

Abstract
Sedentary behaviors are now prevalent as most modern jobs are done while seated. However, such sedentary behaviors have been found to increase the risk of several ailments including diabetes, cardiovascular disease, and all-cause mortality. Current interventions are mostly reactive and are triggered after the user has already been sedentary. Behavior change theory suggests that preventive sedentary interventions, which are triggered before a person becomes sedentary, are more likely to succeed. In this paper, we characterize user patterns of sedentary behaviors by analyzing smartphone-sensor data in a real-world dataset. Our work reveals location types (where), times of day/week (when), and smartphone contexts in which sedentary behaviors are most likely. Leveraging our findings, we then propose a set of context-aware probabilistic models that can predict sedentary behaviors in advance by analyzing smartphone sensor data. Our Context-Aware Predictive (CAP) models leverage smartphone-sensed contextual variables and the user’s history of sedentary behaviors to predict their future sedentary behaviors. We rigorously analyze the performance of our models and discuss the implications of our work.
Keywords: Sedentary behavior, Predictive model, Smartphone
Introduction
Sedentary lifestyles have become prevalent as most modern jobs are now done while seated in vehicles or offices [1]. The evolution of mechanization, automation, and cybernation has reduced human beings’ workloads and our modern society is now sitting oriented. In 1997, about 40% of U.S. adults were sedentary, not engaging in leisure time physical activities of any kind [2]. By analyzing behavioral data collected with accelerometers for the National Health and Nutrition Examination Survey (NHANES) in 2003–2004, Whitt-Glover et al. [3] found that participants spent a mean of 5.5–8.5 h per day in sedentary behaviors. The amount of sedentary behaviors is concerning because of mounting evidence of their adverse health effects. Recent research has found that the length of time spent sedentary is associated with an increased risk of diabetes, cardiovascular disease, and all-cause mortality [4, 5]. Such evidence led Lees and Booth [6] to develop a new term—sedentary death syndrome (SeDS)—to characterize disorders caused by sedentary lifestyles, which result in problems and conditions that increase premature death.
The word “sedentary” is from the Latin word sedere, meaning “to sit.” Pate et al. [7] defined sedentary behaviors qualitatively as activities that do not increase energy expenditure substantially above the resting level. Common sedentary behaviors include sleeping, sitting, lying down, watching television, and other forms of screen-based entertainments. Tremblay [8] proposed a quantitative definition of sedentary behavior as “‘waking behaviors characterized by an energy expenditure ≤ 1.5 Metabolic Equivalent of Task (METs) while in a sitting or reclining posture.”
Smartphones and wearables are now frequently equipped with a variety of sensors. Machine learning methods have been proposed, which analyze data from such sensors to recognize and sense various user contexts and physical activities [9–11] including sedentary behaviors [12]. State-of-the-art interventions for sedentary behavior leverage such sensors to create sensor-triggered reminders. For instance, the “Stand Reminders” feature of Apple Watch [13] reminds its user to stand up every 50 min if the user has not been active enough. Similarly, the “Reminder to Move” feature on Fitbit trackers’ checks the user’s steps at the 50th minute of each selected hour (e.g., 10:50AM). Users are then reminded to walk if they have not walked 250 steps or more in that hour [14].
While those interventions are a step in the right direction, they are “reactive” —intervening the deleterious sedentary behavior after it has been ongoing for quite a while. We believe that the ability to anticipate and predict sedentary behaviors will transform sedentary behavior intervention to sedentary behavior prevention. The reliable prediction of future sedentary behaviors will enable Just-In-Time (JIT) interventions that are triggered just before the user begins the sedentary behavior or while they are still in the planning stage. The efficacy of JIT interventions is supported by the theory of planned behavior, wherein modifications of a person’s day/week/month at the planning stage are more likely to succeed [15]. For example, if it is predicted that a person will sit for an entire afternoon watching TV, a gentle reminder might be sent around noon (JIT) reminding them that sitting for too long is unhealthy. Additionally, an intervention might be suggested such as asking him/her to stand up and walk around during commercial breaks while watching TV.
In order to support reliable prediction of future sedentary behaviors, robust models that analyze user behavior data are required. In this study, we propose a set of probabilistic models for predicting people’s sedentary behaviors from their smartphone sensor data. These models discover the underlying patterns in people’s historical behaviors and contexts. “Context” in the field of mobile computing refers to any information that can be used to characterize the situation of an entity, where an entity can be a person, place, or physical or computational object [16]. In our case, we focus on the context of a smartphone user.
Figure 1 presents an overview of our approach. Our approach and contributions are summarized as the following:
Characterization: We analyze a real-world smartphone dataset to characterize patterns of sedentary behavior including where (location types), when (times of the day/week), and smartphone-sensed contexts strongly correlated with sedentary behaviors.
Predictive models: Based on the insights we learned from the real-world dataset, we propose a category of probabilistic models of sedentary behaviors: Context-Aware Predictive (CAP) models. CAP models leverage smartphone-sensed contextual variables and the user’s history of sedentary behaviors to predict their future sedentary behaviors. We evaluate the discriminative and generative modeling approaches, and compare the sensitivity of our models to various lengths of user history and how far in advance the predictions of sedentary behaviors are made.
Intervention: We discuss proposed health behavior interventions that leverage the sedentary behavior predictions made by our models as a new research direction. The ability to predict sedentary behaviors facilitates more effective computer-driven mobile interventions. By leveraging accurate behavior prediction, mHealth apps will be able to recommend evidence-based and context-specific interventions in advance of future deleterious health behaviors [17].
Fig. 1.

