
Figure 5. Engineering Fluorescent Proteins with Likelihood-Bounded DENs.
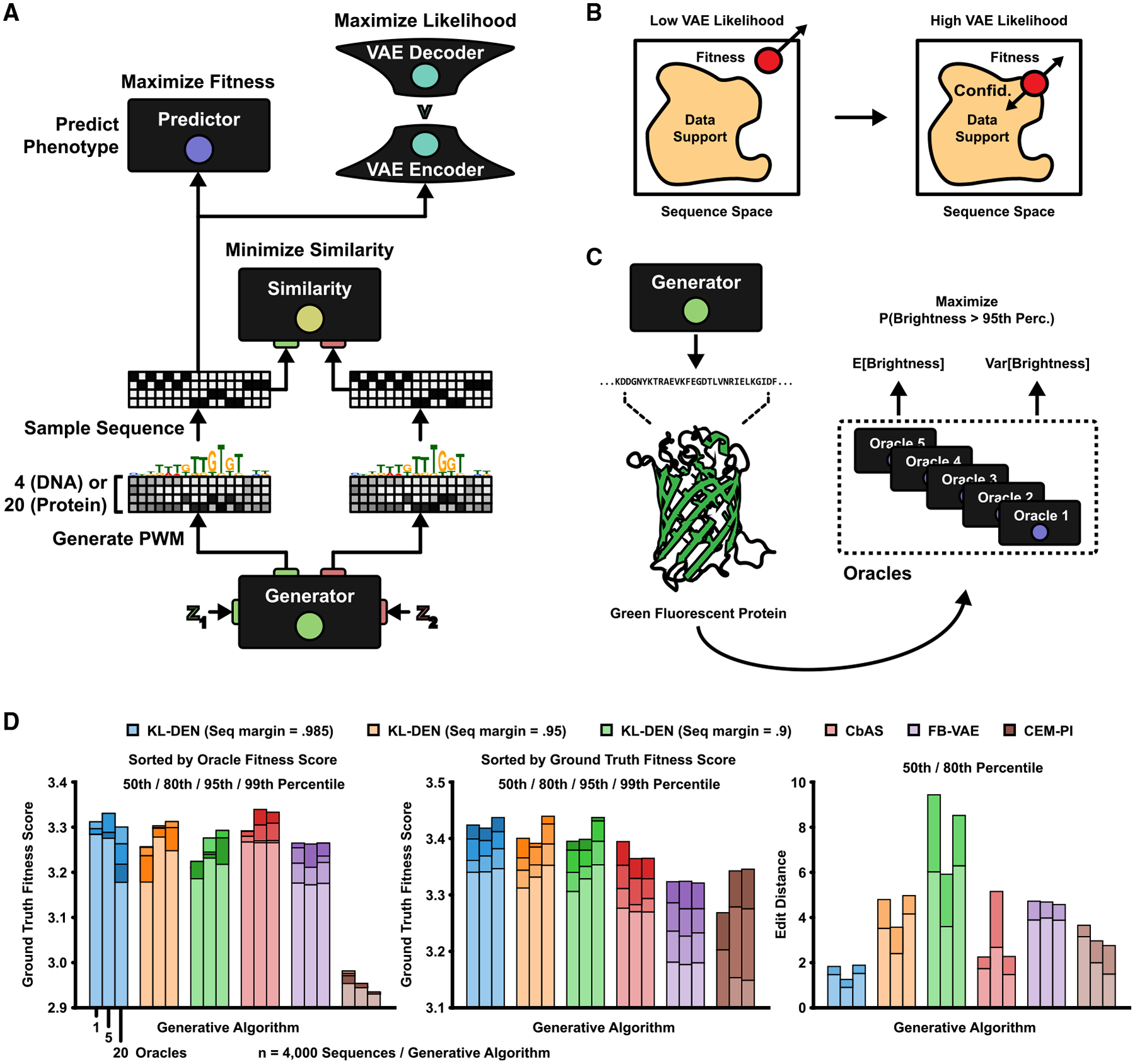
(A) The integration of a VAE in the DEN framework (KL-DEN). The one-hot-coded sequence patterns sampled from the generator are passed to the VAE. Gradients are backpropagated by using a straight-through estimator (Chung et al., 2016).
(B) Left: unbounded DEN optimization along the fitness gradient. Right: bounded optimization with a gradient pointing toward the VAE likelihood of the measured data.
(C) The task is to generate GFP sequence variants that maximize the predicted probability of their brightness being above a target (95th percentile of training data). Predictions are made by using an ensemble of oracles (Lakshminarayanan et al., 2017; Brookes et al., 2019).
(D) GFP benchmark comparison (methods listed in top legend). The KL-DEN was trained with a minimum likelihood ratio margin of 1/10 compared with the median training data likelihood, with three different sequence similarity margins: 98.5%, 95%, and 90%. Each method was used to sample 100 sequences per training epoch, for a total of 40 epochs (after 10 epochs of “warm up” training), resulting in n = 4,000 sequences. (Left) Sequences were sorted on oracle fitness scores. Shown are the “ground truth” scores for the 50th, 80th, 95th, and 99th percentile of oracle scores, as estimated by a GP regression model (Shen et al., 2014). (Middle) The 50th, 80th, 95th, and 99th percentile of ground truth scores (regardless of oracle value). (Right) 50th and 80th percentile of sequence edit distances.
See also Figure S5.