
Extended Data Figure 3.
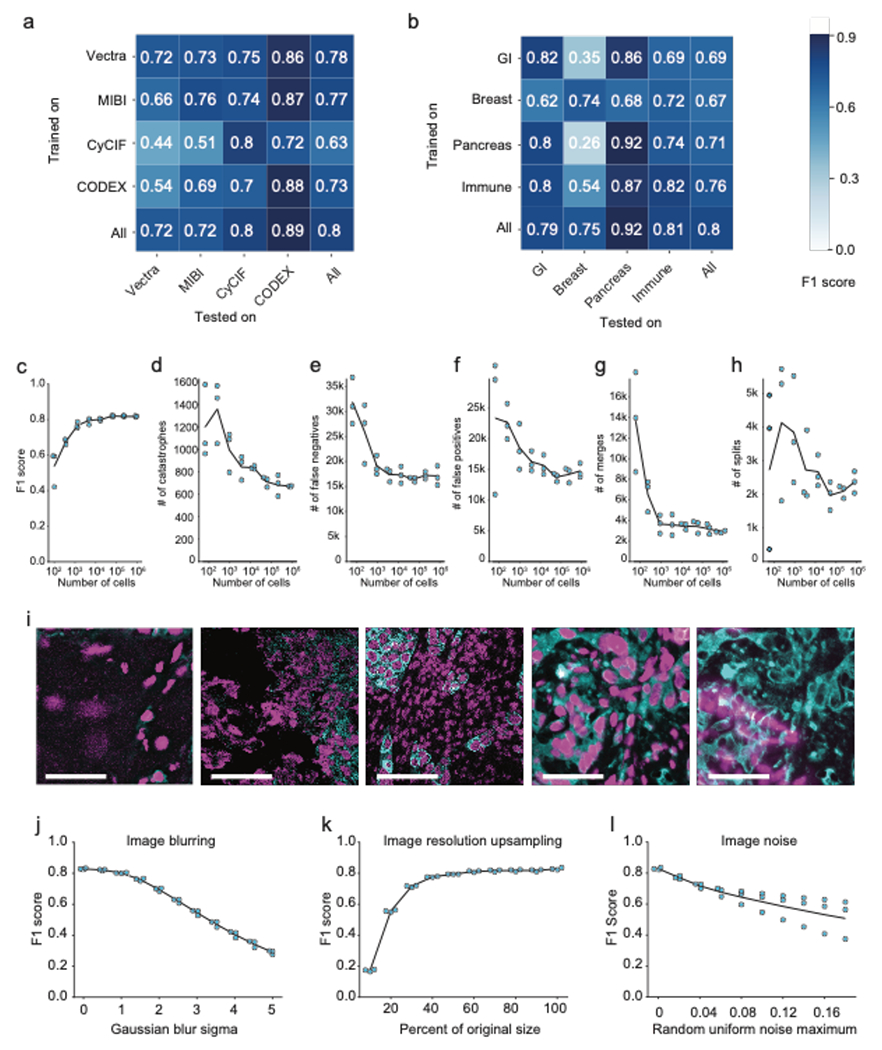
a, Accuracy of specialist models trained on each platform type (rows) and evaluated on data from other platform types (columns) indicates good agreement within immunofluorescence and mass spectrometry-based methods, but not across distinct methods. b, Accuracy of specialist models trained on each tissue type (rows) and evaluated on data from other tissue types (columns) demonstrates that models trained on only a single tissue type do not generalize as well to other tissue types. c, Quantification of F1 score as a function of the size of the dataset used for training. d-h, Quantification of individual error types as a function of the size of the dataset used for training. i, Representative images where Mesmer accuracy was poor, as determined by the image specific F1 score. j, Impact of image blurring on model accuracy. k, Impact of image downsampling and then upsampling on model accuracy. l, Impact of adding random noise to image on model accuracy. All scale bars are 50 μM.