
Figure 3.
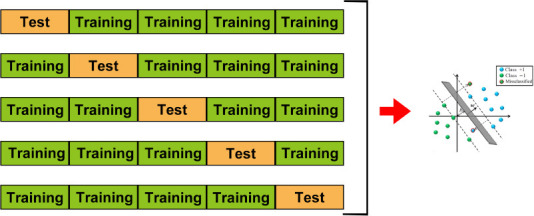
Five-fold cross validation.
The dataset was divided into five parts for 5-fold cross validation. One part was selected as the test dataset, while the remaining four parts were used as the training dataset. This was repeated five times so that each fold of the data was selected as a test set once, enabling us to obtain the predicted labels for all of the data. ‘b’ and ‘w’ in the figure are the parameters of the SVM. Different colored balls represent the samples with different labels.