
Figure 1.
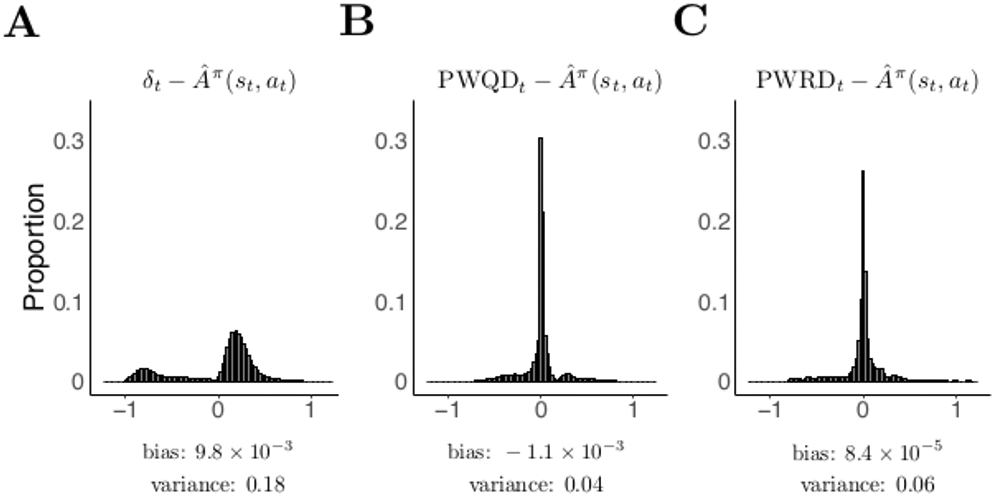
Comparison of three estimators of the Advantage function in a simulated four-armed bandit task (200 simulations of 300 trials each; see Appendix A for further details). When an arm is chosen, it probabilistically gives a reward of 0 or 1 (probabilities in simulation were 0.2, 0.4, 0.6, and 0.8). The agent implemented a TD(0) actor-critic architecture (Kimura & Kobayashi, 1998). Presented here are distributions of estimation errors for estimation of Advantage by (A) the temporal difference prediction error δ, (B) the policy-weighted Q-value difference (PWQD), and (C) the policy-weighted reward difference (PWRD). In this setting the bias of all three estimators is low, but the temporal difference error has greater estimation variance than either the PWRD or the PWQD.