Overview of our approach for predicting future sedentary behaviors
The rest of the paper is organized as follows: In the next section, we review the background of sedentary behavior (as a health problem), context awareness, and activity prediction with probabilistic models. In the “Methodology” section, we describe the dataset, explain the terminology, and discuss the study constraints and assumptions. In the “Characterization” section, we characterize sedentary behaviors from 3 perspectives: where, when, and the relation to smartphone usage. In the “Probabilistic Models” section, we mathematically define the different variants of our probabilistic models. The section after that shows the results of our experiments evaluating a set of probabilistic models on a real smartphone dataset. Finally, we discuss the potential use of our models in future work—adopting predictive models in mobile/wearable health apps—and conclude this paper.
Background and Related Work
Health Effects of Sedentary Behavior
The deleterious health effects of sedentary behavior have been established by various medical studies. Several systematic reviews have recently confirmed that sedentary lifestyles are a real health problem in the modern society.
Link with Total Mortality
A large prospective study conducted by Patel [18] et al. (a type of study that observes health outcomes during the study period and relates them to suspected risk factors) found relationships between leisure time spent sitting and physical activity with mortality. Analysis of the time spent sitting and physical activity levels of 53,440 men and 69,776 women who were disease free at enrollment identified 11,307 deaths in men and 7923 deaths in women linked to these sedentary behaviors during the 14-year follow-up. After adjustment for smoking, body mass index (BMI), and other factors, they found that time spent sitting was associated with mortality in both women (relative risk [RR] = 1.34, 95% confidence interval [CI]: [1.25, 1.44]) and men (RR = 1.17, 95% CI: [1.11, 1.24]). RRs for sitting (≥ 6 h/day) and physical activity (< 24.5 MET-h/week) combined were 1.94 (95% CI: [1.70, 2.20]) for women and 1.48 (95% CI: [1.33, 1.65]) for men, compared with those with the least time sitting and most activity. Associations were strongest for cardiovascular disease mortality. They concluded that the time spent sitting was independently associated with total mortality, regardless of physical activity level.
Link with Cardiovascular Disease (CVD) and Diabetes
A systematic review of prospective studies on sedentary behaviors and health outcomes among adults by Proper et al. [5] analyzed 19 studies from several electronic databases. Strong evidence was found relating sedentary behavior to all-cause and cardiovascular disease (CVD) mortality. Moderate evidence was also found for a positive relationship between sitting time and the risk for type 2 diabetes. A meta-analysis by Wilmott et al. [4] examined the association between sedentary time and diabetes, cardiovascular disease, and death in adults. Sixteen prospective and two cross-sectional studies were selected and included, with 794,577 participants. They found that the sedentary time was associated with a 112% increase in the RR of diabetes, a 147% increase in the RR of cardiovascular events, a 90% increase in the risk of cardiovascular mortality, and a 49% increase in the risk of all-cause mortality. The review concluded that sedentary time is associated with an increased risk of diabetes, cardiovascular disease, and cardiovascular and all-cause mortality; the strength of the association is most consistent for diabetes.
Link with Obesity
Thorp et al. [19] conducted another systematic review of longitudinal studies—a type of observational research method in which data is gathered for the same subjects repeatedly over a period of time—published between 1996 and 2011. The studies reported relationships between self-reported sedentary behavior and device-based measures of sedentary time with health-related outcomes in adults. Forty-eight articles met the inclusion criteria, and of these, 46 incorporated self-reported measures including total sitting time, TV viewing time only, TV viewing time and other screen-time behaviors, and TV viewing time plus other sedentary behaviors. They found a consistent relationship between self-reported sedentary behavior and mortality and also with weight gain from childhood to the adult years.
Context Awareness
Our work characterizes and proposes probabilistic models that discover the underlying patterns in a smartphone user’s historical sedentary behaviors and contexts.
“Context” in the field of mobile computing refers to any information that can be used to characterize the situation of an entity, where an entity can be a person, place, or physical or computational object [16]. Chen and Kotz [20] further divide the contexts summarized by Schilit et al. [21] into four categories: (1) computing context, the information about computing resources such as network connectivity, communication costs, and communication bandwidth, and nearby resources (e.g., printers, displays, and workstations); (2) user context, the information about users of the system, such as user profiles, location, people nearby, and social situation; and (3) physical context, the information about the surrounding physical environment, such as lighting, noise levels, traffic conditions, and temperature.
In the case of sedentary behaviors, the entities are people who exhibit recurrent sedentary behaviors, and the contexts are the surrounding environments they are in (physical context), who they are (user context), and what smartphones, wearables, and cloud services (e.g., Dropbox for storing data) they use (computing context). In this study, we focus on users’ contexts—environments their smartphones can sense (e.g., location, ambient noise, and light intensity), social environments smartphone can infer (e.g., nearby people’s voices), and smartphone app usage (e.g., whether the user is playing Pokémon Go).
Sensors
Sensors are the fundamental components of mobile computing that enable the context awareness of mobile systems. Sensors could be physical hardware such as electrical parts (e.g., accelerometer and gyroscope) or software that implements algorithms (e.g., pedometer and face recognizer). Context sensors are further categorized into physical sensor and virtual sensor [22, 23].
Physical sensors are hardware sensors, which most smartphones and wearables are equipped with. They are capable of sensing various physical data and are the most frequently used types of sensors. Examples are accelerometers, gyroscopes, magnetometers, barometers, photodiodes (ultraviolet, infrared radiation, ambient light, etc.), microphone, and camera.
Virtual sensors (or soft sensors) are generated by software algorithms (e.g., classifiers) that process the raw data collected from physical sensors or from other information sources (e.g., smartphone usage logs). For example, a virtual “physical activity sensor” takes raw data from the smartphone accelerometer and gyroscope as input and outputs the physical activity type (e.g., “running” or “walking”) and duration that a user has performed. Virtual sensors can also extract information by performing data mining and Natural Language Processing (NLP) on text (e.g., email, SMS, and calendar event) and smartphone usage. For instance, Likamwa et al. [24] found that the patterns of smartphone usage can be used to infer the mood of users. Such patterns can be considered as virtual “mood sensors.” Pielot et al. [25] investigated boredom and smartphone usage and found that people often turn to their smartphones to seek stimulation when they are bored. The recency of communication, usage intensity, time of day, and demographics can infer boredom with an accuracy of up to 82.9%. Their boredom sensing algorithm can be called a virtual “boredom sensor.” Our work combines physical and virtual sensors to detect and predict sedentary behaviors.
Smartphones and Wearables
Smartphones and wearables are common personal digital gadgets nowadays. Smartphones are owned by over 81% of Americans. This is up from 2015, when 68% of American adults and 86% of young adults (18–29-year-olds) owned a smartphone [26]. Smartphones carried by people in pockets, coats, and handbags can sense the user’s contexts continuously. Specifically, the on-board sensors of smartphone such as the microphone, ambient light sensor, GPS, accelerometer, gyroscope, and magnetometer can be used to sense user’s physical activities, mental states, and environments. Essentially, smartphones can be considered as a sensor of human behavior.
Unlike smartphones which people may not always carry, wearables (e.g., fitness trackers) are attached to user’s body and are carried more often than smartphones. For instance, people may leave their smartphones on the desk for charging after they arrive at office or home. Wearables, on the contrary, are worn continuously and may still be attached to people when they are sleeping (e.g., fitness trackers with sleep tracking functionality) and even when they are taking showers (e.g., waterproof trackers). Our work focuses on sedentary behaviors detected by smartphones due to their ubiquitous ownership, but excludes wearables.
Context Awareness
Context awareness refers to the ability of a system to adapt itself to the changing situations including physical context, computational context, and user context [27]. Context-aware mobile applications can monitor context information from a variety of context sensors as discussed in previous sections. In healthcare research, context-aware mobile apps have been widely developed and used to promote exercises and healthy lifestyle [11, 28–30].
One of the earliest context-aware applications, UbiFit Garden was developed to track and encourage active physical activities using mobile phones [9]. Likewise, BeWell [10] can assist people in maintaining a healthy lifestyle by passively keeping track of their everyday behaviors without burdening them. Both approaches focus on tracking subjects’ behaviors and displaying results. Behavior prediction and intervention were not researched.
More recently, intelligent mobile coaching interventions have been proposed to target unhealthy behaviors. In 2013, Klevin et al. [31] proposed an intelligent coaching system for therapy adherence. They created “eMate,” a coaching system to determine why a user acts in conflict with his/her health goals. For example, people might be aware of the serious consequences of an unhealthy diet, but they might not feel that they will be actually affected. By inferring the causes of conflicts, the eMate system sends subjects’ tailored information through a mobile phone app and includes an online lifestyle diary to motivate behavior change. Intervention messages are sent to users on a weekly basis.
Our prior work [12] proposed and developed a context-aware application to encourage the user to walk more and be more active. It automatically classifies and records user’s physical activities, and recommends “walk interesting detours” that increases walking distance based on the user’s origin and intended destination. The study demonstrated the viability of activity recommendation based on detected user behaviors using off-the-shelf smartphones.
Activity Prediction with Probabilistic Models
Our goal is to create probabilistic models that predict future user sedentary behaviors based on observed past behaviors. Theoretically, human behavior can be approximately modeled as a control system. Human behavior follows a pattern over time, and environmental factors influence human behavior in certain ways either physically or mentally. Consider a person who follows a daily routine and drives on his usual route to the office every morning. Due to a new pavement construction on his route, he is forced to follow a diversion that takes him off his route, causing a late arrival at the office. In this example, “drive to office” is a human behavior with a certain pattern “every weekday morning with a usual route.” It can be influenced by a changing environment such as “new pavement construction” or by the person himself such as “being tired.”
By applying such insights, Pentland and Liu [32] proposed that many human behaviors can be accurately described as a set of dynamic models such as Kalman filter and can be sequenced together by a Markov chain. They demonstrated that driving-related actions can be accurately categorized soon after the actions begin using their behavior modeling methodology. Motivated by the goal of recognizing activities performed by elders in their dwellings, Viard et al. [33] also proposed a global method based on probabilistic finite-state automata and a definition of the normalized likelihood and perplexity.
Similarly, probabilistic graph-based activity prediction methods, such as Hidden Markov Models (HMM) [34] and Conditional Random Fields (CRF) [35], have also been proposed. Such probabilistic models such as HMMs, CRFs, and Bayesian networks [36] have emerged because they are efficient at representing random variables, dependence, and temporal variation, making them suitable for behavior modeling [37].
Sedentary Behavior Prediction Using Non-Probabilistic Models
There has been little similar work that creates models of smartphone-sensed behaviors and uses them to predict future sedentary behavior. He and Agu [38] proposed a model based on rhythm analysis to predict future sedentary behaviors. Their approach involves detecting the prevailing rhythms of sedentary behaviors and modeling the cyclical and linear rhythms using periodic functions (history-free) and linear functions (history-dependent) respectively. He and Agu also proposed an autoregressive model [39] with maximum entropy method for discovering people’s temporal patterns of sedentary behaviors from raw activity logs and a frequency domain algorithm [40] to identify recurrent sedentary behaviors that are usually the targets of interventions from activity time-series data at multiple timescales (hourly, daily, and weekly). They found that subjects who exhibited recurrent sedentary behaviors yielded periodic functions.
Machine Learning Approaches to Sedentary Behavior and Activity Prediction
Rather than modeling sedentary behaviors, much of recent work has utilized a machine learning or data mining approach. Kantoch [41] examined and compared linear discriminant analysis, support vector machines, K-nearest neighbors, naive Bayes, binary decision trees, and artificial neural networks to recognize sedentary behaviors. They however utilized data from wearable sensors while we utilized data from smartphone sensors. Bhattacharjee et al. [42] used machine learning to analyze sleep and sedentary behaviors from physiological signals. Cook and Krishnan [43] proposed various machine learning–based approaches for learning, discovering, recognizing, and predicting human behavior from sensor data mostly for smartphones. Fahim et al. [44] mined the contexts in which sedentary behaviors occur. There is a rich body of work on human activity recognition that uses machine learning and neural networks models and focuses on all activities and not only sedentary behaviors [45]. Also related are human action prediction methods from video using deep learning [46].
Other Related Works
Other related works include prior work that has proposed novel methods to quantify sedentary behaviors [47], predictive models for mobility but not sedentary behaviors [48], visual analytics for exploring health behaviors that include activities and sedentary behaviors [49], and smartphone apps that suggest interventions based on recognized and predicted patterns of sedentary behavior [12].
Methodology
Quantitative Definition of Sedentary Behavior
To define sedentary behavior quantitatively, we divide time into discrete time buckets and characterize what percentage of all activities performed in a given time bucket is sedentary. We define two terms first: time window (or time bucket) and sedentary level. Time window is the atomic time unit for which we examine people’s behavior. Sedentary level is the percentage of time in a time window people spent being sedentary. For example, if a person spent 15 min being sedentary in a 20-min time window, his/her sedentary level in this time window is 75% .
Exactly what sedentary level and what length of a time window should be considered as “prolonged” or “deleterious” remains debatable. Some studies define “prolonged” as being sedentary for an entire 20-min or 30-min bout [50], implying that the time window is 20 or 30 min and that the sedentary level is 100%. Other studies refer to it as “spending 3 or more hours watching television or using a computer per day” [51], which implies that the time window is 3 h and that the sedentary level is 100%.
For our work, we define prolonged sedentary behavior by adopting the health recommendation given by the Ergonomics Research Group of Cornell University [52]. They recommend “periodic standing and moving 1 to 2 minutes every 20 to 30 minutes,” and define three levels of sedentariness:
Very sedentary, a person who spends more than 96.67% of time on sitting and where people stand/move less than 1 min per 30 min ;
Sedentary, a person spends more than 90.00% of time but less than 96.67% of time on sitting. The value of 90.00% is calculated from a boundary case in the above recommendation, where people stand/move less than 2 min every 20 min ;
Active, a person spends less than 90.00% of time on sitting, which perfectly meets the recommendation.
Whenever “sedentary behavior” is mentioned in this paper without additional qualification, by default, it means a behavior with a very sedentary or sedentary level within a 20-min time window.
Smartphone Dataset
In this study, we use the “StudentLife” dataset [11]. It is a public dataset gathered at Dartmouth College. It contains smartphone logs of 49 Dartmouth College students.1 The study was conducted in the spring of 2013. In the 10-week study, 49 Dartmouth College students were given a smartphone running an application collecting smartphone-sensed data (such as app usage, locations visited, and ambient sound/light) as well as students’ periodic responses to mental health (e.g., mood, affect, and depression) questionnaires. StudentLife dataset provides us with real physical activity data, from which sedentary behaviors are extracted with contexts of college students.
To provide a general sense of the StudentLife dataset in terms of sedentary level, Fig. 2 shows the daily sedentary levels (percentage of time in a 1-h time window people spent being sedentary) of 49 students over 10 weeks. The X-axis is the date and the Y-axis is the subject ID. Because some students dropped out of the StudentLife study [11], the subject ID is not from 0 to 48. In Fig. 2, it can be observed that the students participating in the StudentLife study started and ended the study on different dates. Also, not all students turned on their given smartphones during the study. The blank areas in Fig. 2 are the dates we do not have any data for the corresponding students.
Fig. 2.

