
Figure 4.
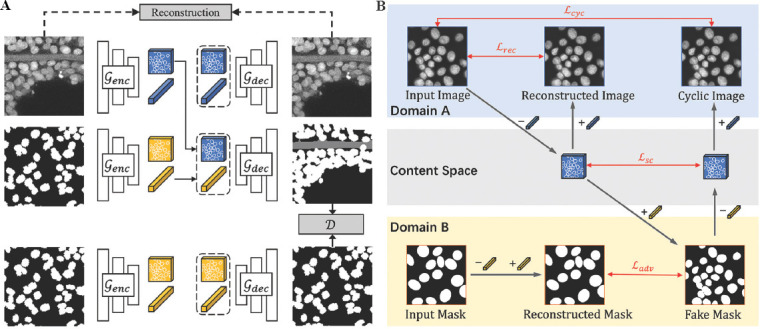
(A and B) Our Aligned Disentangled Generative Adversarial Network model consists of same-domain translation (top and bottom) and cross-domain translation (middle). The content representation ( ) is a tensor with spatial dimensions, while the style representation (
) is a tensor with spatial dimensions, while the style representation ( ) is a learned vector by multilayer perceptron from domain label. During same-domain translation, the encoder genc embeds an input into the shared content space and the decoder gdec reconstructs the content to image. Cross-domain translation is performed by swapping content representation.
) is a learned vector by multilayer perceptron from domain label. During same-domain translation, the encoder genc embeds an input into the shared content space and the decoder gdec reconstructs the content to image. Cross-domain translation is performed by swapping content representation.