
Figure 2.
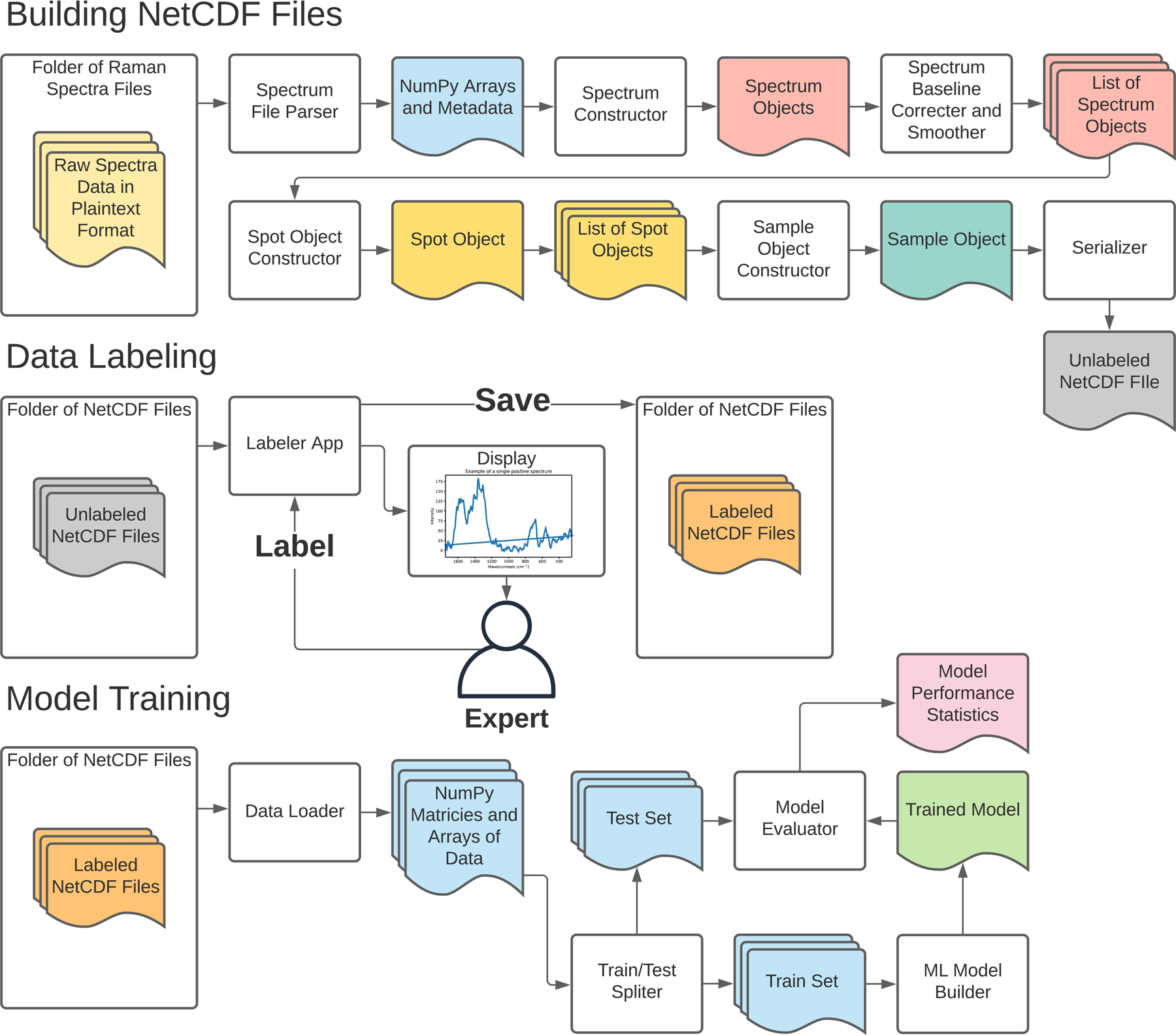
Open-source data pipeline developed for this study. The first stage of the pipeline converts and processes raw spectra files into a binary NetCDF file format. The second data labeling stage employs a custom Python “Labeler” app, allowing an expert Raman user to quickly assign labels (e.g., “good”, “bad”, or “maybe”) to the spectra serialized in the netCDF files. After labels have been assigned, the last stage of the pipeline is model training, where the binary files are loaded into NumPy arrays to train and test various ML models.