Daily sedentary levels of 49 students over 10 weeks
Discretizing Time Series into Time Buckets
StudentLife dataset contains physical activity logs with activity labels (Stationary, Walking, Running, and Unknown) which were sampled every 2–3 s in 1 of every 4 min. In order to preserve battery life of study participants and minimize attrition, different types of data were sampled at different frequencies. For example, smartphone app usage was sampled every 20 min, and location logs were sampled every 10 min. In 1 h of app usage and location data, the different sampling rates would generate different amounts of usage logs (e.g., 3 app usage logs and 6 locations logs for 1 h). This will cause difficulties in correlation analysis. Due to this variability observed in sampling rates, discretization and time alignment of the time series data are required for data analysis. In this study, all types of data such as physical activity, location, and app usage were discretized into 20-min buckets, 30-min buckets, 40-min buckets, 50-min buckets, 1-h buckets, 2-h buckets, 3-h buckets, 4-h buckets, and 6-h buckets. The idea here is to count how many sedentary behaviors occurred within each time bucket, which permits statistical analysis. From StudentLife dataset, 65,601 such 1-h buckets can be extracted from the raw smartphone logs.
Extracting Semantic Locations
One aspect of the analysis is to characterize where the students were sedentary on the campus of Dartmouth College. In the Studentlife dataset, the historical locations students visited were represented as either GPS logs (more accurate) or service set identifier (SSID) logs of Wi-Fi access points that were close to the student’s location. Because raw GPS logs (coordinates) and SSIDs (strings) are difficult to reason about why sedentary behaviors occurred there, converting Wi-Fi SSIDs to Dartmouth College campus building names made the location data more meaningful and useful for characterization.
However, the “SSID ⇔ building name” mapping information for Dartmouth College campus was not publicly available. Fortunately, we were able to obtain metadata of all Dartmouth College buildings in a JavaScript Object Notation (JSON) format from Dartmouth College’s online map service (http://m.dartmouth.edu/map/), which was powered with an open-source software—Kurogo Mobile Web (https://github.com/modolabs/Kurogo-Mobile-Web). An example of a JSON representation of Dartmouth College building (Baker Library) is shown below:

In total, 678 locations/buildings were found on http://m.dartmouth.edu/map/. A sample of the Dartmouth College buildings retrieved is shown on a map in Fig. 3. Among them, 101 SSIDs were mapped to Dartmouth College’s buildings. For instance, the “sudikoff ” SSID was mapped to building “Sudikoff Hall.”
Fig. 3.

Buildings on the campus of Dartmouth College. Different colors represent different building types:  is Parking Lot;
is Parking Lot;  is Dartmouth/Hanover Community;
is Dartmouth/Hanover Community;  is Residential-Undergraduate;
is Residential-Undergraduate;  is Common Public Event Spaces; and
is Common Public Event Spaces; and  is Academic & Administrative
is Academic & Administrative
Identifying Smartphone Apps Used
Prior work by Xu et al. [53] has shown that app usage correlates with user activities and environment factors. We hypothesized that certain apps may either cause or are correlated with sedentary behaviors. For instance, most people sit quietly while using banking apps to thoughtfully review their banking statements. In this example, the banking app causes the sedentary behavior. In this section, we analyze the apps used by Dartmouth College students in order to determine what types of apps generally caused or were correlated with sedentary behaviors.
This app usage analysis involved placing specific apps used into different app categories. The 49 students in the StudentLife study were given Google Nexus 4 Android phones for everyday use. A data gathering app running in the background of these phones recorded the apps they launched or used throughout their day. Whenever a student used an Android app, the Java package name of the app (e.g., “com.google.android.gm”) was recorded. In total, 698 unique package names were found in 1,990,510 app usage logs.
In order to determine which apps corresponded with these package names, these 698 unique package names were cross-referenced with the Google Play Store, Amazon AppStore, Wandoujia Market, and online searches. A total of 480 unique apps were identified in terms of the app name (e.g., “Gmail”), the app developer (e.g., “Google Inc.”), and the app category (e.g., “Communication”). Apps with package names such as “com.example.xxx” and “edu.dartmouth.cs65.xxx” were considered homework apps programmed by students. We labeled 204 such homework apps with app name “Study” and categorized them as “Experiment” apps.
Characteristics of Sedentary Behavior
Many prior studies of sedentary behaviors involve statistical factor analysis to establish the correlation between sedentary behaviors and various health outcomes [4–6]. A detailed characterization of sedentary behaviors and the occurrence contexts has not yet been well explored and studied at the time of writing. Such fine-grained data are necessary for driving machine learning algorithms and intelligent mobile applications. Our approach is to characterize the sedentary patterns exhibited by students in the StudentLife dataset.
In this section, the sedentary behaviors of college students will be characterized from 3 perspectives: when, where, and the relation to smartphone usage.
When: Times Sedentary Behaviors Occurred
We suspected that sedentary behaviors may occur more at certain times since college students and campuses are schedule-driven. For instance, classes usually take place during the day, and leisure time is usually before or after class time. Prior work has established that undergraduate students have a certain order about their schedules driven by the class schedules. For example, in Barkhuus et al.’s study [54], one student reported, “My room mate and I have lunch every Monday, Wednesday, Friday, because we have class that get out at the same time. Tuesdays, Thursday I meet my guy-friends at [a fast food restaurant on campus].” If times when students are mostly sedentary can be established, then some temporal models can be applied.
Figure 4 is a heatmap of the average sedentary levels—the percentages of time spent on sedentary behaviors in a time bucket. The Y-axis is the Day of Week and the X-axis is the Hour of Day. The value of each cell in the grid is the average sedentary level computed for all 49 students in a particular hour and day (1-h bucket). For instance, the block at the bottom left corner represents the average sedentary level (81.60%) of all 49 students on Sunday midnight between 12AM and 1AM.
Fig. 4.

Average sedentary level over a week timespan
Students were generally more sedentary during nighttime (10PM–8AM) than daytime (8AM–10PM). We believe that this was caused by resting/sleeping—a type of sedentary behavior. Students were also more structured earlier in the week, sleeping more overnight, and being relatively more sedentary on Sunday, Monday, and Tuesday nights than other nights (Thursday to Saturday) of the week. During the day, students were more sedentary on Mondays, Tuesdays, and Wednesdays. We speculate that the first half of week was busier, focusing more on school work and less on social engagements, and thus more structured than the second half of week for Dartmouth College students. The latter part of the week and weekends typically have more social activities. Future work might explore additional interesting relationships regarding causation of sedentary behaviors by class schedules, deadlines, and personal weekly routines.
Students were generally more active in the mornings (8AM–12PM) than the afternoons (12PM–5PM). We speculate that this phenomenon might be caused by the fact that more courses were scheduled in the morning. A heatmap of the distributions of course meetings (Fig. 5) is generated by cross-referencing the courses registered by each student and the meeting schedules of each course. We acknowledge that actual student attendance (and hence activity) may deviate from course schedules due to factors such as students skipping some classes or classes being canceled due to bad weather.
Fig. 5.

Course meetings
Where: Locations at Which Sedentary Behaviors Occurred
Student activities and their mobility patterns tend to revolve around a few buildings. Their locations at any point during the week were largely dependent on their class schedules. Prior work has found that students tend to be nomadic in nature through their day [54]. They moved through the campus, stopping temporarily for dining, working in computer labs, studying at libraries, and attending classes. Many of these nomadic stops are points at which sedentary behaviors may occur. For example, after class, a student may go to a coffee shop and sit there for half an hour.
Because the geometry information (the “shape”) of each building is available with the map service, we further merged the semantic locations (buildings) extracted from SSID logs with the geographic coordinates in GPS logs. After that, we cross-referenced the locations with sedentary behaviors by timestamps. Figure 6 shows a heatmap sample of where sedentary behaviors occurred on the campus of Dartmouth College.
Fig. 6.

A sample heatmap of where sedentary behaviors occurred (locations)
Buildings in Which Sedentary Behaviors Occurred
Figure 7 shows the top-10 buildings where very sedentary behaviors occurred. The buildings ranked 1st (“North Park Street” graduate student apartments) and 3rd (“Mass Row Cluster” undergraduate residence hall) are places where students sleep, resulting in high sedentary levels at night (≈ 6–8 h per day). The building ranked 2nd highest is “Sudikoff Hall,” where the Department of Computer Science is located. We speculate that students were highly sedentary at this building because most computer science research and study require sitting and using computers.
Fig. 7.

Top-10 buildings where sedentary behaviors occurred
To find the correlation between locations and very sedentary behaviors, Pearson correlation coefficients (PCCs) [55] and 95% confidence intervals (CI) were calculated. Figure 8 shows the top-10 buildings that were positively correlated with very sedentary behaviors. “North Park Street” (graduate student apartments) was the most positively correlated (ρ = 0.1489 and 95% CI = [0.1437, 0.1540]) building with very sedentary behaviors. As mentioned, this is not surprising because apartments are places where students rest and sleep.
Fig. 8.

Top-10 buildings that were positively correlated with very sedentary behaviors
Figure 9 shows the top-10 buildings that were negatively correlated with very sedentary behaviors. “Hopkins Center for the Arts” was the most negatively correlated building (ρ = − 0.1586 and 95% CI = [− 0.1637, − 0.1534]) with very sedentary behaviors. “Hopkins Center for the Arts” building is the home of the drama and music departments and is used for student performances, concerts, and plays by visiting artists [56]. Those activities are active as opposed to sedentary behaviors.
Fig. 9.

