
Figure 2. Model-free (MF) and model-based (MB) contributions.
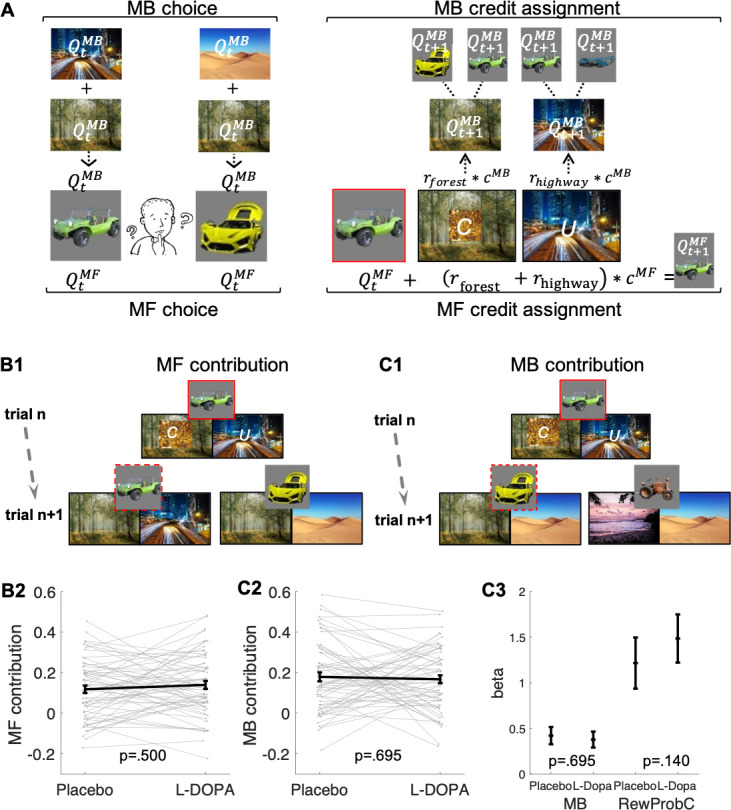
(A) Left panel: Illustration of MF and MB values at choice in standard trials. MB values are computed prospectively based on the sum of values of the two destinations associated with each of the two vehicles offered for choice (here highway and forest for green antique car; desert and forest for yellow racing car). Right panel: MF vs. MB credit assignment (MFCA vs. MBCA) in standard trials. MFCA only updates the chosen vehicle (here green antique car) based on the sum of rewards at each destination (here forest and highway). MBCA updates separately the values for each of the two destinations (forest and highway). Each of these updates will prospectively affect equally the values of the vehicle pair associated with that destination (updated MB value for forest influences MB value of the yellow racing car and the green antique car while the updated MB value for highway influences the MB value of the green antique car and the blue crane). Forgetting of Q values was left out for simplicity (see Materials and methods and see Appendix 1—figure 1 for validating simulations). (B1) Illustration of MF choice repetition. We consider only standard trials n + 1 that offer for choice the standard trial n chosen vehicle (e.g., green antique car) alongside another vehicle (e.g., yellow racing car), sharing a common destination (forest). Following choice of a vehicle in trial n (framed in red, here the green antique car), participants visited two destinations of which one can be labelled on trial n + 1 as common to both offered vehicles (C, e.g., forest, which was also rewarded in the example) and the other labelled as unique (U, e.g., city highway, unrewarded in this example) to the vehicle chosen on trial n (the green antique car). The trial n common destination reward effect on the probability to repeat the previously chosen vehicle (dashed frame in red, e.g., the green antique car) constitutes an MF choice repetition. (B2) The empirical reward effect for the common destination (i.e., the difference between rewarded and unrewarded on trial n, see Appendix 1—figure 2 for a more detailed plot of this effect) on repetition probability in trial n + 1 is plotted for placebo and levodopa (L-Dopa) conditions. There was a positive common reward main effect and this reward effect did not differ significantly between placebo and levodopa conditions. (C1) Illustration of the MB contribution. We considered only standard trials n + 1 that excluded from the choice set the standard trial n chosen vehicle (e.g., green antique car, framed in red). One of the vehicles offered on trial n + 1 shared one destination in common with the trial n chosen vehicle (e.g., yellow racing car, sharing the forest, and we term its choice a generalization). A reward (on trial n) effect for the common destination on the probability to generalize on trial n + 1 (e.g., by choice of the yellow racing car, dashed frame in red) constitutes a signature of MB choice generalization. (C2) The empirical reward effect at the common destination (i.e., the difference between rewarded and unrewarded, see Appendix 1—figure 2 for a more detailed plot of this effect) on generalization probability is plotted for placebo and levodopa conditions. (C3) In the regression analysis described in the text, we also include the current (subject- and trial-specific) state of the drifting reward probabilities (at the common destination) because we previously found this was necessary to control for temporal auto correlations in rewards (Moran et al., 2019). For completeness, we plot beta regression weights of reward vs. no reward at the common destination (indicated as MB) and for the common reward probability (RewProbC) each for placebo and levodopa conditions. No significant interaction with drug session was observed. Error bars correspond to SEM reflecting variability between participants.