

Abstract
A novel intelligent diagnostic system is proposed to diagnose heart sounds (HSs). The innovations of this system are primarily reflected in the automatic segmentation and extraction of the first complex sound and second complex sound ; the automatic extraction of the secondary envelope-based diagnostic features , , and from and ; and the adjustable classifier models that correspond to the confidence bounds of the Chi-square () distribution and are adjusted by the given confidence levels (denoted as ). The three stages of the proposed system are summarized as follows. In stage 1, the short time modified Hilbert transform (STMHT)-based curve is used to segment and extract and . In stage 2, the envelopes and for periods and are obtained via a novel method, and the frequency features are automatically extracted from and by setting different threshold value () lines. Finally, the first three principal components determined based on principal component analysis (PCA) are used as the diagnostic features. In stage 3, a Gaussian mixture model (GMM)-based component objective function is generated. Then, the distribution for component k is determined by calculating the Mahalanobis distance from to the class mean for component k, and the confidence region of component k is determined by adjusting the optimal confidence level and used as the criterion to diagnose HSs. The performance evaluation was validated by sounds from online HS databases and clinical heart databases. The accuracy of the proposed method was compared to the accuracies of other state-of-the-art methods, and the highest classification accuracies of , , , , , 99.67 and 99.91 in the detection of MR, MS, ASD, NM, AS, AR and VSD sounds were achieved by setting to 0.87,0.65,0.67,0.65,0.67,0.79 and 0.87, respectively.
Subject terms: Cardiology, Health care, Engineering, Mathematics and computing
Introduction
Background
As an efficient method, using heart sound (HS) analysis is often used to evaluate heart function; this approach has been widely used to diagnose heart disease and evaluate heart functions, such as congenital heart disease classification1, ventricular septal defect detection2, blood pressure estimation3 and congenital heart disease screening4, for children and adults. A normal HS is primarily composed of two basic sounds: the first sound () which is generated by the closing of aortic valves and the vibrations associated with tensing of the chordate trendiness and the ventricular walls, the second sound () is produced by the closure of the aortic and pulmonic valves at the beginning of is volumetric ventricular relaxation. However, HSs with unitary murmurs generally occur between and with different noise patterns5. Therefore, analyses of , , and the period between and play important roles in characterizing HS features with different types of information. Detailed information for , , and the sounds between and can be used to accurately classify HS. Additionally, to avoid analyzing the sounds between and , which are generally segmented from HSs with low accuracy, and part of the period between and are integrated to obtain , and and the part of the period between and are integrated to form . Then, the features are efficiently extracted from and . Finally, a classification method is established to diagnose heart diseases.
Need for research
and extraction The studies regarding HS segmentation can be summarized into two branches: one branch includes studies that segment each cardiac cycle into a sequence of four heart stages: Systole period Diastole period6,7. As a result, the four fundamental stages to be segmented are different due to the nonstationary nature of an abnormal HSs signal and the effect of background noise. The other branch includes studies that segment a periodic HSs into a sequence of two heart stages, which are expressed as based on the STMHT algorithm; this approach was reported to be successfully applied in diagnosing heart diseases, such as in ventricular septal defect (VSD) diagnosis8 and several kinds of heart disease diagnosis9. Moreover, study9 noted that the use of frequency features was more efficient in distinguishing normal from abnormal sounds than was the use of time features. Therefore, an efficient frequency feature extraction method should be developed.
Feature extraction As an important component of efficient feature extraction, the frequency width of the envelope over a given threshold value () has been verified to be useful for detecting heart diseases8–11. However, for many types of HSs, it is difficult to extract frequency widths with an unsuitable due to the existence of a non smooth envelope. To extract the frequency widths for a smooth envelope without setting different values, the smooth envelope can be treated as a secondary envelope, as proposed in9, and used to automatically extract the frequency feature matrix based on the STMHT technique; this method was successfully applied to detect different types of heart diseases. However, for mitral stenosis and mitral regurgitation noises, the feature matrix was not easily extracted because the second frequency component was missing. Therefore, to improve the classification accuracy for diagnosing different types of heart disease and simplify the complexity of the diagnostic method, the smooth envelopes for and extraction in the frequency domain must be considered; additionally, more frequency widths corresponding to different values should be used, and dimensionality reduction should be employed to reduce the number of features considered . Such a classification method could be applied in the efficient extraction of features for diagnosing heart diseases.
Classifier model Gaussian mixture models (GMMs) have been used in a wide variety of clustering applications12–18 due to their powerful mathematical characteristics. Confidence regions are used to diagnose the detection data x in GMMs, and the optimal confidence regions is determined based on Mahalanobis distance following the Chi-square () distribution. Thus, classifier models with adjustable sizes corresponding to the confidence bounds of the Chi-square () distribution, which can be adjusted by changing the desired confidence level (denoted as ), are proposed. The confidence bounds used as the classification criteria are employed to diagnose heart diseases.
Major contributions and organization
In summary, this study proposes an innovative and intelligent system. The major contributions in this study are (1) the STMHT-based and are automatically located and extracted; (2) a novel method for obtaining the secondary curves of and are extracted in the frequency domain; (3) frequency features are automatically extracted over the given threshold value; (4) the diagnostic features , and are determined based on PCA; and (5) the confidence region of the distribution, which are adjusted based on the desired , is determined and used as the classification criterion for diagnosing a given HS. The remainder of this paper is organized as follows. Section “Methodology” presents the approach for determining the diagnostic features , and a definition of the confidence region-based diagnostic method for diagnosing heart diseases. In “Performance evaluation” section, the performance of the proposed method is compared with that of other efficient methods for diagnosing heart diseases. In “Conclusion” section, the conclusions are provided. Finally, the future study is pointed out in “Future study”.
Methodology
This study was approved by the ethics committee of Nanyang Institute of Technology (Approval Number:2016-06) and the informed consent was waived by the ethics committee of Nanyang Institute of Technology. The present study was also conducted in accordance with the tenets of the 1975 Declaration of Helsinki, as revised in 200819.
The flow chart of the proposed intelligent system, shown in Fig. 1, consists of three stages: the automatic location and extraction of and ; the automatic determination of frequency features , and ; and the establishment of the Mahalanobis distance criterion-based diagnostic method. In stage 1, the STMHT-based curve (denoted as ), which is extracted for the envelope generated by the HS, is used to segment and extract and from the HS (Fig. 1A). In stage 2, the envelopes and for every period and are obtained via a novel method, and the frequency features are automatically extracted from and by setting different lines. Finally, the first three principal components, , and , which express of the information, are determined and used as diagnostic features (Fig. 1B, C). In stage 3, the GMM-based mixed classification objective function which combines component k with respect to the parameters , , and and the features , is generated. Then, the distribution for component k is determined by calculating the Mahalanobis distance from x to the class mean of component k, and the adjustable confidence bound (denoted as shown in Fig. 1E) is determined to diagnose heart diseases.