Top-10 buildings that were negatively correlated with very sedentary behaviors
Building Category
Furthermore, the buildings were categorized using place type labels “Residential - Undergraduate,” “Residential - Graduate,” “Academic & Administrative,” “Common Public Event Spaces,” “Dining,” “Libraries,” “Dartmouth Community,” and “Athletics.” As expected, residential buildings and academic buildings were the places where the most very sedentary behaviors occurred (Fig. 10).
Fig. 10.

Categories of buildings where sedentary behaviors occurred
“Residential Undergraduate” category was positively correlated with very sedentary behaviors with ρ = 0.1731 and 95% CI = [0.1680, 0.1782]. “’Common Public Event Spaces” category was negatively correlated with very sedentary behaviors with ρ = − 0.2393 and 95% CI = [− 0.2443,− 0.2344].
Environment
Different environmental ambient sound/light levels may be associated with the types and intensity levels of physical activities people perform. For instance, sleep usually happens in quiet and dark locations, and exercises are usually surrounded by ambient noises at gyms and public parks. Figure 11 shows the sedentary behaviors of different levels distributed in different ambient sound types—“Silence,” “Voice” (people were talking near their smartphone), and “Noise.” Students tended to be more sedentary in quiet environments.
Fig. 11.
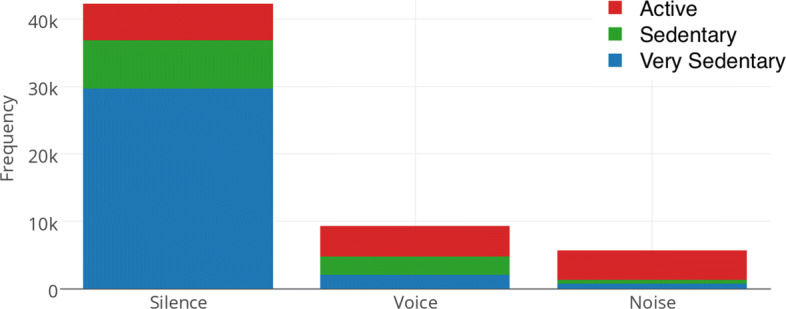
Ambient sound vs. sedentary behaviors
“Silence” was found to be positively correlated with very sedentary behaviors with ρ = 0.4665 and 95% CI = [0.4629, 0.4702] and “Noise” was negatively correlated with very sedentary behaviors with ρ = − 0.4194 and 95% CI = [− 0.4233,− 0.4156].
Figure 12 shows that students were more active in bright environments. “Dark” environments were found to be positively correlated with sedentary levels with ρ = 0.2491 and 95% CI = [0.2449, 0.2532]. From previous section, we learned that students were more physically active during daytime. We speculate that students were busy with lively activities during the day (or bright places) and were more sedentary in dark places (e.g., sleep at night).
Fig. 12.
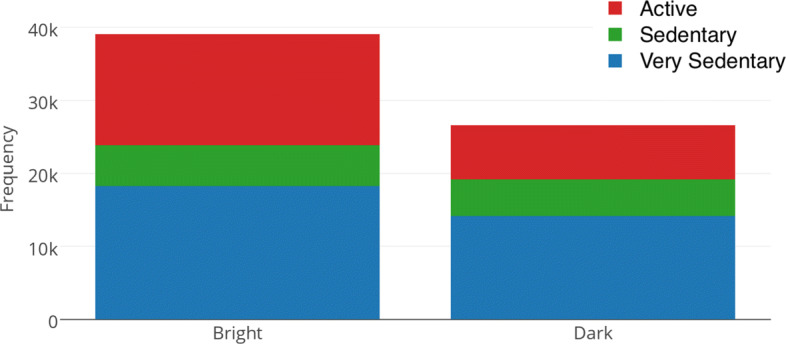
Ambient light vs. sedentary behaviors
Smartphone Usage Correlated with Sedentary Behaviors
Many smartphone-related activities such as chatting, watching videos, and gaming are usually performed while sitting or lying down, which have positive correlation with sedentary behaviors. Other smartphone apps such as exercise tracking apps are typically used while exercising, which has negative correlation with sedentary behaviors. In general, how smartphone usage is correlated with sedentary behavior and what types of smartphone use (e.g., communication, social networking, game playing, Web browsing) are correlated the most are questions we want to answer.
App Category
Among the identified 480 apps discussed in previous section, 87 apps belong to Game category, 61 apps belong to Tools category, and 45 apps belong to Productivity category (Fig. 13). Although many games were played by students, few games were played frequently. Figure 14 shows app usage by category. Only 2.99% (59,465) of all app usage (1,990,510) occurred in the Game category, in contrast to the fact that 18.13% (87) apps installed by students were games.
Fig. 13.

Number of apps in different categories
Fig. 14.

App usage in different categories
App Users
The 49 Dartmouth College students did not use all those 480 apps. Figure 15 shows the number of students who used a specific app. Each bar on the X-axis represents a unique app, and the height of the bar represents the number of students who used that app. The figure shows a long tail. More than half of the students used only 20 apps (4.17%). The top-10 non-system apps (not part of Android OS, such as Launcher and SystemUI) were Gmail (49 students), PACO (49 students), Study (49 students), Chrome Browser (49 students), Contacts (47 students), Gallery3D (46 students), Google Play (46 students), Messenger (40 students), Maps (31 students), and Google Calendar (29 students).
Fig. 15.

Number of students used a specific app
Correlation with Sedentary Behaviors
The usage of certain apps may be correlated with how sedentary people are. For instance, watching YouTube is typically done while sitting or lying down. Figure 16 shows the PCCs with 95% CI between different app categories and sedentary level. The usage of “Book and Reference” apps (e.g., Amazon Kindle app and Google Books), “Lifestyle” apps (e.g., Tinder and Etsy), and “News and Magazines” apps were positively correlated with sedentary level. We speculate that apps in these categories require the user to sit down or at least to hold the phone stable. For instance, it is common to read news and books on smartphone while sitting. On the other hands, “Music and Audio” apps (e.g., Pandora and Google Music), “Social” apps (e.g., Twitter and Facebook), and “Shopping” apps (e.g., Target and Walmart) are negatively correlated with sedentary level. We speculate that people usually use these apps while walking. For instance, it is common among students to listen to music and check friends’ updates in social networks while walking.
Fig. 16.

Correlation between app category and sedentary level
From another perspective of correlation, in Fig. 17, we show the average sedentary levels when students were using different types of apps. It is clear to see in Fig. 17 that when students were using Transportation apps (e.g., Uber and Lyft), Finance apps (e.g., Bank of America), Photography apps (e.g., Picasso, a drawing app), Books and Reference apps (e.g., Google Play Books), they were very sedentary.
Fig. 17.

Sedentary level vs. app category
Summary of Patterns of Sedentary Behavior
Times of sedentary behaviors: Students were generally more sedentary during nighttime (10PM–8AM) than daytime (8AM–10PM) and more active in the mornings (8AM–12PM) than the afternoons (12PM–5PM).
Locations of sedentary behaviors: Students’ residential buildings and academic buildings were the places where most sedentary behaviors happened. We speculate that this phenomenon was caused by the fact that daily activities (e.g., studying and researching) that require sitting (sedentary behavior) are usually performed in academic buildings, and resting activities (e.g., sleeping and relaxing) usually happen in residential buildings.
Environments in which sedentary behaviors occurred: Students tended to be more sedentary in quiet and dark environments.
Apps correlated with sedentary behaviors: When students were using apps in categories such as “Book and Reference,” “Lifestyle,” and “News and Magazines,” they tended to be sedentary. Checking social networks and listening to music can be done in parallel with walking and exercising. Apps in categories that were negatively correlated with sedentary behaviors suggest that users were more active when using such apps and may be good interventions for sedentary behaviors. For instance, workout apps were negatively correlated with sedentary levels. An intervention could recommend that people with desk jobs could take breaks and use a 7-Minute Workout app.
Probabilistic Models
In this section, we investigate whether contexts sensed by a smartphone can be used to reliably predict a user’s future sedentary behavior. We believe that reliable prediction of future prolonged sedentary behaviors will facilitate computer-driven health behavior interventions and deleterious behavior prevention.
Contextual Variables Sensed by a Smartphone
As detailed in previous sections, “StudentLife” is the dataset we use to create the probabilistic models for predicting sedentary behavior. We further process the raw data, derived data, and cross-referenced data with other data sources. Twenty-four smartphone-sensed context variables are then generated and will be utilized as features in our predictive models:
dateOfMonth, the date of the month (1 to 31)
dayOfWeek, the day of the week (Monday to Sunday)
hourOfDay, the hour of the day (0 to 23)
minuteOfHour, the minute of the hour (0 to 59)
activityMajor, the type of activity with the most instances in a time bucket
audioMajor, the type of audio with the most instances in a time bucket
radius, the radius (in meters) of the area covered by the student during a time bucket
latitude, the average latitude of the student’s location
longitude, the average longitude of the student’s location
travelstate, moving or not, sensed by GPS
locationMajor, the major location the student was at
isCharging, whether the smartphone was charging
isLocked, whether the smartphone was locked
isInDark, whether smartphone was in the dark
isInConversation, whether student was conversing
appNameMajor, the app used most frequently in a time bucket
appCategoryMajor, the app category most frequently used in a time bucket
diningPlace, the on-campus restaurant at which the student purchased a meal
diningType͡, the type of meal purchased by the student on campus (Breakfast, Lunch, Supper, or Snack)
courseName, the name of course the student is assumed to be attending
courseWifi, the Wi-Fi SSID of the course classroom the student is assumed be attending
afterLastDeadline, how many seconds since the last homework was due
beforeNextDeadline, how many seconds before the next homework is due
hasCalendarEvent, whether an event is scheduled in the calendar
The general idea behind the proposed Context-Aware Predictive (CAP) models is that we leverage the information in contextual variables and the history of sedentary behaviors to predict future sedentary behaviors. To simplify and unify the language and terms used here, we shall call the 24 contextual variables described above as “contextual behaviors.” For instance, contextual variable location can be considered as a person’s behavior “being at a specific place.” As such, in our predictive models, two types of variables exist: sedentary behavior, denoted as Y, with 3 levels very sedentary, sedentary, and active. It is the sedentary level we want to predict; and contextual behaviors, denoted as . They are the behaviors that happen together with a sedentary behavior.
To predict future sedentary behavior, denoted as Yt+ 1 (where time index t in the superscript indicates “right now” and t + 1 means “one step/time bucket ahead in the future”), we have several pieces of information we can leverage:2
The history of sedentary behavior ;
The current contextual behaviors ;
The histories of contextual behaviors .
History of Sedentary Behavior
The motivation behind using the history of sedentary behavior {} to predict future sedentary behavior Yt+ 1 is that the transformations between human behaviors have statistical patterns [57]. Sedentary behaviors also have such patterns. For instance, if a person just finishes running 5 km in the past 20 min (Yt = 0%, sedentary level: Active), we may expect this person will cool down for a few minutes and sit for relaxation in the next 20 min (Yt+ 1 ≥ 96.67%, sedentary level: very sedentary). Similarly, if an active person has sat for 1 h already (Yt = Yt− 1 = Yt− 2 = 100%, sedentary level: very sedentary), we may expect him/her to stand up and walk around (Yt+ 1 < 90.00%, sedentary level: active).
Figure 18 shows a probabilistic model for predicting future sedentary behavior with the history of sedentary behavior. In this model, the probability of future sedentary behavior to be p(Yt+ 1 = y) where y ∈ {ya (Active), ys (Sedentary), yvs (Very Sedentary)}, is predicted based on the observations of the past of sedentary behaviors.
Fig. 18.

