

Abstract
The main objective of Statistics of Extremes is the estimation of probabilities of rare events. When extending the analysis of the limiting behaviour of the extreme values from independent and identically distributed sequences to stationary sequences a key parameter appears, the extremal index θ, whose accurate estimation is not easy. Here we focus on the estimation of θ using blocks estimators, that can be constructed by using disjoint or sliding blocks. The asymptotic properties for both procedures were studied and compared but both blocks estimators require the choice of a threshold and a block length. Some criteria have appeared for the choice of those nuisance quantities but some research is still needed. We will show how the threshold and the block size choices can affect the estimates. However the main objective of this work is to revisit another estimation procedure that only depends on the block length, although some conditions on the underlying process need to be verified. The associated estimator presents nice asymptotic properties, and for finite samples is here illustrated a stability criterion for choosing the block length and then obtaining the θ estimate. A large simulation study has been performed and an application to daily mean flow discharge rate in the hydrometric station of Fragas da Torre in river Paiva, data collected from 1 October 1946 to 30 April 2012 is done.
Keywords: Blocks estimators, dependence conditions, extremal index, statistics of extremes
2010 Mathematics Subject Classifications: 62P12, 90-08, 62G32, 62G05
1. Motivation and introduction
Extreme Value Theory is an area of increasingly vast applications in a very large range of environmental problems, such as burned areas (Díaz-Delgado et al. [8] and Schoenberg et al. [24]) and earthquake thermodynamics (Lavenda and Cipollone [16]), to mention a few recent applications. In many cases, another phenomenon can be observed, namely the presence of clustering of very large or very small values (extremes) of the data. Figure 1 displays the occurrence of clusters of high values in a case study of daily mean flow discharge rate values () from the hydrometric station at Fragas da Torre collected from the ‘SNIRH: Sistema Nacional de Informação dos Recursos Hídricos’. A pronounced temporal clustering of the extreme values can be seen, indicating the presence of local dependence in the extremes. Therefore, quantifying the nature of the dependence structure as well as the duration of extreme events becomes an essential part of the understanding of this time series data.
Figure 1.

Daily mean flow discharge rate values () from 1 November 1946 to 30 April 1947 and from 1 November 1947 to 30 April 1948 from hydrometric station at Fragas da Torre.
The extremal index (EI), usually denoted by θ, is the main parameter that describes and quantifies the clustering characteristics of the extreme values in many stationary time series. Its formal definition is given in Section 2.
This work was motivated by that real case, with the objective of studying and comparing methods to estimate the EI. Classical inference for the cluster size distribution has been mainly based in the blocks method and in the runs method, see Smith and Weissman [26] and Weissman and Novak [28]. Those procedures require that the block size and the threshold be chosen, and the estimates strongly depend on that choice. We will illustrate that dependence for some stationary processes and some finite samples generated from those processes.
In Section 2, we introduce the notations used throughout the article, the definition and some probabilistic characterizations of the EI are briefly reminded. Those characterizations gave rise to the definition of some estimators. The blocks estimator, Weissman and Novak [28], will be the classical estimator to be considered as a comparison with another blocks estimator, derived under some conditions on the stationary process and a different definition of blocks. In Section 3. the classical blocks method, properties of blocks estimators and their difficulties are discussed and illustrated through some simulated samples. The new approach for defining blocks and the conditions for the definition of a new estimator are presented in Section 4. Consistence and asymptotic distributional properties of the estimator are studied. The EI estimation under this approach is illustrated for some simulated samples. In Section 5 an heuristic procedure based on a stability criterion is considered to automatically choose the block size and to obtain the θ estimate. The real case study that motivated this study, will be considered in Section 6 and some general comments are pointed out in Section 7.
2. Extremal index: definition and characterization
In many practical applications extreme conditions often persist over several consecutive observations. Under adequate general local and asymptotic dependence conditions, the limiting point process of exceedances of a high level by , after a suitable normalization is a homogeneous compound Poisson process with intensity and limiting cluster size distribution, π (Hsing et al. [14]). That constant θ, EI, has an important role in extreme value theory for weakly dependent processes, reflecting the effect of clustering of extremes observation on the limiting distribution of the maximum. The EI is the quantity that measures the amount of clustering of the extremes in a stationary sequence.
Definition 2.1 Leadbetter et al. [18] —
Suppose that is a strictly stationary sequence of random variables with marginal distribution function (d.f.) F. This sequence is said to have an extremal index if, for each , there exists a sequence of levels , such that
where .
When the exceedances of high thresholds tend to occur isolated, as in the independent context. If we have groups of exceedances in the limit.
The EI measures the relationship between the dependence structure of the data and the behavior of the exceedances over a high threshold .
Dependence in stationary sequences can take different forms, and it is impossible to develop a general characterization of the behavior of extremes unless some constraints are imposed. It is usual to assume a condition that limits the extend of long-range dependence at extreme levels, so that the events and are approximately independent, provided that u is high enough, and time points i and j have a large separation. Let us denote , the joint d.f. of for any arbitrary positive integers .
Definition 2.2 condition (Leadbetter et al. [18]) —
The condition holds for a stationary sequence if for every integers p, q and such that , we have
where for some sequence .
Let be a strictly stationary sequence of random variables that satisfies the condition of Leadbetter et al. [18] and has a marginal distribution function F. For large n and ,
Further, if there exist normalizing constants and such that then is the distribution function of a GEV distribution, and
The corresponding result for where are independent variables with distribution function F, gives the limiting distribution function . Hence, the EI is a key parameter for the distribution of sample extremes.
For illustration of the behaviour of a stationary process compared with the correspondent i.i.d. sequence and the effect let us consider the following example:
Example 2.3 A Moving Maximum Process, (Süveges [27]) —
Let be a sequence of i.i.d. uniform variables on with F the common d.f.. Let be the 4-dependent moving maxima sequence, defined as
(1) The marginal underlying distribution for is and we have , see Süveges [27]. Consider also an i.i.d. sequence with the same d.f. .
Figure 2 shows one realization of the process [M1] and of . Four-sized clusters of exceedances of high levels can be seen when is plotted, while for only isolated values appear.
Figure 2.

