
Figure 2.
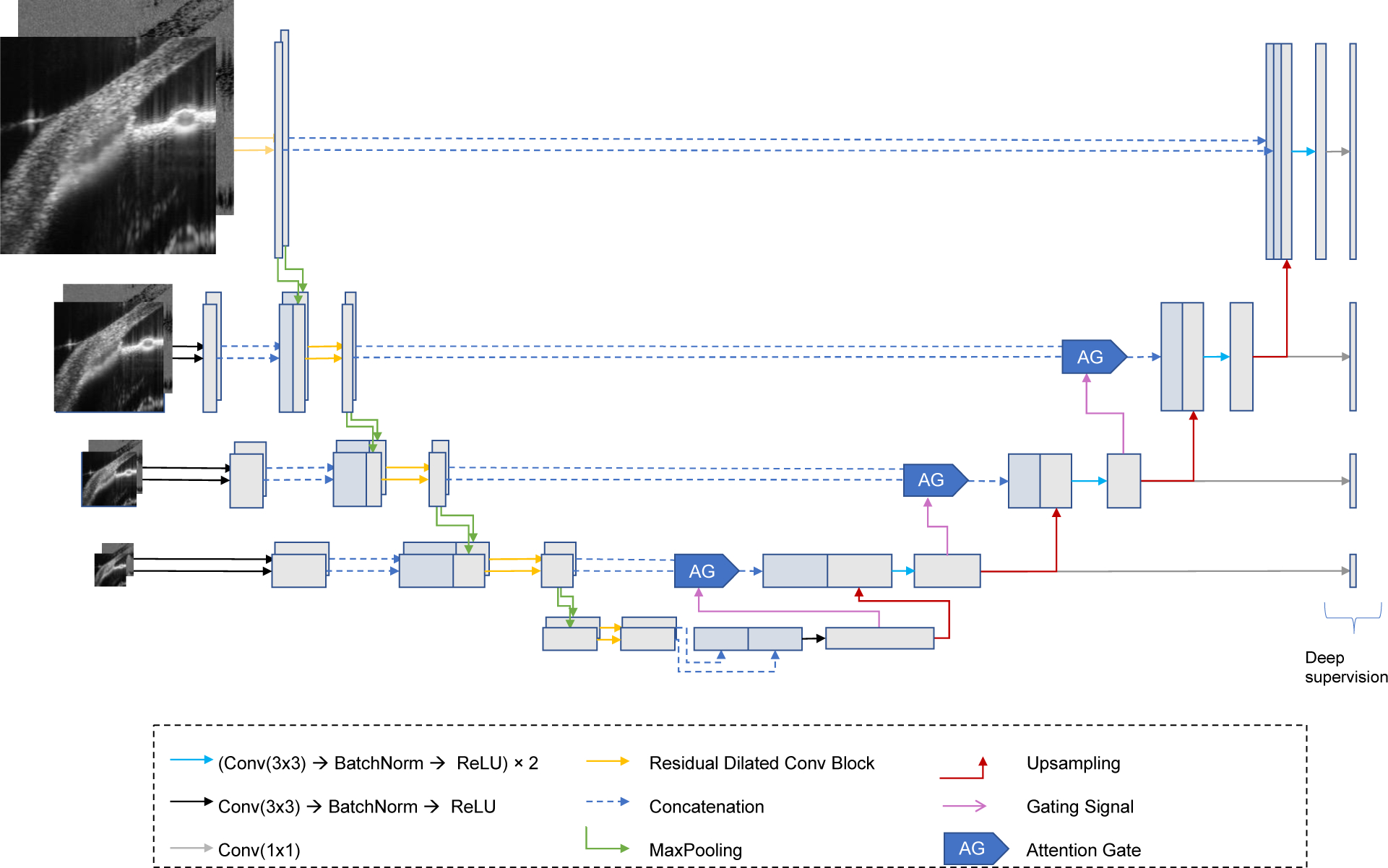
Proposed CNN Model: LF-DRAG-UNet. The network is trained on OCT and SV-OCT images using separate encoder branches that are fused downstream. A multi-scale input image pyramid and dilated residual convolutions are used to provide more global information. Attention gating is used to prune irrelevant regions of the feature maps.