
Figure 4.

Clustering 1.5 million face images and 11 million HDFS log texts. (a and b) Results of 28 photos labeled ‘Jon Polito’ in clustering the first 500 images by using (a) WFC and (b) k-means respectively. There are 24 labels of the first 500 images. By setting  , k-means achieves its highest F1-measure score (0.809), resulting in only 21 correctly classified images. WFC identified a cluster with 27 correct images at
, k-means achieves its highest F1-measure score (0.809), resulting in only 21 correctly classified images. WFC identified a cluster with 27 correct images at 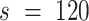 in a fully unsupervised way. Finer clusters with stronger similarities were also detected at the next two scales. (c) Validation scores for clustering the first 500 images. (d) Running times and evaluation scores (F1-measure, purity) of WFC, k-means and kNN-Louvain using distributed computing. Each result in (c and d) was computed by running each experiment 10 times, and error bars indicate the standard error of the mean. (e) Multi-scale clusters of HDFS logs detected by WFC, representing meaningful HDFS operations at different hierarchical levels. The width of each line is proportional to the logarithm of corresponding cluster size.
in a fully unsupervised way. Finer clusters with stronger similarities were also detected at the next two scales. (c) Validation scores for clustering the first 500 images. (d) Running times and evaluation scores (F1-measure, purity) of WFC, k-means and kNN-Louvain using distributed computing. Each result in (c and d) was computed by running each experiment 10 times, and error bars indicate the standard error of the mean. (e) Multi-scale clusters of HDFS logs detected by WFC, representing meaningful HDFS operations at different hierarchical levels. The width of each line is proportional to the logarithm of corresponding cluster size.