doi/10.1145/3411764.3445250 . [DOI] [Google Scholar]
- 71.Smith B, Linden G. Two decades of recommender systems at Amazon.com. IEEE Internet Computing. 2017 May;21(3):12–18. doi: 10.1109/mic.2017.72. [DOI] [Google Scholar]
- 72.Krishnamurthy S. A Comparative Analysis of eBay and Amazon. Seattle, WA: University of Washington; 2004. pp. 29–44. [Google Scholar]
- 73.Yuan TT, Chen Z, Mathieson M. Predicting eBay listing conversion. Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval; SIGIR '11; July 24-28, 2011; Beijing, China. 2011. Jul, http://www.bayimage.com/code/Sigir2011_docs_p1335.pdf . [DOI] [Google Scholar]
- 74.Aizawa A. An information-theoretic perspective of tf–idf measures. Inf Processing Manage. 2003 Jan;39(1):45–65. doi: 10.1016/s0306-4573(02)00021-3. [DOI] [Google Scholar]
- 75.Andoni A, Onak K. Approximating edit distances in near-linear time. Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing; STOC '09; May 31-June 2, 2009; Bethesda, MD. 2009. Jul 02, p. 199. [DOI] [Google Scholar]
- 76.Hong I, Rutherford A, Cebrian M. Social mobilization and polarization can create volatility in COVID-19 pandemic control. Appl Netw Sci. 2021;6(1):11. doi: 10.1007/s41109-021-00356-9. http://europepmc.org/abstract/MED/33614902 .356 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Alang N. Clubhouse chat beating social media trolls: for better or worse, site offers conversation among the like-minded. Toronto Star. 2021. Mar, [2021-07-14]. https://www.pressreader.com/canada/toronto-star/20210306/281900185950631 .
- 78.Zhao Y, Nie L, Wang X, Chua T. Personalized recommendations of locally interesting venues to tourists via cross-region community matching. ACM Trans Intelligent Syst Technol. 2014 Oct;5(3):1–26. doi: 10.1145/2532439. [DOI] [Google Scholar]