Figure 1.

Flow chart of the proposed methodology.
Stage 1: Automatic extraction of and
As shown in Fig. 2, five steps consisting of heart sound auscultation, heart sound preprocessing, heart sound envelope extraction, STMHT extraction, and and extraction, which is used to construct the procedure of the and extraction and is detailed in the following steps.
Figure 2.
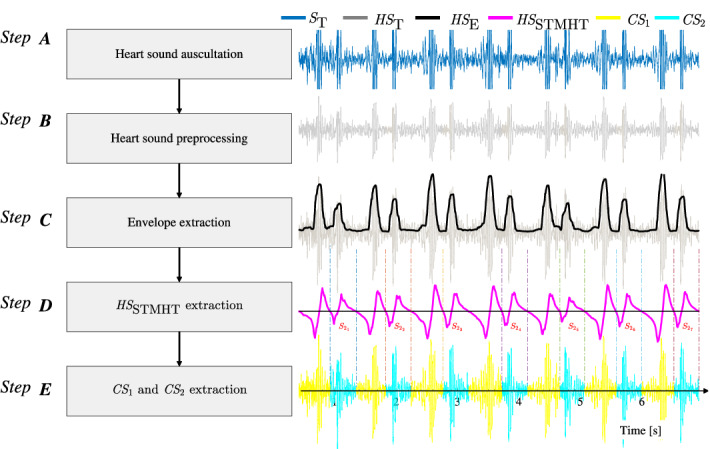
Flow chart of the and extraction.
Step A: Heart sound auscultation
Auscultation is performed for the purposes of examination cardiovascular. As described in previous study8, the original heart sound, denoted as (colored in blue line as shown in Fig. 2), are collected by 3M-3200 electronic stethoscope with a Hz sample rate which is widely used by many doctors and produced by American 3M company20, and the tricuspid area is selected as the auscultation area due to the tricuspid area reported to supply more important information21. Meanwhile, you can hear the sounds when auscultating heart sounds, ensuring that we avoid as much environmental noise as possible during the auscultation procedure. Even so, the collected heart sounds still need to be preprocessing for canceling the invalid components.
Step B: WD-based heart sound preprocessing
HSs are reported to be primarily dispersed in the frequency range of 20700 Hz2,8,9. Therefore, according to the sampling frequency ( kHz), WD-based HSs are filtered to obtain the efficient frequency components ( Hz). The Daubechies wavelet 10 (dB10) has been used to give the maximum signal-to-noise ratio and minimum root-mean-square error for HSs22. Therefore, dB10 is selected for use as the mother wavelet for preprocessing HSs. A filtered and normalized sound, colored by gray and denoted as , is shown in Fig. 2.
Step C: heart sound envelope extraction
The Viola integral-based envelope, denoted as , is extracted from the heart sound , as reported in studies8,9; this envelope can effective overcome amplitude variations and complex backgrounds and noise. This concept is described as follows. Consider a filtered sound for , where M denotes the number of HSs. In a neighborhood of time m, called the width time scale, the M-point envelope is obtained by Eq. (1):
| 1 |
where
| 2 |
if the duration of or greater than 0.13 s. Finally, normalization is performed by setting the maximum amplitude of to 1 (Fig. 2).
Step D: STMHT extraction for HS
Given an M-point HS, the STMHT for the HSs , , is computed from Eq. (3)
| 3 |
| 4 |
where , and is a moving window of odd length N. According to studies2,8, the length N is set to 44101.
Step E: Automatic extraction of and
The characteristics of considered in studies2,8, as shown in Fig. 3A, C, are summarized as follows: The negative-to-positive (N2P) points of , denoted by , correspond to the geometry center peaks of and ; The geometry center between and , denoted by is determined by the positive-to-negative P2N points of . Moreover, the interval from to is generally greater than that from to in one period of an HS23–25. Therefore, the N2P and P2N-based and features can be automatically segmented from one period of an HS and extracted by two procedures, as described as follows.
- (1)
-
and location
The algorithm for detecting and is detailed as follows.
- First, the signum function of , denoted as , is calculated by
5 - Then, the variation in () is determined from Eq. (6)
6 - Finally, N2P and P2N are determined by
7
- (2)
Automatic extraction of and
- Calculate the difference between two adjacent N2Ps, denoted as , with Eq. (8)
8 - Determine the points and that are used for segmentation from to and from to , respectively, by using Eq. (9).
9 - Extract (denoted as ) and (denoted as ) for the ith period of an HS as follows
10
The automatic extraction procedures for and are illustrated in Fig. 3. Figure 3(A, B) show a typical AR sound, and the typical NM sound is shown in Fig. 3(C, D).
Figure 3.

The automatic extraction procedures for and . A-B show the procedure for an example of a typical AR from the database in26. C-D show the procedure for an example of a typical normal sound database27.
Stage 2: Automatic feature generation
Feature definition
To extract the efficient frequency widths, as shown in Fig. 4, the smooth envelopes for and in the frequency domain are firstly generated, and then the frequency widths corresponding to different Thv values are extracted.
- (1)
- Secondary envelopes and generation: Given an M-point HS, the secondary envelope in the frequency-domain, denoted as , can be calculated from Eq. (11):
where , and are defined by Eq. (12):11
is the absolute value sign, is the first window width, and is the second window width. According to studies9,28, and are set to 9 and 17, respectively. Moreover, is also normalized by setting the maximum amplitude of to 1. The secondary envelopes for and , denoted as and respectively, are illustrated by using the examples described in Fig. 3 which are first automatically generated based on Eq. (11), are shown in Fig. 4, where the plots in Fig. 4A.2 describe the results of corresponding to in Fig. 4A.1, the plots in Fig. 4B.2 describe the results of which corresponds to in Fig. 4B.1, the plots in Fig. 4A.3 describe the results of corresponding to in Fig. 4A.1, and the plots in Fig. 4B.3 describe the results of which corresponds to in Fig. 4B.1.12 - (2)
- Definition and automatic extraction of frequency features: The frequency features are illustrated in Fig. 4(B, C), and their gravities are calculated by
13
The frequency widths over a given threshold value are defined and calculated by
| 14 |
where and are the left and right intersections, respectively, of and over the lines (=0.3, 0.5 and 0.8). Moreover, the frequency features are expressed based on Eq. (15) and described in Table 1.
| 15 |
Figure 4.

