
Figure 3:
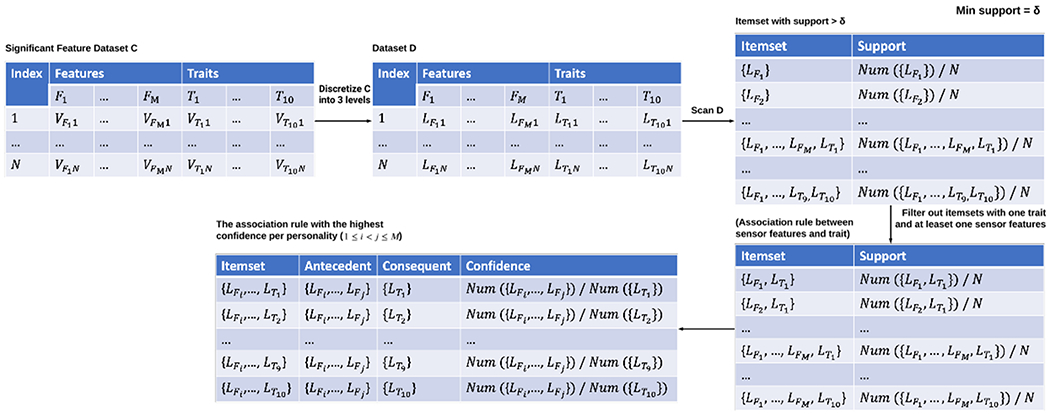
The process of mining association rules using the Apriori method. M is the number of highly ranked features we derived, V represents continuous values, and L represents the discrete levels. The input is the values of the day-level or person-level features selected by the machine learning pipeline, and the values of each participant’s personality traits. These values are then discretized into three levels: high (H), median (M) and low (L). The output is the association rule with the highest confidence per personality trait, indicating the most frequently occurring sensor feature combination with the personality trait of each level.