Predict Yt+ 1 with {}
Assuming Yi is conditionally independent of every Yj (i≠j) given Yt+ 1, which means p(Yi = yi, Yj = yj|Yt+ 1 = y) = p(Yi = yi|Yt+ 1 = y)p(Yj = yj|Yt+ 1 = y), we can apply a naïve Bayes classifier—a probabilistic classifier applying Bayes’ theorem with strong (naïve) independence assumptions between the features [58]—for prediction by maximizing the joint probability,
| 1 |
where {yt−i|i ∈ [0,n],yt−i ∈{ya, ys, yvs}} are the historical observations of {Yt−i|i ∈ [0,n]} respectively.
Alternatively, we also consider a type of predictor where we do not have the independence assumption, and we can apply a multinomial logistic regression classifier (or sometimes referred as maximum entropy classifier) for prediction by maximizing conditional probability,
| 2 |
where is a normalizing constant, and are bias weights learned from training data for each y ∈{ya, ys, yvs} [59].
This model will be referred as SBPh (sedentary behavior prediction with history) model hereinafter.
Current Behaviors
Current contextual behaviors () and sedentary behaviors (Yt) are those that just occurred in the current timestep t. They are the most recent information that can be leveraged to predict the future. For instance, knowing a student just exercised 1 h at the gym around 6PM enables predicting that he will go back to his dormitory and sit and relax for the rest of the day.
Figure 19 shows the graphical model of using current behaviors to predict future behaviors. Similar to the naïve Bayes classifier and logistic regression classifier discussed previously, the methods for probabilistically forecasting Yt+ 1 are maximizing the joint probability (3) and maximizing the conditional probability (4):
| 3 |
| 4 |
where are the current observations of current context variables {} respectively, and are bias weights learned from training data for each y ∈{ya, ys, yvs}.
Fig. 19.

Predict Yt+ 1 with
This model will be referred to as the Sedentary Behavior Prediction with current behaviors SBPc model hereinafter.
Histories of All Behaviors
In the previous two models, the future sedentary behavior is predicted from two dimensions respectively—time dimension (Yi, historical sedentary behaviors.  in Fig. 20) and behavior dimension (Xj, current contextual behaviors.
in Fig. 20) and behavior dimension (Xj, current contextual behaviors.  in Fig. 20). It is natural to explore leveraging information from both dimensions to make a prediction. However, it is important to note that more information does not necessarily imply better prediction [60].
in Fig. 20). It is natural to explore leveraging information from both dimensions to make a prediction. However, it is important to note that more information does not necessarily imply better prediction [60].
Fig. 20.

Predict Yt+ 1 with histories of all behaviors.  is historical sedentary behaviors;
is historical sedentary behaviors;  is current contextual behaviors; and
is current contextual behaviors; and  is historical contextual behaviors
is historical contextual behaviors
A general model SBPa (sedentary behavior prediction with all behaviors and histories) is thus defined based on joint probability (5) and conditional probability (6):
| 5 |
| 6 |
where are bias weights learned from training data, which imply how influential the corresponding behaviors are. SBPh model leverages the information in  (historical sedentary behaviors) to make prediction; the SBPc model uses
(historical sedentary behaviors) to make prediction; the SBPc model uses  (current contextual behaviors); and SBPa utilizes
(current contextual behaviors); and SBPa utilizes  ,
,  , and
, and  (current and historical contextual behaviors and sedentary behaviors). To make the framework complete, we add one more model, SBPc (sedentary behavior prediction with partial history and current behaviors), which applies
(current and historical contextual behaviors and sedentary behaviors). To make the framework complete, we add one more model, SBPc (sedentary behavior prediction with partial history and current behaviors), which applies  and
and  (historical sedentary behaviors and current contextual behaviors).
(historical sedentary behaviors and current contextual behaviors).
It is noteworthy that SBPc is a special case of SBPa when the length of history used is set as 1.
Experiments
As described in the previous section, we have 3 categories of context-aware predictive models: SBPh, SBPc, and SBPa (Table 1). For each category, we have generative models built by maximizing the joint probability and discriminative models built by maximizing the conditional probability. Each model can choose different optimal time bucket sizes for discretization and different lengths of historical data to be used.
Table 1.
Categories of predictive models
| Category | Information used |
|---|---|
| SBPh | Historical sedentary behaviors |
| SBPc | Current contextual behaviors and historical sedentary behaviors |
| SBPa | All behaviors, both current and historical |
In total, we have 216 variants of predictive models: 3 categories (Table 1) × 2 strategies (generative and discriminative) × 9 time bucket sizes (20 min, 30 min, 40 min, 50 min, 1 h, 2 h, 3 h, 4 h, and 6 h) × 4 lengths (orders) of historical data used (1 bucket, 2 buckets, 3 buckets, and 4 buckets).
For these 216 models, 10,896 to 196,803 instances—depending on the size of time bucket for discretization—are used for experiments. Threefold cross-validation was used to calculate overall accuracy and evaluate the predictive models.
Generative Models vs. Discriminative Models
As mentioned above, half of the 216 models are generative models making predictions by maximizing joint probabilities (1), (3), and (5), and the other half are discriminative models making predictions by maximizing conditional probabilities (2), (4), and (6). When using generative models, we make a very strong and naïve conditional independence assumption that variables (contextual and sedentary behaviors) are independent of each other when predicting the future of the target variable (the future sedentary behavior). However, this assumption may not stand when using contextual behaviors to predict future sedentary behavior. For instance, certain contextual behaviors such as “being at the library” and “being in quiet environment” may be highly dependent on each other. Therefore, naïve Bayes classifier and generative models may not perform well.
To confirm this intuition, we ran experiments for both categories of models. The 216 models were separated into 2 groups for comparison—108 generative models with their 108 corresponding discriminative models listed next to them (Fig. 21). The Y-axis is the overall accuracy for predicting future sedentary level (very sedentary, sedentary, or active). It is clear to see in Fig. 21 that discriminative models ( ) outperform generative models (
) outperform generative models ( ) uniformly in this dataset. This confirms our intuition that we should not make the naïve independence assumption when predicting sedentary behavior using contextual behaviors.
) uniformly in this dataset. This confirms our intuition that we should not make the naïve independence assumption when predicting sedentary behavior using contextual behaviors.
Fig. 21.

Comparison between generative models and discriminative models
Therefore, henceforth we will only discuss the discriminative models—the 108 generative models will not be included in discussion hereafter.
Size of Time Bucket
As mentioned in the “Methodology” section, a critical step in data prepossessing is to discretize time into time buckets and place data into these buckets. If we make the size of time bucket small (e.g., 1 min), it will be more difficult to predict people’s next-bucket behavior. For instance, for an extreme case—1-s bucket—it is nearly impossible to predict a person’s behavior in the next moment because humans’ everyday life is so dynamic and complicated [61]. Shorter term predictions are more likely affected by many factors and even random noise caused by sensors, which can be smoothed out in longer term predictions. On the other hand, if the size of time bucket gets too large, the dependence of future events on past events on a longer timescale is weak, making it more difficult to make predictions. For example, knowing how sedentary a person is this year has little predictive power in estimating how sedentary s/he will be next year. This is because a typical person will most likely change their activity habits and sedentary behaviors in a year’s time. He/she may become more active playing exergames such as Pokémon Go, or join a local gym or start using a fitness tracker (e.g., Fitbit). On the other hand, he/she may become more sedentary and habitually watch more videos and generally become a couch potato.
The minimal size of the time bucket, as we discussed earlier, is 20 min because of our definition of prolonged sedentary behavior. In the experiments, we compared the accuracy of 9 time bucket sizes (20 min, 30 min, 40 min, 50 min, 1 h, 2 h, 3 h, 4 h, and 6 h). The 108 discriminative models are grouped by the time bucket sizes. For each time bucket size, there are 12 models—3 categories (SBPh, SBPc, and SBPa) × 4 lengths (1, 2, 3, and 4) of historical data used (orders).
Figure 22 shows the comparison between models with different sizes of time bucket. The X-axis is the model ID for the 12 models (e.g., SBPh1 means SBPh model with order 1). Each line in the chart represents a size setting of time bucket. The result shows that a 20-min time bucket is the best option among the 9 options, which appears to be a good balance between long and short term predictions. This finding confirms our initial intuition that on a longer timescale (e.g., 360-min time bucket), the dependence of future events to past events is weaker.
Fig. 22.