One realization of an i.i.d. process and a 4-dependent moving maxima process.
The next example illustrates the behaviour of a stationary process for different values of EI.
Example 2.4 A Max-Autoregressive Process I, (Beirlant et al. [2]) —
Let be a sequence of i.i.d., unit-Fréchet. For , let
(2) For , x>0, , as , so the EI of the sequence is θ, see Beirlant et al. [2].
Figure 3 shows partial realizations of the process [M2] with and 0.9, respectively. The maxima show increasing clustering as . Notice also again a ‘shrinkage of maximum values’ as dependence increases.
Figure 3.

Samples of size n = 150 from M2 process, generated for , and .
Estimation of the EI is often based on the interpretation of θ due to Hsing et al. [14] as the reciprocal of the mean cluster size in the point process of exceedance times over a high threshold. Under a mixing condition which is slightly stronger than those authors showed that the point process of exceedances converge weakly to a compound Poisson process, provided that , i.e. a normalized level. The distribution of the cluster sizes is given by
for , and , and denoting the indicator function. Under additional summability conditions on the ,
i.e. the limiting mean number of exceedances of in an interval of length corresponds to the arithmetic inverse of the EI. So, we can write,
i.e. the mean cluster size in the limiting point process of exceedance times over high thresholds. This suggest that a suitable way to estimate the EI is to identify clusters of high levels exceedances, and to calculate the mean size of these clusters. By the way in which clusters are identified, the estimators fall apart in two types: blocks estimator and runs estimator (Smith and Weissman [26]; Weissman and Novak [28]; Hsing [13]). These estimators usually depend on two quantities to be chosen by the statistician: a threshold sequence and a cluster identification scheme parameter, such as the block size or the run length. In addition to the runs and blocks estimators of EI, two other estimators have recently been proposed: a two-threshold method (Laurini and Tawn [15]), and the intervals-estimator (Ferro and Segers [12]). The two-threshold method requires the choice of two declustering parameters. In contrast, inter-exceedance type estimators are attractive since they only depend on a threshold sequence.
Statistical properties, such as consistence and asymptotic distributional behaviour of those estimators are well documented in the aforementioned papers.
3. The blocks method to define clusters of exceedances
The blocks method consists of partitioning the n observations into consecutive contiguous blocks of a certain length, . In each block, the number of exceedances over a certain high threshold are counted, and the blocks estimator is then defined as the reciprocal of the average number of exceedances per block among blocks with at least one exceedance, defined by,
| (3) |
This blocks estimator of the EI has been intensively studied in the literature. Hsing [13] and Weissman and Novak [28] proved its consistency and asymptotic normality under suitable mixing conditions.
Variants of the blocks estimator were also examined by Smith and Weissman [26] and Robert et al. [23]. Blocks estimators can be constructed considering continuous blocks or sliding blocks. The asymptotic properties for both procedures were studied and compared in Robert et al. [23]. However, for both procedures the blocks estimator requires the choice of a threshold, , and a block size, . But, the behaviour of the estimates depend strongly of and . Some recent works trying to deal with that situation can be mentioned, such as Berghaus and Bücher [3], Drees ([9,10]) and Northop [21].
Let us consider some other models that will be used in the simulation study to illustrate how the estimates depend on and .
Example 3.1 A Max-Autoregressive Process II, (Alpuim [1]) —
Let be a sequence of independent, unit-Fréchet distributed random variables and a random variable with d.f. . For , let
(4) The EI of this process is , see Alpuim [1].
Example 3.2 A Second order autoregressive process, (Süveges [27]) —
Let be a sequence of independent, unit-Fréchet distributed random variables. Let be the second order autoregressive process, defined as
(5) The EI of this process is approximately 0.23, see Süveges [27].
Example 3.3 A Stochastic process, (Smith and Weissman [26]) —
Let be independent, distributed Bernoulli random variables with and be independent and identically distributed random variables, also independent of . The process is defined as follows:
(6) The marginal d.f. of is F, the cluster sizes have geometric distribution with mean , hence the EI of this process is θ, see Smith and Weissmank [26].
Example 3.4 A Max-Autoregressive Process III, (Smith [25]) —
Let be a sequence of independent, standard Gumbel distributed random variables. For fixed α define
(7) The EI of this process is , see Smith [25].
Example 3.5 A Moving Autoregressive process of order 2, (Reiss and Thomas [22]) —
Let be a sequence of independent, Pareto distributed random variables with tail index . Define
(8) The EI of this process is , see Reiss and Thomas [22].
Figures 4 and 5 display blocks EI-estimates based on exceedances over a high threshold , where are the ascending order statistics (o.s.), associated to the sample . For each process [M1-M7] a sample of size n = 1000 was generated and the estimates were calculated for several block lengths, .
Figure 4.

