
Figure 3.
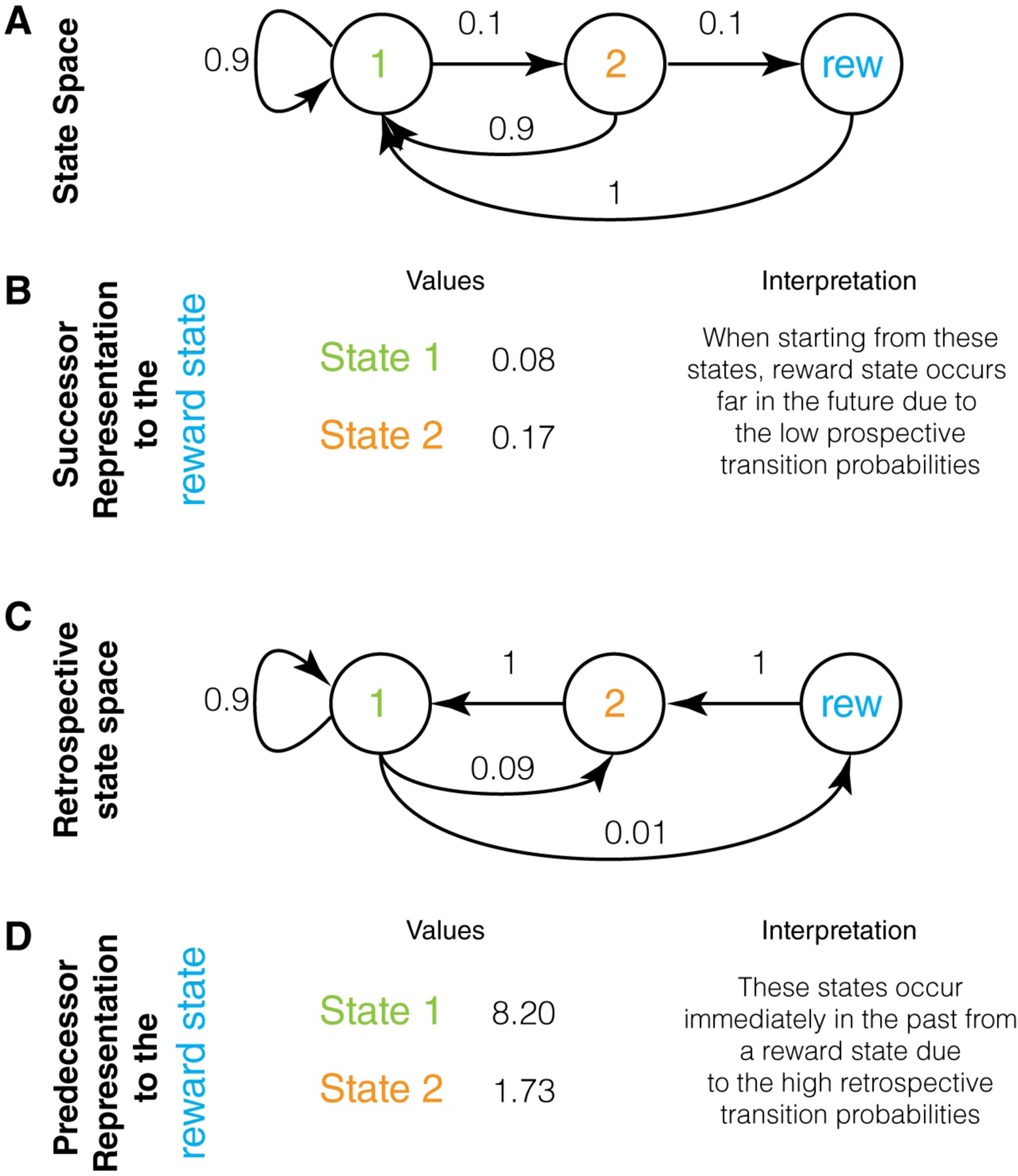
Successor and Predecessor representations: A. A state space that illustrates the key difference between successor and predecessor representations. Here, state 1 transitions with 10% probability to state 2, which then transitions with 10% probability to a reward state. Thus, obtaining reward is only possible by starting at state 1, even though the probability of reward is extremely low when starting at state 1 (1%). The challenge of an animal is to learn that the only feasible path to a reward state is by starting in state 1. B. The values of the successor representation to a reward state for states 1 and 2 are shown under the assumption of a discount factor of 0.9 (calculated in Appendix 1). These are very low and reflect the fact that reward states typically occur far into the future when starting in these states (due to low transition probabilities to reward state). Hence, these low values do not highlight that a reward state is only feasible if the animal starts in state 1. C. The retrospective state space for this example, showing that ending up in a reward state means that it is certain that the previous state was state 2 and that the second previous state was state 1. Thus, a retrospective evaluation makes it clear that a reward state is only feasible if one starts in state 1. D. The predecessor representation of the two states to the reward state. These values are very high compared to the SR and highlight the fact that a reward state is only feasible if the animal starts in state 1. PR is higher for state 1 because it is a much more frequent state (see text).