Example of feature definition and automatic extraction.
Table 1.
Description of the frequency domain feature matrix .
| Feature index | Feature’s symbol | Feature description | Unit |
|---|---|---|---|
| 1 | The frequency width of corresponding to | Hz | |
| 2 | The frequency width of corresponding to | Hz | |
| 3 | The frequency width of corresponding to | Hz | |
| 4 | The Center of gravity of in frequency-domain | Hz | |
| 5 | The frequency width of corresponding to | Hz | |
| 6 | The frequency width of corresponding to | Hz | |
| 7 | The frequency width of corresponding to | Hz | |
| 8 | The Center of gravity of in frequency-domain | Hz |
Experimental results for several typical types of heart disease
The features of six typical and normal sounds are illustrated in Fig. 5. From Fig. 5, and are first automatically located and extracted, then, the envelopes for every and are extracted by Eq. (11). Finally, the features defined by Eq. (15) for and in the frequency domain are automatically extracted with Eqs. (13-14). The experimental sounds are 665-period AR sounds (3M database29, medical sound library30, heart auscultation sounds31, auscultation sound32, continuing medical implementation26, sounds Database of the University of Dundee27, and patients only with AR disease from the Nanyang First People’s Hospital), 381-period AS sounds (continuing medical implementation26, sounds database of the University of Dundee27, 3M database29, medical sound library30, auscultation sound32, and patients only with AS disease from the Nanyang first People’s Hospital, and heart auscultation sounds31), 315-period ASD sounds (Medical sound library30, heart auscultation sounds31, 3M database29, patients only with ASD disease from the Nanyang First People’s Hospital, and medical sound library30), 769-period MR sounds (3M database29, sounds database of the University of Dundee27, heart auscultation sounds31, medical sound library30, and auscultation sound32), 439-period MS sounds(3M database29, auscultation sound32, medical sound library30, and continuing medical implementation26), and 1056-period NM sounds(3M database29, Michigan database33, medical sound library30, ThinkLabs database34, and healthy undergraduates from Nanyang Institute of Technology, China)(whom I thank for the data used in this study)). Moreover, the boxplots for the features are plotted in Fig. 6, where Fig. 6A shows the features extracted from and Fig. 6B shows the features from for each type of heart disease. The scatter plots of features in Fig. 6 illustrate the discrimination ability of the model in distinguishing among different heart diseases and highlighting the following findings: The MS and VSD sounds are easy to distinguish from the other sounds by using (Fig. 6A), and by using the (Fig. 6B), the VSD sound is easy to distinguish from the other sounds; The MS sound is easy to distinguish from the other sounds based on (Fig. 6A), and by using the (Fig. 6B), the AR and VSD sounds are distinguished from other sounds; The NM sound is easy to distinguish from other sounds using (Fig. 6A). The AR and VSD sounds are easy to distinguish from the other sounds using , as shown in Fig. 6B; Fig. 6A indicates that can be used to easily distinguish MR from other sounds and the AS and ASD sounds from other sounds; Fig. 6B shows that the distribution of from AS sounds is different from that for other sounds, except NM sounds. The analysis results discussed above indicate that different combinations of several features defined by Eq. (15) can be used to distinguish among various types of heart disease. Therefore, to simplify features and develop a diagnostic method that is simple and effective, dimension reduction is used to determine new features; this process is described in detail as follows. 
Figure 5.

Examples of a typical normal sound and six types of typical heart disease sounds.
Figure 6.

Box plot representation of FF for each type of heart disease. A shows the box plots for features from . In addition, B represents the features from .
Diagnostic feature determination
To simplify the computation when using features to diagnose heart diseases, PCA, a linear dimensionality reduction technique for finding principal components and replacing high-dimension data in many studies, such as studies on heart arrhythmias classification35, heart disease classification2,36, emotion recognition37, respiratory rate extraction38 and electrocardiogram heart disease diagnosis39, is employed to generate a few efficient principal components to characterize HS features and diagnose heart diseases. The algorithm corresponding to the generation of new features via PCA for a given data set FF is described as Algorithm 1. The eigenvector in Algorithm 1 , which corresponds to the eigenvalue and is calculated for the matrix Z in step 2, as shown in Table 3, is the actual weighted coefficient for the ith principal component . Table 3 shows that the largest absolute coefficients in the first principal component are , and ; the second principal component is mainly weighted based on , , and ; and the third component is mainly weighted based on , and (Table 3). To determine the smallest number of principal components m should be considered, the Pareto chart is used; this chart provides a tool for visualizing the Pareto principle, which states that observing a small set of variables that influence a common outcome is more common than detecting many variables that influence the same outcome. This approach has been used to determine the percent variability explained by each principal component (Fig. 7A). Therefore, according to the smallest m value such that 40, combined with the scatter plot for the first m principal components, the smallest m is determined. The Pareto chart of the PCA results in Fig. 7A shows the explained variance and accumulated variance for each principal component , where . According to Fig. 7A, of the total variance is captured by the first two components, and , and of the total variance is captured by the first three components , and . Therefore, the following conclusions can be obtained.
and lead to a dimensionality reduction of (from 8 to 2 variables) and only information loss. The scatter diagram of and given in Fig. 7B indicates that although the distribution region corresponding to each type of heart disease is obviously different and the overlaps between MR and other diseases, AR and other diseases, and VSD and other diseases are small, the overlaps among MS, ASD, NM, and AS are relatively large; therefore, it is difficult to accurately distinguish among these four types of heart diseases.
However, the scatter diagram of , and , plotted in Fig. 7C, shows that there are different distribution regions for these types of heart diseases. In addition, , as shown in Fig. 7A, based on feature number determination40. Thus, , and lead to a dimensionality reduction of (from 8 to 3 variables) with only information loss. The scatter diagram of , and in Fig. 7C is used to verify the different distribution regions corresponding to these types of heart diseases.
Therefore, m is set to 3, and the new 3-dimensional feature matrices consisting of , and (see Fig. 7C) are used to diagnose heart diseases.
Table 3.
