
Figure 1.
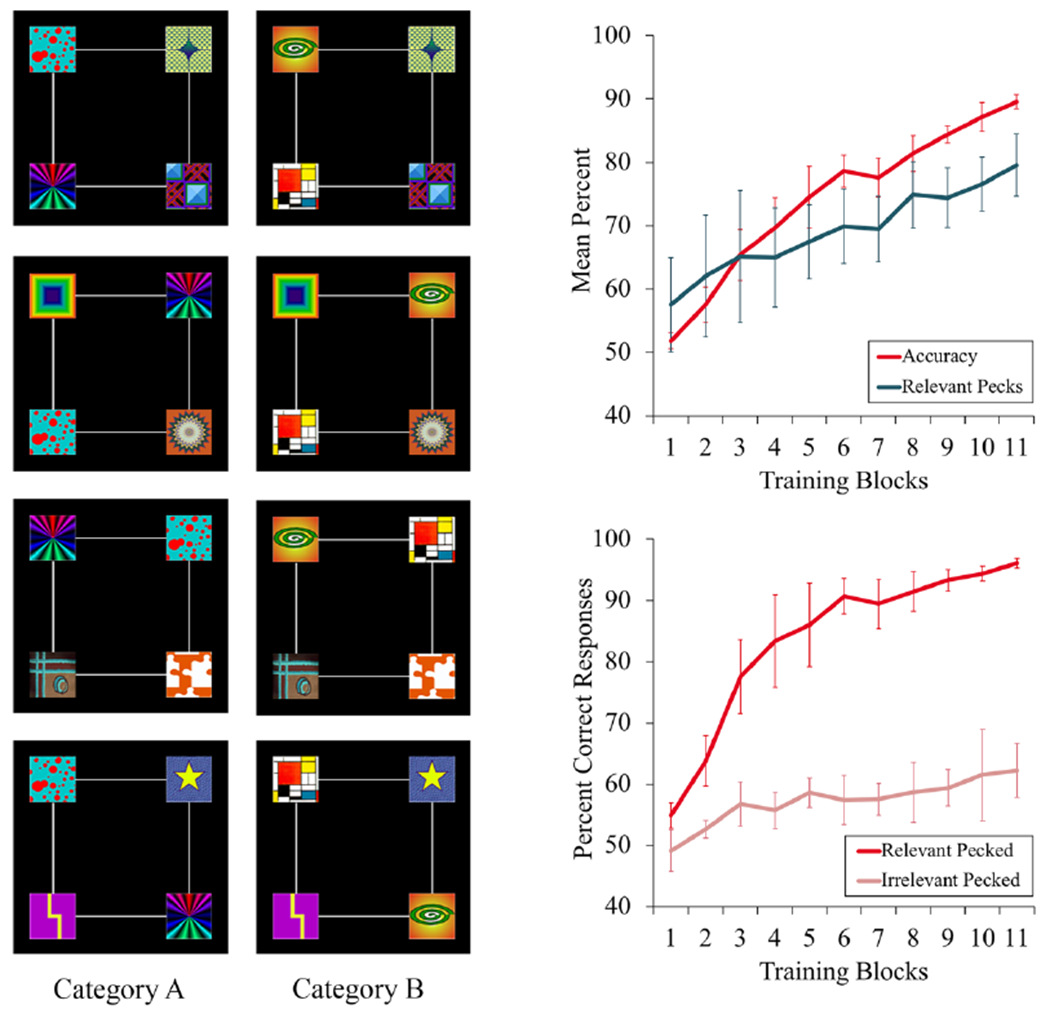
On the left, examples of Category A and Category B training exemplars in Castro and Wasserman (2014). There were two relevant features for Category A (the rainbow and the red bubbles) and two different relevant features for Category B (the green spiral and the Mondrian-colored squares). The other stimuli were irrelevant features, common to Categories A and B. On the right, top, mean percent accuracy and relevant pecks across training in Experiment 1 of Castro and Wasserman. On the right, bottom, accuracy scores across training depending on whether a relevant or an irrelevant feature had been pecked just before making the choice response. Error bars indicate the standard error of the means.