
Figure 3.
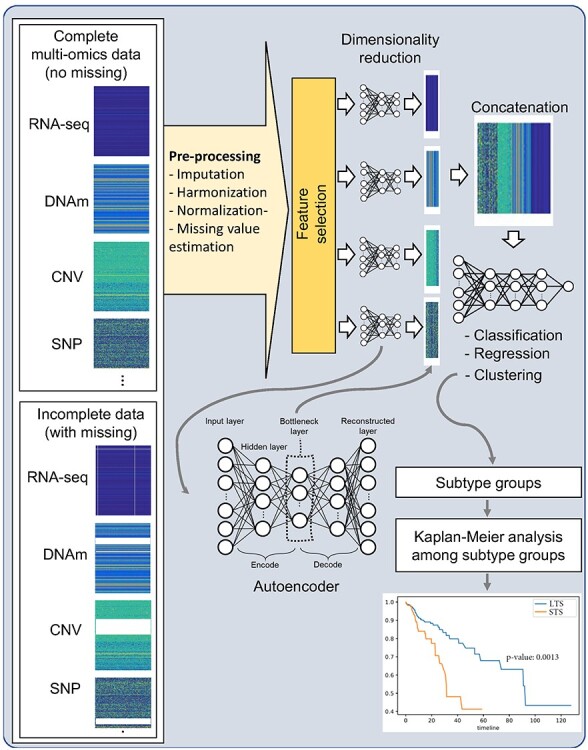
Pipeline of multi-omics data integration analyses: (1) complete or incomplete multi-omics data are cleaned by preprocessing; feature selection or dimensionality reduction is applied to reduce numbers of multi-omics variables; (3) autoencoder is a DL model that extracts low-ranked latent variables of the input data in a bottleneck layer; (4) multi-omics variables are concatenated into a large dataset for data integration; (5) further feature selection or reduction techniques are applied; (6) the integrated data are analyzed for desired tasks, such as classification, regression and clustering and (7) finally, subtypes discovered by clustering analysis re evaluated with the Kaplan-Meier analysis.