Eigenvector and eigenvalue for in descending order of eigenvalues.
| Features | Eigenvector (eigenvalue) in descending order of eigenvalues | |||||||
|---|---|---|---|---|---|---|---|---|
| 0.4309 | -0.2169 | 0.0818 | -0.2179 | 0.8062 | -0.2394 | -0.0499 | 0.0616 | |
| 0.3716 | -0.0757 | 0.5303 | 0.0431 | -0.0306 | 0.6778 | 0.2873 | -0.1735 | |
| 0.3411 | -0.0983 | 0.5431 | 0.0444 | -0.4364 | -0.6126 | -0.1001 | -0.0375 | |
| 0.2385 | 0.6501 | -0.0157 | -0.2122 | 0.0212 | 0.0986 | -0.5500 | -0.4031 | |
| 0.3313 | 0.0487 | -0.2471 | 0.8958 | 0.0977 | -0.0299 | -0.0699 | -0.0944 | |
| 0.4475 | -0.2390 | -0.2924 | -0.1628 | -0.3044 | 0.2633 | -0.3928 | 0.5607 | |
| 0.3517 | -0.2191 | -0.5142 | -0.2650 | -0.2357 | -0.1047 | 0.3750 | -0.5353 | |
| 0.2632 | 0.1026 | -0.0768 | -0.0662 | -0.0207 | -0.1308 | 0.5506 | 0.4386 | |
Figure 7.

PCA results. A shows the Pareto chart of the variance by contribution of each principal component, B plots the scatter diagram of the first two components and , and C shows the first three components , and .
Stage 3: classification based on the squared Mahalanobis distance criterion
Classifier determination
The squared Mahalanobis distance classification criterion-based diagnostic methodology, consisting of the five sequential steps as shown in the flow chart (Fig. 8A), is proposed to diagnose HSs and is described in the following 5 steps.
Figure 8.

Flow chart of the diagnostic determination and 3-dimensional surface classifier results.
Step 1: GMM-based and generation
In the design step of GMM, the estimated target function, , is a mixture of d-dimensional normal Gaussian distributions that reflect the training pattern of each component; it is assumed that components can be modeled by mixtures of normal Gaussian distributions by
| 19 |
where
| 20 |
expresses the posterior probabilities corresponding to each component; K is the number of components; corresponds to the mixed weights, such that ; and and are the mean value and covariance matrix of the component, respectively. Because the goal is to maximize the function , the parameters (, , and ) are determined based on the EM algorithm41 for a set of sample records. Based on the types of heart disease described in Sect. 2.2 and the scatter diagram plotted in Fig. 7C, the number of Gaussian mixture components is set to , and the fitgmdist function in MATLAB 2018b is used to return a GMM with components fitted to the features established in Sect. 2.2 using the EM algorithm by assigning a posterior probability to each component density with respect to each observation. Furthermore, the regularization value is set as 0.01 to avoid ill-conditioned covariance estimates, and the number of optimization iterations is set to 1000 based on experience. The Gaussian mixture parameter estimates for and are obtained and shown in Table 4. To characterize the 3-dimensional interspace corresponding to each 3-dimensional Gaussian component for diagnosing heart diseases, the 3-dimensional interspaces can be used as 3-dimensional classifiers to diagnose heart diseases with high classification accuracy; the overlapping interspace between two random components is made as small as possible, and the independent 3-dimensional interspace corresponding to each component is considered.
Table 4.
The Gaussian mixture parameter estimates are achieved for the new features by setting the number of Gaussian mixture components as 7.
| Components | Component number | Gaussian mixture parameter estimates | ||||||
|---|---|---|---|---|---|---|---|---|
| MR Classifier | 0.1947 | 0.7056 | 2.7126 | 1.4950 | 0.0425 | -0.0007 | 0.0013 | |
| -0.0007 | 0.2343 | -0.0126 | ||||||
| 0.0013 | -0.0126 | 0.2122 | ||||||
| MS Classifier | 0.0827 | 3.2981 | -2.6064 | -3.7382 | 0.3310 | -0.0094 | -0.0122 | |
| -0.0094 | 0.3906 | -0.0210 | ||||||
| -0.0122 | -0.0210 | 0.5386 | ||||||
| ASD Classifier | 0.1130 | 2.3453 | -0.3484 | 0.5773 | 0.5373 | -0.0172 | -0.0039 | |
| -0.0172 | 0.0608 | -0.0053 | ||||||
| -0.0039 | -0.0053 | 0.1883 | ||||||
| NM Classifier | 0.1683 | 2.7874 | 1.8620 | -0.9829 | 0.1403 | 0.0107 | 0.0063 | |
| 0.0107 | 0.2549 | 0.0016 | ||||||
| 0.0063 | 0.0016 | 0.1301 | ||||||
| AS Classifier | 0.0783 | 0.7511 | 0.3199 | -0.5341 | 0.0972 | 0.0077 | -0.0161 | |
| 0.0077 | 0.0344 | -0.0050 | ||||||
| -0.0161 | -0.0050 | 0.2634 | ||||||
| AR Classifier | 0.2676 | -1.2294 | 0.1198 | 0.3222 | 0.3301 | -0.0011 | 0.0025 | |
| -0.0011 | 0.0230 | 0.0005 | ||||||
| 0.0025 | 0.0005 | 0.3255 | ||||||
| VSD Classifier | 0.0954 | -0.1631 | -1.1167 | 0.9454 | 0.1338 | 0.0048 | -0.0155 | |
| 0.0048 | 0.1449 | -0.0095 | ||||||
| -0.0155 | -0.0095 | 0.1573 | ||||||
Step 2: determination for the component in 3-dimensional interspace
Since the squared Mahalanobis distances for each Gaussian component follow the Chi-square distribution () in 3-dimensional interspace, to determine the decision region for classifying the test data x via the components estimated in the above step, the squared Mahalanobis distance in 3-dimensional interspace for the component with mean and full covariance matrix , , is computed as follows:
| 21 |
Therefore, , which is constructed based on component k and denoted as , is determined by
| 22 |
Therefore, the squared Mahalanobis distance specified based on the desired confidence level, denoted as , can be used as the kth classifier criterion for determining whether feature x belongs to the kth class.
Step 3: The confidence level determination
Actually, the kth confidence region, as specified by the kth desired confidence level , is surrounded by the kth ellipsoid, and this relation is expressed as
| 23 |
where is the inverse of for a given confidence level , and represents the classification criterion for component k and satisfies the following equation
| 24 |
For the distribution, although the confidence regions corresponding to the confidence levels of , , and are widely used classification criteria in many studies2,42–45, the optional is identified by setting combined with the following rules: 1) each ellipsoid should be as large as possible; 2) each common region should be as small as possible; and 3) the classification accuracy defined in Eq. (26) should be as high as possible. The classification accuracies for classifying sound data summarized in Sect. 2.2 are plotted in Figs. 9, and 9 shows the following results: For VSD sounds, high accuracy can be achieved by setting the desired confidence level to each value within the interval of (), as shown in Fig. 9(VSD); For AR and MR sounds, by setting the desired confidence level based on , high classification accuracy could be achieved (Fig. 9(MR and AR) ); For MS, AS and NM sounds, to achieve the accurate classification of HSs, the interval of the desired confidence level should be set as [0.63, 0.65] (Fig. 9); For ASD sounds, Fig. 9(ASD) shows that the highest classification accuracy is achieved by setting the desired confidence level to . Furthermore, the desired confidence level can be adjusted to improve the classification accuracy and fit new datasets without reperforming the computations for the objective function, especially for VSD sounds and MR sounds (Fig. 9(VSD and MR)). In this study, according to the rules described above combined with the accuracy analysis results plotted in Fig. 9, the values are set as 0.87, 0.65, 0.67, 0.65, 0.67, 0.79 and 0.87, respectively.
