
Appendix 1—figure 9. Parameter recoverability.
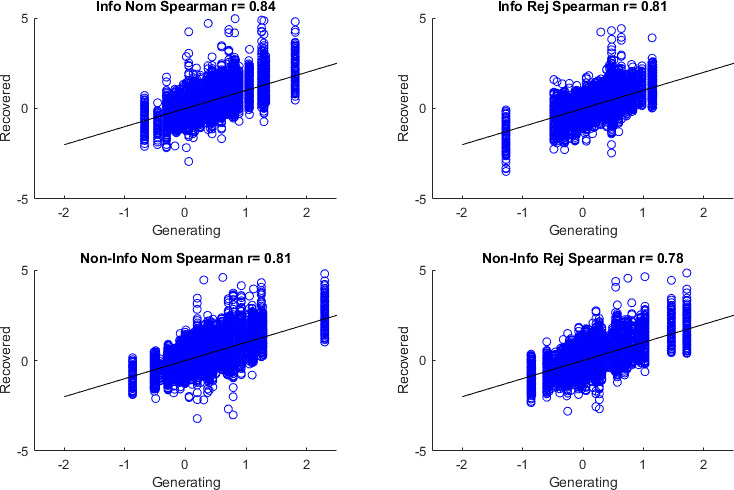
For each of the 2*62 full-model parameter combinations, 1000 synthetic (simulated) datasets were created by simulating the full model on experimental sessions as in the true experiment. Then the full model was fit to each of these generated datasets. For each credit assignment (CA) parameter we plot the recovered against the generating parameters, report the Spearman correlation and impose black diagonals where ‘recovered = generating’. (A) Model-free CA (MFCA) on standard trials, (B–E) MFCA on uncertainty trials; (B) informative outcome, ghost-nominated, (C) informative outcome, ghost-rejected, (D) non-informative outcome, ghost-nominated, (E) non-informative outcome, ghost-rejected, (F) model-based CA (MBCA).