
Fig 1. Overview of the CLAM conceptual framework, architecture and interpretability.
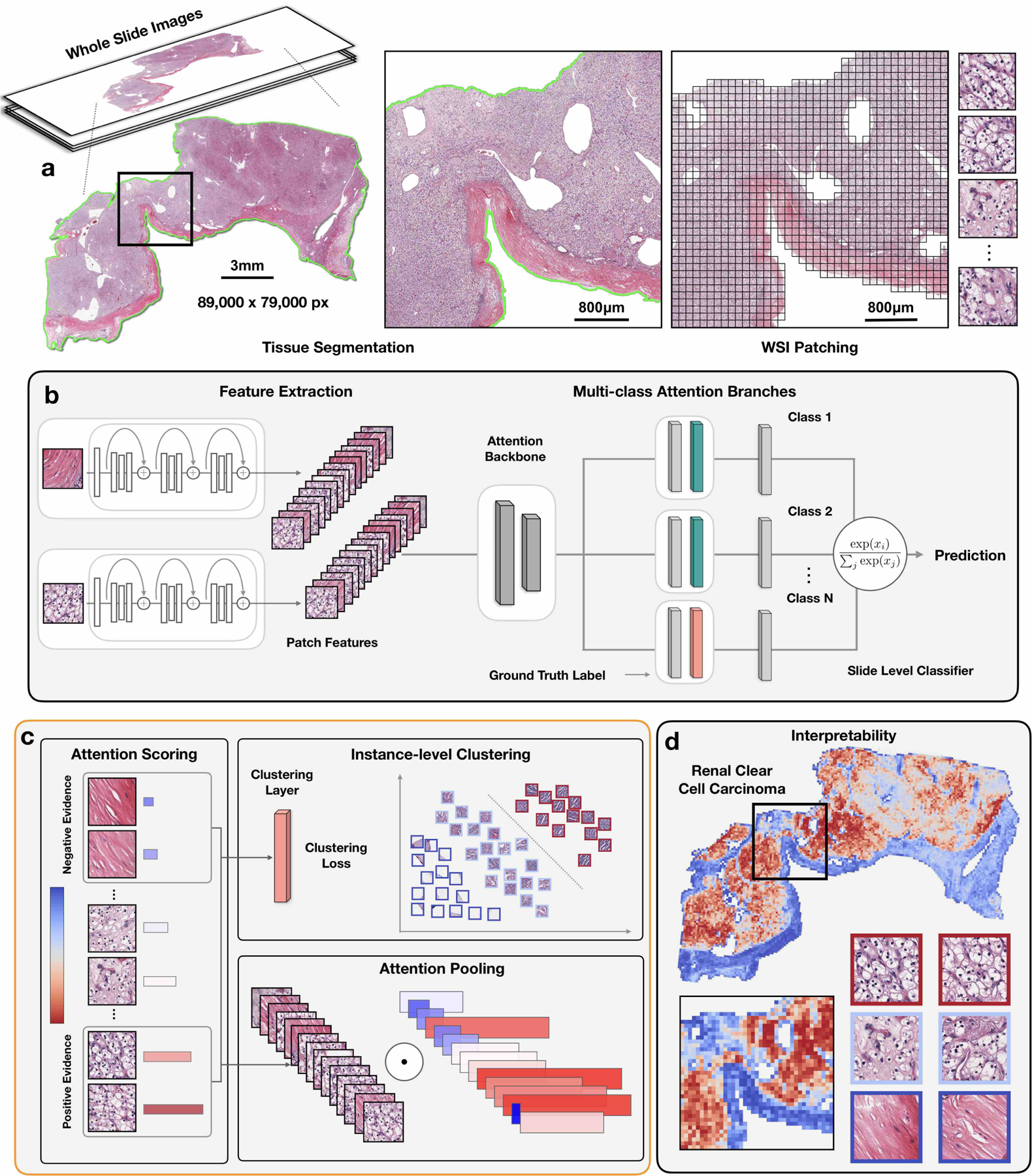
a, Following segmentation (left), image patches are extracted from the tissue regions of the WSI (right). b, Patches are encoded once by a pre-trained CNN into a descriptive feature representation. During training and inference, the extracted patches in each WSI are passed to a CLAM model as feature vectors. An attention network is used to aggregate patch-level information into slide-level representations, which are used to make the final diagnostic prediction. c, For each class, the attention network ranks each region in the slide and assigns an attention score based on its relative importance to the slide-level diagnosis (left). Attention pooling weighs patches by their respective attention scores and summarizes patch-level features into slide-level representations (bottom right). During training, given the ground-truth label, the strongly attended (red) and weakly attended (blue) regions can additionally be used as representative samples to supervise clustering layers that learn a rich patch-level feature space separable between the positive and negative instances of distinct classes (top right). d, The attention scores can be visualized as a heatmap to identify ROIs and interpret the important morphology used for diagnosis.