Figure 9.

The achieved accuracies corresponding to classifying the heart sounds described in Sect. 2.2 by setting form 0.63 to 0.97 with a step of 0.02.
Step 4: determination corresponding to
Based on the confidence level achieved for in the above step, by using the function ’chi2inv’ in MATLAB 2018b, the inverse of , denoted as , is determined. The analysis results for the confidence region in the 3-dimensional interspace, which is surrounded by the ellipsoid corresponding to the desired confidence level , are determined and shown in Fig. 8B. Furthermore, Fig. 8B shows that the common regions between two random ellipsoids are almost zero; thus, a faulty decision process is avoided because the input will not fall into two or more categories.
Step 5: -based diagnostic result determination
Based on the ellipsoid surfaces region shown in Fig. 8B, the diagnosis method is described as follows.
- The 3-dimensional diagnostic features [, , ] are first transformed from the features FF (denoted as ) of the testing sample and calculated with the following equation
where and are shown in Table 2.25 Then, according to the confidence region shown in Fig. 8B, the -based diagnostic result for a test features is determined.
- -based diagnostic results for a test feature are determined by
where class k corresponding to the type of heart disease is detailed in Table 4, and (1, 2, , 7) is 5.6489, 3.2831, 3.4297, 3.2831, 3.4297, 4.5258 and 5.6489.26
Table 2.
Mean () and standard deviation () of the features.
| Statistics | Frequency features () | |||||||
|---|---|---|---|---|---|---|---|---|
| Features from | Features from | |||||||
| 45.3± 11.8 | 33.1± 5.8 | 18.8± 3.6 | 80.6± 21.7 | 44.1± 23.1 | 32.2± 9.1 | 79.8±18.9 | ||
Performance evaluation criteria
To evaluate the performance of these ellipsoids in 3-dimensional space, the classification accuracy (), sensitivity () and specificity () values are calculated by
| 27 |
where , , and are the numbers of true positives, false positives, true negatives and false negatives, respectively.
Performance evaluation
To evaluate the performance of the proposed methodology, the comparison between the proposed methodology and the state-of-the-art methods on the clinical sounds and online sounds data was conducted as follows.
Total sounds: The total sounds, consisting of sounds described in Sect. 2.2 and new sounds, were summarized in Table 5 to evaluate the performance of this proposed methodology.
State-of-the-art methods: To highlight the efficiency of the proposed methodology for diagnosing the seven typical heart diseases, the state-of-the-art methods, published in recent five years and described in Table 6, were comparatively analyzed.
Comparsion results: The comparison results were summarized in Table 7, where the parameters corresponding to the state-of-the-art methods were described in Table 8. The results in Table 7 support the following conclusions.
Although using the method to diagnose AS yielded a higher than that of the proposed method, the was lower than that of the proposed method, partially due to the high achieved by the proposed method.
Although using the method to diagnose MS yielded a higher than that of the proposed method, the was lower than that of the proposed method, partially due to the high achieved by the proposed method.
Although using the method to diagnose NM yielded a higher than that of the proposed method, the was lower than that of the proposed method, partially due to the high achieved by the proposed method.
For other sounds, the classification accuracies achieved in the proposed method were all greater than those of the other methods listed in Table 7 .
Overall, the efficiency of the proposed method in diagnosing MR, MS, ASD, NM, AS, AR and VSD diseases was evaluated by comparison with the other efficient methods listed in Table 7.
Table 5.
Experimental sounds used to evaluate the performance.
| Data source | Period numbers of every type of heart disease/Patients | ||||||
|---|---|---|---|---|---|---|---|
| MR | MS | ASD | NM | AS | AR | VSD | |
| Sounds in Sect. 2.2 | 769/10 | 439/5 | 315/7 | 1056/45 | 381/10 | 665/15 | 327/10 |
| New sounds | 156/3 | 132/2 | 82/2 | 183/8 | 126/3 | 153/4 | 70/3 |
| Total sounds | 925/13 | 571/7 | 397/9 | 1239/53 | 507/13 | 818/19 | 397/13 |
Table 6.
Efficient methods successfully used in diagnosing normal sounds from other common heart diseases.
| Method | Year | Performance evaluation |
|---|---|---|
| 146 | 2021 | The Fano-factor constrained tunable quality wavelet transform (TQWT) was the sensitivity and specificity of and respectively and overall score of to detect abnormal heart sounds. |
| 247 | 2021 | This study proposed a heart sound classification method based on improved MFCC features and convolutional recurrent neural networks, which achieved classification accuracy of in the 2016 PhysioNeT/CinC Challenge database with dropout rate of 0.5. |
| 348 | 2020 | A deep WaveNet model was proposed to classify five heart sound types and achieve high classification accuracies: for diagnosing Normal, for diagnosing MVP, for diagnosing MS, for diagnosing MR, for diagnosing AS. |
| 48 | 2018 | The higher CA, achieved in this study, was , , and for diagnosing small ventricular septal defect (VSD), moderate VSD, large VSD and normal sounds, respectively. |
| 549 | 2017 | A rule-based classification tree method proposed by this study achieved very high CA: for diagnosing VSD, for diagnosing normal, for diagnosing aortic stenosis and for diagnosing aortic insufficiency. |
| 650 | 2016 | Artificial neural networks (ANNs) was reported to achieve the second-best score compared to the other methods in classifying the phonocardiogram recordings provided by the CinC Challenge. |
| 751 | 2016 | Random forest, a meta-learning approach that uses multiple random decision trees as base learners and aggregates them to compute the final ensemble prediction, was successfully used in sound classification such as studies. |
Table 7.