SBPh, SBPc, and SBPa models with different sizes of time bucket
Length of History
Intuitively, the more we learn about a person’s behavior history, the more accurate we can predict his future behavior using discovered patterns. However, it is not always true as several factors such as occupation type and unplanned events may alter a person’s schedule. For instance, call center representatives’ shifts may change every month. Using more than 1-week behavior history to predict their future sedentary behavior may yield inaccurate results as the model would not have learned their new schedules.
Figure 23 shows the comparison between SBPh, SBPc, and SBPa models using different lengths of history. The X-axis represents the length of history (number of 20-min buckets lookback) used by the model. The result generally confirms our initial guess—“more histories yield better prediction.” However, the benefit of increasing the length of history utilized is marginal beyond two 20-min time buckets.
Fig. 23.

SBPh, SBPc, and SBPa models using different lengths of history (number of 20-min buckets lookback)
Groups of Similar Subjects
As the old saying goes, “Birds of the same kind flock together” [62]. In both Western and East Asian philosophy and mathematics [63], a general phenomenon is commonly observed—people behave similarly to each other. If we can take advantage of such phenomena and predict subjects’ sedentary behaviors based on the patterns we learned from other people who are similar to them, we may be able to achieve more accurate prediction. Learning from similar subjects may provide good initialization values for our models. This is especially relevant when a subject initially starts to use the SBP models and we do not have enough historical data from the subject at the beginning.
To find people who are similar to each other, we need to quantitatively define “similarity” and group them by applying clustering algorithms. In this section, we define “similarity” based on a set of quantitative attributes which we call personal attributes ({a1, a2,⋯ ,an}). These attributes (a1, a2,⋯ ,an) can be used to characterize a person. Demographic information is a typical type of personal attributes, which would be valuable criteria for clustering subjects. But unfortunately, the StudentLife dataset does not provide such demographic information.3 From the dataset, the information one could characterize subjects using the similarity of their pre-study and post-study survey responses. We only use the pre-study survey responses in this research because our goal is to predict the future. Thus, we should not use information about the “future”—post-surveys.
The pre-survey in the StudentLife dataset consists of Big Five personality questions [64], Flourishing Scale positive and negative feeling questions [65], UCLA Loneliness Scale questions [66], Positive and Negative Affect Schedule (PANAS) questions [67], Perceived Stress Scale questions [68], PHQ-9 depression scale questions [69], Pittsburgh Sleep Quality Index (PSQI) questions [70], and Veterans RAND 12 Item Health Survey (VR12) questions [71]. Among the questions, 138 are designed to be answered on scales of 1 to 3, 1 to 5, or 1 to 7. These questions cover mental health, general health conditions, and personality. We clustered users in the StudentLife dataset based on their responses to these questions on the pre-survey.
Two clustering algorithms are experimented: Expectation–Maximization (EM) algorithm [72]—an iterative method to find maximum likelihood estimates of clusters an observation belongs to—and K-means [73]—an algorithm to partition observations into k clusters in which each observation belongs to the cluster with the nearest mean. For EM, a number of clusters are selected automatically. For K-means, we tested the number of clusters from 1 to 10 and found the number (= 5) with the highest likelihood. The clustering results are listed below:
- EM
- Cluster 0: {Subject 2, 3, 4, 7, 9, 12, 13, 16, 19, 22, 27, 34, 35, 39, 45, 51, 56, 57, 58}
- Cluster 1: {Subject 10, 17, 18, 23, 24, 31, 33, 52}
- Cluster 2: {Subject 0, 1, 5, 8, 14, 15, 20, 30, 32, 36, 42, 43, 44, 46, 47, 49, 50, 53, 59}
- K-means
- Cluster 0: {Subject 3, 4, 7, 12, 13, 16, 19, 22, 27, 39, 45, 51, 10, 31, 0, 1, 8, 15, 46, 53, 59}
- Cluster 1: {Subject 17}
- Cluster 2: {Subject 18, 23, 24, 33, 52}
- Cluster 3: {Subject 5, 14, 30, 47}
- Cluster 4: {Subject 2, 9, 34, 35, 56, 57, 58, 20, 32, 36, 42, 43, 44, 49, 50}
For each cluster, a discriminative SBPa model (leveraging all current and historical contextual behaviors and sedentary behaviors), with time bucket size set to 20 min and length of history used set to 4, is trained and used for prediction. In Fig. 24, the  bar represents the best predictive model (trained using all subjects’ data) achieved in previous experiments. The
bar represents the best predictive model (trained using all subjects’ data) achieved in previous experiments. The  bars represent the predictive models for each EM cluster respectively and the
bars represent the predictive models for each EM cluster respectively and the  bars represent the predictive models for each K-means cluster (using Euclid distance function) respectively.
bars represent the predictive models for each K-means cluster (using Euclid distance function) respectively.
Fig. 24.

Comparison of SBPa models trained for clusters
Generally, models trained with data from a given cluster have better predictive accuracy on members of this cluster than the models trained with everyone’s data. It is noteworthy that K-means Cluster 1 contains only one subject and has the best accuracy. This finding implies that we may consider training models for each person individually using his own data to achieve higher accuracy.
Time Consumption
All the SBP models we designed in this study were trained and tested on a Dell PowerEdge T20 server,4 which had an Intel Xeon E3-1225 v3 3.2GHz (turbo speed: 3.6 GHz, cores: 4, threads: 4) CPU5 and 16GB (2 × 8GB dual channel) DDR3 memory.
For the 108 discriminative SBP models, 10,896 to 196,803 instances—depending on the size of time bucket for discretization—are used for training and testing. Threefold cross-validation is used for evaluating the predictive models. As shown in Fig. 25, training discriminative SBP models on two-thirds of the dataset takes a significant amount of time. Also, as the order of the model increases, the training time increases especially, for SBPa models where the training time increases exponentially with model order. Please note that the Y-axis in Fig. 25 is in a logarithmic scale.
Fig. 25.

Time consumed for training SBPh, SBPc, and SBPa models with different orders and bucket sizes
On the other hand, testing time—time consumed for applying a trained model on a single instance—is substantially lower. For example, the training time for the SBPa4 model with a 20-min bucket size is 9 orders of magnitude higher than its testing time (37,810 s vs. 33 μs). Please note that the time shown in Fig. 26 is the average time consumed by testing a trained model on an instance. The unit of X-axis in Fig. 26 is microseconds (vs. seconds in Fig. 25).
Fig. 26.

Average time consumed for testing SBPh, SBPc, and SBPa models with different orders and bucket sizes on a single instance
In real-world scenarios, model training may not need to be done frequently as a user’s sedentary behavior patterns may not change very often. Also, this computationally expensive task could be done in the cloud to reduce the training time. We will expound on the discussion of this topic in the next section.
Summary of Predictive Models
Discriminative models uniformly outperform generative models when making context-aware predictions with the StudentLife dataset.
We can predict prolonged sedentary behaviors in the next 20 min better than prolonged sedentary behaviors with other lengths of time window.
Overall, Context-Aware Predictive (CAP) models leveraging information in both current and historical contextual behaviors and sedentary behaviors have higher accuracies.
Prediction accuracy can be improved by clustering users first and then building predictive models for each cluster. It is natural to extrapolate and guess that training models for each individual could yield even better accuracy. However, in real-world applications, we do not always have the historical data of each person initially, which makes it impossible to build predictive models at the beginning.
Discussion and Future Work
Real-World Performance
When being deployed with real-world smartphone applications, our proposed SBP models will encounter issues that did not exist in our experimental environment.
Missing data: “Missing values” will be the most common issue. In our experiments, missing data were not an issue because we trained and applied models on a large dataset (196,803 instances). However, when our models are utilized/applied in the real world, the chances of reliably having valid values for all input variables of our SBP models will be considerably lower. Data could be missing for different reasons. Sensors on smartphone may fail to acquire data as input for the model. For instance, GPS may have a spotty signal when a user’s smartphone is used indoors. The magnetometer could be interfered by nearby motors and speakers. The microphone could be covered by a cloth resulting in a noise or no sound being captured. Even if all sensors are working as expected, the smartphone operating system may kill our sensor data collection service running in the background.6 Finally, the user may choose to turn off their phones. Strategies for filling missing data and how they affect the accuracy of our SBP models in real-world applications are interesting questions we will address in our future work.
Training time: Another issue our proposed SBP models may face in the real world is expensive model training. Training does not only require large amounts of training data, but also takes a long time to train, especially the high-order SBPa model. For example, training the 4th order SBPa model in our experiment with 196,803 instances took more than 10 h. In the future, we believe such computationally expensive model training task could be performed in the cloud with more powerful servers, or it could be done using decentralized federated learning [74].
Health Behavior Intervention
On current generation of smartwatches such as the Apple Watch and Fitbit, sedentary alert systems are rather primitive. They either remind users to stand up and move for a minute every hour or ask users to walk at least 250 steps every hour (Fig. 27). We envision that our SBP models could be deployed in smartphone and smartwatch applications to predict users’ deleterious sedentary behaviors and to intervene before they even occur.
Fig. 27.

An example of Apple Watch’s “Stand Reminders” (left) and an example of Fitbit’s hourly 250-step “Reminders to Move” (right)
Our envisioned sedentary behavior prevention system consists of six parts (Fig. 28): (1) Sedentary behavior prediction module, a module based on a set of computational models—discussed in this paper—to predict a user’s future sedentary behavior based on a combination of historical behaviors and contexts; (2) Availability prediction module, a module based on a set of computational models to predict if a user will be available to accept interventions in future; (3) Determinant inference module, a module to infer the causes (e.g., occupation) of sedentary behaviors; (4) Intervention recommendation system, a recommendation system to retrieve the best suited intervention from a database of interventions; (5) Intervention delivery channel, a proper communication channel for delivering the intervention, e.g., smartwatch notification and SMS (if the system runs in cloud); and (6) Real-time monitor, an always-on monitor (e.g., smartphone or fitness tracker) tracking the user’s sedentary behavior to help evaluate whether previous interventions altered (e.g., improved) a user’s behavior.
Fig. 28.