Comparative analysis of eight different methods for the diagnosis of heart diseases summarized in Table 5.
| Method | MR | MS | ASD | NM | AS | AR | VSD | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 92.1 | 86.34 | 87.6 | 88.2 | 86.81 | 87.3 | 91.2 | 84.53 | 85.1 | 86.3 | 82.90 | 81.6 | 90.9 | 98.25 | 99.1 | 88.2 | 86.05 | 85.4 | 95.2 | 96.31 | 96.8 | |
| 90.6 | 89.93 | 88.3 | 88.8 | 90.32 | 91.3 | 83.9 | 86.12 | 87.21 | 95.9 | 98.3 | 97.7 | 96.3 | 96.1 | 96.02 | 87.1 | 86.31 | 85.9 | 90.6 | 89.3 | 88.1 | |
| 90.1 | 88.6 | 87.5 | 85.1 | 85.69 | 99.2 | 81.3 | 80.97 | 80.8 | 93.6 | 91.95 | 90.3 | 87.9 | 85.04 | 83.3 | 92.1 | 88.69 | 85.6 | 88.6 | 86.9 | 85.9 | |
| 90.1 | 87.34 | 86.7 | 83.2 | 86.81 | 87.3 | 90.2 | 83.13 | 82.5 | 85.7 | 81.90 | 80.6 | 91.3 | 90.40 | 90.3 | 87.2 | 84.04 | 83.4 | 96.2 | 97.66 | 97.8 | |
| 88.6 | 85.93 | 85.3 | 86.1 | 89.72 | 90.2 | 79.8 | 82.10 | 82.3 | 96.1 | 98.93 | 99.9 | 98.3 | 91.95 | 96.2 | 85.1 | 86.97 | 83.6 | 87.5 | 87.19 | 82.1 | |
| 88.1 | 87.6 | 87.8 | 83.1 | 89.36 | 90.2 | 80.3 | 81.67 | 81.8 | 92.6 | 91.63 | 91.3 | 83.9 | 86.04 | 86.3 | 90.1 | 84.69 | 83.6 | 87.6 | 86.03 | 85.9 | |
| 89.7 | 91.64 | 92.1 | 85.2 | 83.52 | 83.3 | 86.3 | 87.49 | 87.6 | 93.7 | 91.61 | 90.9 | 90.1 | 87.05 | 86.7 | 85.2 | 82.21 | 81.6 | 90.8 | 91.63 | 91.7 | |
| This | 100 | 99.43 | 99.3 | 99.2 | 98.93 | 98.9 | 99.6 | 99.13 | 99.1 | 100 | 99.85 | 99.8 | 98.8 | 98.62 | 98.6 | 100 | 99.67 | 99.6 | 100 | 99.91 | 99.9 |
Table 8.
The highest accuracies corresponding to the parameters set in every state-of-the-art method.
| Method | Performance evaluation |
|---|---|
| 146 | The highest classification accuracies were obtained by using the features described in Table 3 on page 28. |
| 247 | The highest classification accuracies were obtained by using the 13-features extracted using MFCC algorithm. |
| 348 | The highest classification accuracies were obtained by using the porposed WaveNet model consists of 6 residual blocks. |
| 48 | The highest classification accuracies were obtained based on the rules described in a previous study8. |
| 549 | The highest CA results were obtained based on the following rules. |
| Rule 1: If the value of Lyapunov exponent and then the heart is normal. | |
| Rule 2: If and , then the heart disease is VSD. | |
| Rule 3: If , , and , then the heart disease is MR. | |
| Rule 4: If , , and , then the heart disease is MS. | |
| Rule 5: If , , and , then the heart disease is AR. | |
| Rule 6: If , , and , then the heart disease is ASD. | |
| Rule 7: If , , and , then the heart disease is AS. | |
| Rule 8: If none of these conditions are met, the HS is undefined. | |
| 650 | The most accurate results were obtained by the structure consisting of one input layer with 60 neurons, one hidden layer with 11 neurons and one output layer with five neurons. |
| 751 | The most accurate results were obtained by setting the number of features at each node, the number of trees and the maximum depth of trees to 1, 108, and 36, respectively. |
| This method | The most accurate results were obtained for the diagnosis of MR, MS, ASD, NM, AS, AR and VSD at and 0.2, respectively. |
Conclusion
A novel intelligent system was proposed for diagnosing heart diseases with high . The innovation of this approach is primarily reflected in: 1) the automatic extraction of secondary envelope-based frequency features; 2) the automatic determination of PCA-based diagnostic features , and ; and 3) the determination of adjustable confidence regions corresponding to the distribution. The confidence regions are obtained by calculating the Mahalanobis distance, which is adjusted by the desired confidence level , and the results were used as the classification criteria for diagnosing heart diseases. The procedure for the implementation of the intelligent system involved three stages. Stage 1 described the location and extraction of STMHT-based and . In stage 2, in the frequency domain, a novel method was first proposed to generate the envelopes and ; then, based on the lines, was automatically extracted. Finally, based on PCA, the first three principal components, , and , which expressed of the information, were determined and used as diagnostic features. In stage 3, the GMM-based objective function with respect to the features and the parameters [, , ], where , was generated. Then, the distribution for component k was determined by calculating the Mahalanobis distance from to the class mean of component k, and the confidence region for component k was determined by adjusting the optimal confidence level and used as the criterion (denoted as ) to diagnose a given HS. The performance evaluation was validated by sounds from online HS databases and clinical heart databases. The accuracy of the proposed method was compared to the accuracies of other well-known classifiers, and the highest classification accuracies of , , , , , 99.67 and 99.91 in the detection of MR, MS, ASD, NM, AS, AR and VSD sounds were achieved by setting to 0.87,0.65,0.67,0.65,0.67,0.79 and 0.87, respectively. Therefore, this proposed intelligent diagnosis system provided an efficient way to diagnose seven types of heart diseases.
The advantages and limitations were summarized as follows:
Advantages: and were automatically extracted to reduce difficulty in segmenting each cardiac cycle into a sequence of four heart stages: Systole period Diastole period; More features could be extended by setting even more threshold values for the unknown heart diseases, especially for the heart sound with the compound heart diseases; Every classifier achieved in this study could be adjusted based on the desired for fitting incremental new features without being retrained via huge training features.
Limitations: This methodology was impossible to diagnose the sounds when and cannot be segmented and extracted via the STMHT method for a given heart sound such as that plotted in Fig. 10; The proposed classifier might not be satisfied with the compound heart diseases due to the distribution of features extracted from which can not fit a single Gaussian distribution.
Figure 10.
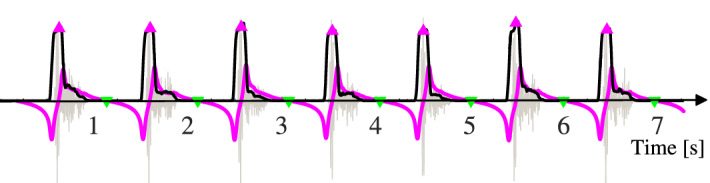
An example of a AR sound from database26.
Future study
Future study focused on how to handle the sounds (such as some AR sounds) when and cannot be segmented and extracted via the STMHT method will be explored, and on how to build the classifier model for fitting the compound heart diseases will be further studied.
Research statement
The study was conducted at Nanyang Institute of Technology and Nanyang First People’s Hospital, Henan, China from December 2017 to June 2021, and was approved by the ethics committee of Nanyang Institute of Technology and First People’s Hospital (Approval Number: V6.0). Informed consent was waived due to the retrospective design of the study. The study complies with the Declaration of Helsinki.
Acknowledgements
We would like to express our thanks to the medical ethics committee of Nanyang Institute of Technology and the First Peoples Hospital of Nanyang for their approval to conduct this research in Nanyang Institute of Technology’s biomedical information unit. The authors would like to thank Vaibhav Deshmukh for his suggestions on submitting this manuscript to Scientific Reports. This work was supported by the Key Projects of Hunan Provincial Department of Education (Nos. 21A0403 and 21A0405), and the university-industry collaborative project (No. 202102211006).
Author contributions
Sun, Biqiang Zhang and Huang: collection, organizing, and review of the literature. Sun, Biqiang Zhang and Huang: preparing the manuscript. Sun, Huang, Biqiang Zhang, He, Yan, Fan, Jiale Zhang and Chen: manuscript revision and modification. All authors read and approved the final manuscript.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Tan, Z., Wang, W., Zong, R., Pan, J. & Yang, H. [classification of heart sound signals in congenital heart disease based on convolutional neural network]. Sheng wu yi xue gong cheng xue za zhi = J. Biomed. Eng. Shengwu yixue gongchengxue zazhi36, 728–736, 10.7507/1001-5515.201806031 (2019). [DOI] [PMC free article] [PubMed]
- 2.Sun S, Wang H, Chang Z, Mao B, Liu Y. On the Mahalanobis distance classification criterion for a ventricular septal defect diagnosis system. IEEE Sens. J. 2019;19:2665–2674. doi: 10.1109/JSEN.2018.2882582. [DOI] [Google Scholar]
- 3.Omari T, Bereksi-Reguig F. A new approach for blood pressure estimation based on phonocardiogram. Biomed. Eng. Lett. 2019;9:395–406. doi: 10.1007/s13534-019-00113-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Notario, P. M. et al. Home-based telemedicine for children with medical complexity. Telemed. e-Health (2019). [DOI] [PMC free article] [PubMed]
- 5.Coviello, J. S. Auscultation Skills: Breath & Heart Sounds. -5th Ed. (Lippincott Williams & Wilkins, 2013), 5 edn.
- 6.Liu Q, Wu X, Ma X. An automatic segmentation method for heart sounds. Biomed. Eng. Online. 2018;17:1–22. doi: 10.1186/s12938-018-0538-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Messner E, Zöhrer M, Pernkopf F. Heart sound segmentation: an event detection approach using deep recurrent neural networks. IEEE Trans. Biomed. Eng. 2018;65:1964–1974. doi: 10.1109/TBME.2018.2843258. [DOI] [PubMed] [Google Scholar]
- 8.Sun S, Wang H. Principal component analysis-based features generation combined with ellipse models-based classification criterion for a ventricular septal defect diagnosis system. Aust. Phys. Eng. Sci. Med. 2018 doi: 10.1007/s13246-018-0676-1. [DOI] [PubMed] [Google Scholar]
- 9.Sun S. An innovative intelligent system based on automatic diagnostic feature extraction for diagnosing heart diseases. Knowl. Based Syst. 2015;75:224–238. doi: 10.1016/j.knosys.2014.12.001. [DOI] [Google Scholar]
- 10.Shuping Sun ZJYF, Haibin W, Tao T. Segmentation-based heart sound feature extraction combined with classifier models for a VSD diagnosis system. Exp. Syst. Appl. 2014;41:1769–1780. doi: 10.1016/j.eswa.2013.08.076. [DOI] [Google Scholar]
- 11.Choi S, Jiang Z. Cardiac sound murmurs classification with autoregressive spectral analysis and multi-support vector machine technique. Comput. Biol. Med. 2010;40:8–20. doi: 10.1016/j.compbiomed.2009.10.003. [DOI] [PubMed] [Google Scholar]
- 12.Zhang J, Yin Z, Wang R. Pattern classification of instantaneous cognitive task-load through GMM clustering, Laplacian eigenmap, and ensemble SVMS. IEEE/ACM Trans. Comput. Biol. Bioinf. 2017;14:947–965. doi: 10.1109/TCBB.2016.2561927. [DOI] [PubMed] [Google Scholar]
- 13.Li Z, Xia Y, Ji Z, Zhang Y. Brain voxel classification in magnetic resonance images using niche differential evolution based Bayesian inference of variational mixture of Gaussians. Neurocomputing. 2017;269:47–57. doi: 10.1016/j.neucom.2016.08.147. [DOI] [Google Scholar]
- 14.Ortiz-Rosario A, Adeli H, Buford JA. MUSIC-Expected maximization gaussian mixture methodology for clustering and detection of task-related neuronal firing rates. Behav. Brain Res. 2017;317:226–236. doi: 10.1016/j.bbr.2016.09.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Davari, A., Aptoula, E., Yanikoglu, B., Maier, A. & Riess, C. GMM-based synthetic samples for classification of hyperspectral images with limited training data. IEEE Geosci. Remote Sens. Lett.15, 942–946, 10.1109/LGRS.2018.2817361 (2018). arXiv:1712.04778.
- 16.Simms, L. M. et al. Nuclear Inst . and Methods in Physics Research , A Pulse discrimination with a Gaussian mixture model on an FPGA. Nucl. Inst. Methods Phys. Res. A900, 1–7, 10.1016/j.nima.2018.05.039 (2018).
- 17.Xue W, Jiang T. An adaptive algorithm for target recognition using Gaussian mixture models. Meas. J. Int. Meas. Conf. 2018;124:233–240. doi: 10.1016/j.measurement.2018.04.019. [DOI] [Google Scholar]
- 18.Zhang S, et al. Segmentation of small ground glass opacity pulmonary nodules based on Markov random field energy and Bayesian probability difference. Biomed. Eng. Online. 2020;19:1–20. doi: 10.1186/s12938-020-00793-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.The World Medical Association Inc. DECLARATION OF HELSINKI Ethical Principles for Medical Research Involving Human Subjects Adopted. WMA General Assembly, Somerset West, Republic of South Africa 1–5 (2008).
- 20.3MCompany. 3m health care company. http://www.3M.com/Littmann (2019).