Envisioned architecture of our sedentary behavior prevention system
In this study, the sedentary behavior prediction module has been tackled. In our previous work, real-time monitor and intervention delivery channel have been explored in On11 in [12], and real-time monitor has been researched and implemented as “RecFit” in [75]. In future, we would like to conduct a user study to evaluate our sedentary behavior prevention system with all modules integrated.
Conclusion
Sedentary behaviors now constitute a significant and growing public health problem, which have been associated with increased risk of several ailments including diabetes, cardiovascular disease, and all-cause mortality. Current interventions are mostly reactive. However, models that predict future sedentary behaviors from a user’s history can support prevention of sedentary behaviors. In this paper, we characterized user patterns of sedentary behaviors by analyzing smartphone-sensor data in a real-world dataset. Our work reveals the most predictive location types (where), times of day/week (when), and smartphone contexts. Building on our insights, we proposed a set of context-aware probabilistic models that can predict future sedentary behaviors from smartphone sensor data. Specifically, our Context-Aware Predictive (CAP) models leverage smartphone-sensed contextual variables and user’s history of sedentary behaviors to predict future sedentary behaviors. Our rigorous evaluation of our models demonstrates that they are reliable.
Declarations
Conflict of Interest
The authors declare no competing interests.
Footnotes
On the website of StudentLife project and in [11], the authors state that 48 students completed the study. The StudentLife dataset, however, contains 49 students’ data.
Hereafter, without explicit mention, superscripts used in notations are time indexes, not powers.
On the website of StudentLife project, the authors mentioned a “user_info.csv” file which might contain subjects’ demographic information. However, in the data publicly provided, such a file does not exist.
Dell PowerEdge T20 Owner’s Manual, https://dl.dell.com/topicspdf/poweredge-t20_owners-manual_en-us.pdf
Intel® Xeon® Processor E3-1225 v3 https://ark.intel.com/content/www/us/en/ark/products/75461/intel-xeon-processor-e3-1225-v3-8m-cache-3-20-ghz.html
“Don’t kill apps, make them work!” website, https://dontkillmyapp.com/
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Qian He, Email: qhe@wpi.edu.
Emmanuel O. Agu, Email: emmanuel@wpi.edu
References
- 1.Proctor RW, Van Zandt T (2008) Human factors in simple and complex systems. 2nd edn. Taylor & Francis. http://books.google.com/books?id=LfqDZ1VEmyoC
- 2.Centers for Disease Control and Prevention. Prevalence of Sedentary Leisure-time Behavior Among Adults in the United States (2010). https://www.cdc.gov/nchs/data/hestat/sedentary/sedentary.htm
- 3.Whitt-Glover MC, Taylor WC, Floyd MF, Yore MM, Yancey AK, Matthews CE. Disparities in physical activity and sedentary behaviors among US children and adolescents: Prevalence, correlates, and intervention implications. J Public Health Pol. 2009;30(S1):S309. doi: 10.1057/jphp.2008.46. [DOI] [PubMed] [Google Scholar]
- 4.Wilmot EG, Edwardson CL, Achana FA, Davies MJ, Gorely T, Gray LJ, Khunti K, Yates T, Biddle SJH. Sedentary time in adults and the association with diabetes, cardiovascular disease and death: systematic review and meta-analysis. Diabetologia. 2012;55(11):2895. doi: 10.1007/s00125-012-2677-z. [DOI] [PubMed] [Google Scholar]
- 5.Proper KI, Singh AS, van Mechelen W, Chinapaw MJM. Sedentary behaviors and health outcomes among adults: a systematic review of prospective studies. Amer J Prevent Med. 2011;40(2):174. doi: 10.1016/j.amepre.2010.10.015. [DOI] [PubMed] [Google Scholar]
- 6.Lees SJ, Booth FW. Sedentary death syndrome. Canadian J Appl Physiol. 2004;29(4):447. doi: 10.1139/h04-029. [DOI] [PubMed] [Google Scholar]
- 7.Pate RR, O’Neill JR, Lobelo F. The evolving definition of “sedentary”. Exer Sport Sci Rev. 2008;36(4):173. doi: 10.1097/JES.0b013e3181877d1a. [DOI] [PubMed] [Google Scholar]
- 8.Tremblay M. Letter to the Editor: Standardized use of the terms “sedentary” and “sedentary behaviours”. Appl Physiol Nutrit Metabol. 2012;37(3):540. doi: 10.1139/h2012-024. [DOI] [PubMed] [Google Scholar]
- 9.Consolvo S, Libby R, Smith I, Landay JA, McDonald DW, Toscos T, Chen MY, Froehlich J, Harrison B, Klasnja P, LaMarca A, LeGrand L (2008) Activity sensing in the wild: a field trial of ubifit garden. In: Proceeding of the twenty-sixth annual CHI conference on Human factors in computing systems - CHI ’08. 10.1145/1357054.1357335. http://dl.acm.org/citation.cfm?id=1357054.1357335. ACM Press, New York, p 1797
- 10.Lane N, Mohammod M, Lin M, Yang X, Lu H, Ali S, Doryab A, Berke E, Choudhury T, Campbell A (2011) BeWell: a smartphone application to monitor, model and promote wellbeing. In: Proceedings of the 5th international ICST conference on pervasive computing technologies for healthcare. 10.4108/icst.pervasivehealth.2011.246161. http://eudl.eu/doi/10.4108/icst.pervasivehealth.2011.246161
- 11.Wang R, Chen F, Chen Z, Li T, Harari G, Tignor S, Zhou X, Ben-Zeev D, Campbell AT (2014) StudentLife: assessing mental health, academic performance and behavioral trends of college students using smartphones. In: Proceedings of the 2014 ACM international joint conference on pervasive and ubiquitous computing - UbiComp ’14 Adjunct. 10.1145/2632048.2632054. http://dl.acm.org/citation.cfm?id=2632048.2632054. ACM Press, New York, pp 3–14
- 12.He Q, Agu E (2014) On11: An activity recommendation application to mitigate sedentary lifestyle. In: Proceedings of the 2014 workshop on physical analytics - WPA ’14. 10.1145/2611264.2611268. http://dl.acm.org/citation.cfm?doid=2611264.2611268. ACM Press, New York, pp 3–8
- 13.Apple Inc. Apple Watch (2015). http://www.apple.com/watch/
- 14.Fitbit Inc. Fitbit (2013). http://www.fitbit.com/
- 15.Ajzen I. The theory of planned behavior. Organ Behav Human Decis Process. 1991;50(2):179. doi: 10.1016/0749-5978(91)90020-T. [DOI] [Google Scholar]
- 16.Abowd GD, Dey AK, Brown PJ, Davies N, Smith M, Steggles P (1999) Towards a better understanding of context and context-awareness. 304–307. 10.1007/3-540-48157-5_29. http://link.springer.com/10.1007/3-540-48157-5_29
- 17.Shaw RJ, Steinberg DM, Zullig LL, Bosworth HB, Johnson CM, Davis LL. mHealth interventions for weight loss: a guide for achieving treatment fidelity. J Ameri Med Inf Assoc : JAMIA. 2014;21(6):959. doi: 10.1136/amiajnl-2013-002610. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Patel AV, Bernstein L, Deka A, Feigelson HS, Campbell PT, Gapstur SM, Colditz GA, Thun MJ. Leisure time spent sitting in relation to total mortality in a prospective cohort of US adults. Amer J Epidemiol. 2010;172(4):419. doi: 10.1093/aje/kwq155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Thorp AA, Owen N, Neuhaus M, Dunstan DW. Sedentary behaviors and subsequent health outcomes in adults a systematic review of longitudinal studies, 1996-2011. Amer J Prevent Med. 2011;41(2):207. doi: 10.1016/j.amepre.2011.05.004. [DOI] [PubMed] [Google Scholar]
- 20.Chen G, Kotz D. A survey of context-aware mobile computing research. Dartmouth Comput Sci Tech Report. 2000;3755:1. [Google Scholar]
- 21.Schilit BN, Adams N, Want R (1994) Context-aware computing applications. Context-Aware Comput Appl. 10.1109/MCSA.1994.512740. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4624429
- 22.Indulska J, Sutton P. Location management in pervasive systems. Conf Res Pract Inf Technol Ser. 2003;34:143. [Google Scholar]
- 23.Baldauf M, Dustdar S, Rosenberg F. A survey on context-aware systems. Int J Ad Hoc Ubiquit Comput. 2007;2(4):263. doi: 10.1504/IJAHUC.2007.014070. [DOI] [Google Scholar]
- 24.LiKamWa R, Liu Y, Lane ND, Zhong L (2013) MoodScope: building a mood sensor from smartphone usage patterns. In: Proceeding of the 11th annual international conference on Mobile systems, applications, and services - MobiSys ’13. 10.1145/2462456.2464449. http://dl.acm.org/citation.cfm?doid=2462456.2464449. ACM Press, New York, p 389
- 25.Pielot M, Dingler T, Pedro JS, Oliver N (2015) When attention is not scarce - detecting boredom from mobile phone usage. In: Proceedings of the 2015 ACM international joint conference on pervasive and ubiquitous computing - UbiComp ’15. 10.1145/2750858.2804252. http://dl.acm.org/citation.cfm?doid=2750858.2804252. ACM Press, New York, pp 825–836
- 26.Anderson M (2015) U.S. Technology Device Ownership 2015. http://www.pewinternet.org/2015/10/29/technology-device-ownership-2015/
- 27.Bettini C, Brdiczka O, Henricksen K, Indulska J, Nicklas D, Ranganathan A, Riboni D. A survey of context modelling and reasoning techniques. Perv Mobile Comput. 2010;6(2):161. doi: 10.1016/j.pmcj.2009.06.002. [DOI] [Google Scholar]
- 28.Klasnja P, Consolvo S, McDonald DW, Landay JA, Pratt W (2009) AMIA... Annual Symposium proceedings. AMIA Symposium 2009, 338. http://www.ncbi.nlm.nih.gov/pubmed/20351876http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC2815473 [PMC free article] [PubMed]