- 21.Bernard Karnath, W. T. Auscultation of the heart. http://www.turner-white.com/pdf/hp_sep02_heart.pdf (2002).
- 22.Ali MN, El-Dahshan E-SA, Yahia AH. Denoising of heart sound signals using discrete wavelet transform. Circ. Syst. Signal Process. 2017;36:4482–4497. doi: 10.1007/s00034-017-0524-7. [DOI] [Google Scholar]
- 23.Máttar JA, et al. Systolic and diastolic time intervals in the critically ill patient. Crit. Care Med. 1991;19:1382–6. doi: 10.1097/00003246-199111000-00014. [DOI] [PubMed] [Google Scholar]
- 24.Yeo TC, et al. Value of a doppler-derived index combining systolic and diastolic time intervals in predicting outcome in primary pulmonary hypertension. Am. J. Cardiol. 1998;81:1157–1161. doi: 10.1016/S0002-9149(98)00140-4. [DOI] [PubMed] [Google Scholar]
- 25.Cui W, Roberson DA, Chen Z, Madronero LF, Cuneo BF. Systolic and diastolic time intervals measured from doppler tissue imaging: Normal values and z-score tables, and effects of age, heart rate, and body surface area. J. Am. Soc. Echocardiogr. 2008;21:361–370. doi: 10.1016/j.echo.2007.05.034. [DOI] [PubMed] [Google Scholar]
- 26.Implementation, C. M. Heart sounds databases-continuing medical implementation. http://www.cvtoolbox.com/index.html (2019).
- 27.MacWalter, D. & MacWalter, G. Human heart sounds and murmurs. http://www.dundee.ac.uk/medther/Cardiology/hsmur.html (2019).
- 28.Shuping Sun, H. W. A novel method-based secondary envelope extraction for heart sound analysis (2020).
- 29.3MDatabase. 50 heart and lung sounds library. http://solutions.3m.com/wps/portal/3M/en_EU/3M-Littmann-EMEA/stethoscope/littmann-learning-institute/heart-lung-sounds/heart-lung-sound-library/ (2019).
- 30.Medical Sound Library. Auscultate - Learn Heart Sounds, Murmurs and Medical Auscultation (2019).
- 31.AMBOSSMed. AMBOSS: Medical Knowledge Distilled (2019).
- 32.Auscultation Sound. Heart Murmur-Mitral Regurgitation Auscultation Sound !!! Complete (2019).
- 33.Sound, M. H. & Library, M. University of michigan heart sound and murmur library. http://www.med.umich.edu/lrc/psb/heartsounds/index.htm (2019).
- 34.ThinkLabs. Thinklabs heart sound library. https://www.thinklabs.com/heart-sounds?hc_location=ufi (2019).
- 35.Mohseni, S. S. Heart arrhythmias classification via a sequential classifier using neural network , principal component analysis and heart rate variation. IEEE 8th International Conference on Intelligent Systems Heart 715–722 (2016).
- 36.Kavitha, R. & Kannan, E. An efficient framework for heart disease classification using feature extraction and feature selection technique in data mining. In: Proceedings of the 1st International Conference on Emerging Trends in Engineering, Technology and Science, ICETETS 201610.1109/ICETETS.2016.7603000 (2016).
- 37.Guo, H.-W. et al. Heart rate variability signal features for emotion recognition by using principal component analysis and support vectors machine. In: Proceedings of the 2016 IEEE 16th International Conference on Bioinformatics and Bioengineering (BIBE) 274–277, 10.1109/BIBE.2016.40 (2016).
- 38.Motin, M. A. Principal component analysis : a novel approach for extracting respiratory rate and heart rate from photoplethysmographic signal.22, 766–774 (2018). [DOI] [PubMed]
- 39.H. El-Saadawy, H. A. S., M. Tantawi & Tolba, M. F. Electrocardiogram (ecg) heart disease diagnosis using pnn, svm and softmax regression classifiers. In: The Eighth International Conference on Intelligent Computing and Information Systems (ICICIS) 106–110 (2017).
- 40.Johnson, R. A. & Wichern, D. W. Applied Multivariate Statistical Analysis (6th Edition) (Pearson, 2007).
- 41.Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the em algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977;39:1–38. [Google Scholar]
- 42.Pinto RC, Engel PM. A fast incremental gaussian mixture model. PLoS ONE. 2015;10:1–12. doi: 10.1371/journal.pone.0139931. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Proïa F, Pernet A, Thouroude T, Michel G, Clotault J. On the characterization of flowering curves using Gaussian mixture models. J. Theor. Biol. 2016;402:75–88. doi: 10.1016/j.jtbi.2016.04.022. [DOI] [PubMed] [Google Scholar]
- 44.Mungai, P. K. Using Keystroke Dynamics in a Multi-level Architecture to Protect Online Examinations from Impersonation. In: Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis 622–627 (2017).
- 45.Aryafar, A., Mikaeil, R., Doulati Ardejani, F., Shaffiee Haghshenas, S. & Jafarpour, A. Application of non-linear regression and soft computing techniques for modeling process of pollutant adsorption from industrial wastewaters. J. Min. Environ. (2018).
- 46.Sawant NK, Patidar S, Nesaragi N, Acharya UR. Automated detection of abnormal heart sound signals using Fano-factor constrained tunable quality wavelet transform. Biocyber. Biomed. Eng. 2021;41:111–126. doi: 10.1016/j.bbe.2020.12.007. [DOI] [Google Scholar]
- 47.Deperlioglu O. Heart sound classification with signal instant energy and stacked autoencoder network. Biomed. Signal Process. Control. 2021;64:102211. doi: 10.1016/j.bspc.2020.102211. [DOI] [Google Scholar]
- 48.Oh SL, et al. Classification of heart sound signals using a novel deep WaveNet model. Comput. Methods Prog. Biomed. 2020 doi: 10.1016/j.cmpb.2020.105604. [DOI] [PubMed] [Google Scholar]
- 49.Karar ME, El-Khafif SH, El-Brawany MA. Automated diagnosis of heart sounds using rule-based classification tree. J. Med. Syst. 2017;41:60. doi: 10.1007/s10916-017-0704-9. [DOI] [PubMed] [Google Scholar]
- 50.Zabihi, M. et al. Heart sound anomaly and quality detection using ensemble of neural networks without segmentation. Comput. Cardiol. Conf. (CinC) (2016) 10.22489/CinC.2016.180-213. [DOI]
- 51.Witten, I. H., Frank, E. & Hall, M. Data Mining: Practical Machine Learning Tools and Techniques (Morgan Kaufmann, 2016), fourth edn. arXiv:1011.1669v3.