- 29.Lin Y (2013) Motivate : a context-aware mobile application for physical activity promotion. Ph.D. thesis, Technische Universiteit Eindhoven. http://repository.tue.nl/750185
- 30.He Q (2014) A Context-aware smartphone application to mitigate sedentary lifestyle. Ph.D. thesis, Worcester Polytechnic Institute. https://www.wpi.edu/Pubs/ETD/Available/etd-092914-135436/
- 31.Klein M, Mogles N, van Wissen A. An intelligent coaching system for therapy adherence. IEEE Perv Comput. 2013;12(3):22. doi: 10.1109/MPRV.2013.41. [DOI] [Google Scholar]
- 32.Pentland A, Liu A. Modeling and prediction of human behavior. Neural Comput. 1999;11(1):229. doi: 10.1162/089976699300016890. [DOI] [PubMed] [Google Scholar]
- 33.Viard K, Fanti MP, Faraut G, Lesage JJ (2020) Human activity discovery and recognition using probabilistic finite-state automata. IEEE Trans Automa Sci Eng 17 10.1109/TASE.2020.2989226
- 34.Baum LE, Petrie T. Statistical inference for probabilistic functions of finite state markov chains. Ann Math Stat. 1966;37(6):1554. doi: 10.1214/aoms/1177699147. [DOI] [Google Scholar]
- 35.Lafferty JD, McCallum A, Pereira FCN (2001) Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of the eighteenth international conference on machine learning, ICML ’01. http://dl.acm.org/citation.cfm?id=645530.655813. Morgan Kaufmann Publishers Inc., San Francisco, pp 282–289
- 36.Friedman N, Geiger D, Goldszmidt M. Bayesian network classifiers. Mach Learn. 1997;29:131. doi: 10.1023/A:1007465528199. [DOI] [Google Scholar]
- 37.Atallah L, Yang GZ. The use of pervasive sensing for behaviour profiling – a survey. Perv Mobile Comput. 2009;5(5):447. doi: 10.1016/j.pmcj.2009.06.009. [DOI] [Google Scholar]
- 38.He Q, Agu EO (2017) A rhythm analysis-based model to predict sedentary behaviors. IEEE 383–391. 10.1109/CHASE.2017.122. http://ieeexplore.ieee.org/document/8010677/
- 39.He Q, Agu E (2016) Towards sedentary lifestyle prevention: an autoregressive model for predicting sedentary behaviors. In: IEEE 10Th international symposium on medical information and communication technology (ISMICT ’16) (Worcester, MA, USA)
- 40.He Q, Agu E (2016) A frequency domain algorithm to identify recurrent sedentary behaviors from activity time-series data. In: 2016 IEEE-EMBS international conference on biomedical and health informatics (BHI). 10.1109/BHI.2016.7455831, pp 45–48
- 41.Kańtoch E. Recognition of sedentary behavior by machine learning analysis of wearable sensors during activities of daily living for telemedical assessment of cardiovascular risk. Sensors. 2018;18:8–12. doi: 10.3390/s18103219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Bhattacharjee P, Kar SP, Rout NK (2020) Sleep and sedentary behavior analysis from physiological signals using machine learning. IEEE. 10.1109/ICIMIA48430.2020.9074883
- 43.Cook DJ, Krishnan NC. Activity learning, discovering, recognizing, and predicting human behavior from sensor data. Hoboken: Wiley; 2015. [Google Scholar]
- 44.Fahim M, Baker T, Khattak A, Shah B, Aleem S, Chow F. Context mining of sedentary behaviour for promoting self-awareness using a smartphone. Sensors. 2018;18:8–12. doi: 10.3390/s18030874. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Nweke HF, Teh YW, Al-garadi MA, Alo UR. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: state of the art and research challenges. Expert Syst Appl. 2018;105:196–206. doi: 10.1016/j.eswa.2018.03.056. [DOI] [Google Scholar]
- 46.Kong Y, Fu Y (2018) Human action recognition and prediction: a survey. arXiv:1806.11230
- 47.Li X, Ge Y, Li W, Ma C (2018) A quantitative system of sedentary condition based on wireless body area network. 10.1007/978-3-319-97795-9_11
- 48.Do TMT, Gatica-Perez D (2012) Contextual conditional models for smartphone-based human mobility prediction. In: Proceedings of the 2012 ACM conference on ubiquitous computing - UbiComp ’12. 10.1145/2370216.2370242. http://dl.acm.org/citation.cfm?doid=2370216.2370242. ACM Press, New York, p 163
- 49.Mansoor H, Gerych W, Alajaji A, Buquicchio L, Chandrasekaran K, Agu E, Rundensteiner EA. Visual analytics of smartphone-sensed human behavior and health. IEEE Comput Graph Appl. 2021;41:98–101. doi: 10.1109/MCG.2021.3062474. [DOI] [PubMed] [Google Scholar]
- 50.Thorp AA, Healy GN, Winkler E, Clark BK, Gardiner PA, Owen N, Dunstan DW. Prolonged sedentary time and physical activity in workplace and non-work contexts: a cross-sectional study of office, customer service and call centre employees. Int J Behav Nutrit Phys Activ. 2012;9(1):128. doi: 10.1186/1479-5868-9-128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Matthews CE, Chen KY, Freedson PS, Buchowski MS, Beech BM, Pate RR, Troiano RP. Amount of time spent in sedentary behaviors in the United States, 2003-2004. Amer J Epidemiol. 2008;167(7):875. doi: 10.1093/aje/kwm390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Cornell university ergonomics. sitting and standing at work (2016). http://ergo.human.cornell.edu/CUESitStand.html
- 53.Xu Y, Lin M, Lu H, Cardone G, Lane N, Chen Z, Campbell A, Choudhury T (2013) Preference, context and communities: a multi-faceted approach to predicting smartphone app usage patterns. In: Proceedings of the 17th annual international symposium on international symposium on wearable computers - ISWC ’13. 10.1145/2493988.2494333. http://dl.acm.org/citation.cfm?doid=2493988.2494333. ACM Press, New York, p 69
- 54.Barkhuus L, Dourish P (2004) Everyday encounters with context-aware computing in a campus environment. In: Davies N, Mynatt E, Siio I (eds) UbiComp 2004: Ubiquitous Computing SE - 14, Lecture Notes in Computer Science. 10.1007/978-3-540-30119-6_14, vol 3205. Springer Berlin Heidelberg, pp 232–249
- 55.Pearson K. Note on regression and inheritance in the case of two parents. Proc R Soc Lond. 1895;58:240. doi: 10.1098/rspl.1895.0041. [DOI] [Google Scholar]
- 56.Dartmouth college. Hopkins center for the arts (2013). https://hop.dartmouth.edu/
- 57.Eagle N, Pentland A. Eigenbehaviors: identifying structure in routine. Behav Ecol Sociobiol. 2009;63(7):1057. doi: 10.1007/s00265-009-0739-0. [DOI] [Google Scholar]
- 58.Rish I. An empirical study of the naive Bayes classifier. IJCAI 2001 Workshop on Empirical Methods in Artif Intell. 2001;3(22):41–46. [Google Scholar]
- 59.Sutton C, McCallum A (2010) An introduction to conditional random fields. arXiv:1011.4088
- 60.Chung S (2015) Breaking down prediction errors in machine learning. Tech. rep., Alpine Data. http://alpinedata.com/wp-content/uploads/2015/12/ML-Whitepaper_12.29.pdf
- 61.Agre PE (1988) The dynamic structure of everyday life. Tech. rep., Cambridge, MA USA
- 62.Turner W (1545) Winchester: Gardiner
- 63.Chemla K. The mathematics of Egypt, Mesopotamia, China, India, and Islam. A sourcebook. Historia Math. 2012;39(3):324. doi: 10.1016/j.hm.2012.04.003. [DOI] [Google Scholar]
- 64.Mount MK, Barrick MR. The Big Five personality dimensions: implications for research and practice in human resources management. Res Personnel Human Resour Manag. 1995;13(3):153. [Google Scholar]
- 65.Diener E, Wirtz D, Tov W, Kim-Prieto C, Choi DW, Oishi S, Biswas-Diener R. New well-being measures: short scales to assess flourishing and positive and negative feelings. Soc Indic Res. 2010;97(2):143. doi: 10.1007/s11205-009-9493-y. [DOI] [Google Scholar]
- 66.Russell DW. UCLA loneliness scale (Version 3): reliability, validity, and factor structure. J Person Assess. 1996;66(1):20. doi: 10.1207/s15327752jpa6601_2. [DOI] [PubMed] [Google Scholar]
- 67.Watson D, Clark LA, Tellegen A. Development and validation of brief measures of positive and negative affect: The PANAS scales. J Person Social Psychol. 1988;54(6):1063. doi: 10.1037/0022-3514.54.6.1063. [DOI] [PubMed] [Google Scholar]
- 68.Cohen S, Kamarck T, Mermelstein R. A global measure of perceived stress. J Health Soc Behav. 1983;24(4):385. doi: 10.2307/2136404. [DOI] [PubMed] [Google Scholar]
- 69.Kroenke K, Spitzer RL, Williams JBW. The PHQ-9. J Gen Internal Med. 2001;16(9):606. doi: 10.1046/j.1525-1497.2001.016009606.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Buysse DJ, Reynolds CF, Monk TH, Berman SR, Kupfer DJ. The Pittsburgh sleep quality index: a new instrument for psychiatric practice and research. Psychiat Res. 1989;28(2):193. doi: 10.1016/0165-1781(89)90047-4. [DOI] [PubMed] [Google Scholar]
- 71.Selim AJ, Rogers W, Fleishman JA, Qian SX, Fincke BG, Rothendler JA, Kazis LE. Updated U.S. population standard for the Veterans RAND 12-item health survey (VR-12) Qual Life Res. 2009;18(1):43. doi: 10.1007/s11136-008-9418-2. [DOI] [PubMed] [Google Scholar]
- 72.Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J Royal Stat Soc Ser B (Methodological) 1977;39(1):1. [Google Scholar]
- 73.Macqueen J et al (1967) Some methods for classification and analysis of multivariate observations
- 74.Advances and open problems in federated learning (2019). arXiv:1912.04977
- 75.He Q, Agu E, Strong D, Tulu B (2014) RecFit: a context-aware system for recommending physical activities. In: Proceedings of the 1st workshop on mobile medical applications - MMA ’14. 10.1145/2676431.2676439. http://dl.acm.org/citation.cfm?doid=2676431.2676439. ACM Press, New York, pp 34–39