Estimates of plotted against k (), of a sequence of length n = 1000, with block lengths , for the [M1] process (upper left), [M2] process (upper right), [M3] process (lower left) and [M4](lower right).
Figure 5.

Estimates of plotted against k (), of a sequence of length n = 1000, with block lengths , for the [M5] process (left), [M6] process (center), [M7] process (right).
The estimates are almost monotones functions in and monotonically decreasing when the block lengths increases. It seems difficult to decide what should be chosen, there is some block size for which the path estimates do not cross the true value of the parameter. On the other hand the region of EI-estimates that shows some stability around the true value of the parameter depends on and even for a given , it is not obvious how to choose the threshold appropriately.
4. A new approach for the blocks method estimator
We will consider here an estimator, introduced in Canto e Castro [5] who suggested a different approach to define the threshold inside each block. This approach works under a local dependence condition, , of Chernick et al. [6] based on Leadbetter and Nandagopalan [17] results. condition, restricting rapid oscillations at high levels, requires the validity of the dependence condition and is defined as:
Definition 4.1
Let be a stationary sequence of random variables. is said to be satisfied if
(9) with verifying the condition and a sequence of block sizes such that and .
This condition locally restricts the occurrence of two or more upcrossings, but still allows clustering of exceedances.
The proposed estimator, Canto e Castro [5], was defined in the following way: let denote the number of blocks, and the respective block size. Let be a sequence of levels such that
| (10) |
Denoting as the number of up-crossing of in block, the estimator is defined by
| (11) |
The properties of the estimator , in (11), were studied in Canto e Castro [5] and here will be presented the Theorems therein included. Let us first recall some notations:
- Leadbetter and Nandagopalan [17] showed that, under regular conditions, the point process of up-crossings
converges to a Poisson point process with intensity that depends on the level and θ. - Let denotes the probability of a up-crossing can occur (not depending on the instant j due to the stationarity)
(12)
The following Theorems that present conditions for consistence and the asymptotic normality of the estimator , in (11) are due to Canto e Castro [5] and there can be found the respective proves.
Theorem 4.2
Let be a stationary sequence of random variables that satisfies and conditions for a sequence of levels such that .
Then , where is a Poisson process in with intensity ν.
If, further, has extremal index θ, then
Theorem 4.3
Let be a sequence of positive numbers such that and . Let us suppose that the stationary sequence of random variables, has extremal index θ and satisfies and conditions, and that exists such that , for levels such that , then
Theorem 4.4
If conditions established in Theorem 4.3 hold for levels such that , , then the estimator is consistent.
Theorem 4.5
In conditions established in Theorem 4.3, if , and if, for each Lindeberg's condition for levels such that then
Theorem 4.6
Suppose in addition to the conditions of Theorem 4.5 that
for levels such that then
where .
Theorem 4.7
Suppose in addition to the conditions of Theorem 4.6 that
Then
The estimator in (11) depends on the validity of condition, that can be checked by calculating the proportion of the anti- events among the exceedances for a range of thresholds and block sizes, given and , see Süveges [27], given by
| (13) |
for the observed sequence .
Examples are given in Figures 6–8 with [M1] process satisfying condition , with very low values of . However [M2], [M3], [M5], [M6] and [M7] processes depend on value of θ, showing higher values of for high values of θ and small values of for small values of θ.
Figure 6.

The observed proportions of for the [M1–M3] process with (from left to right).
Figure 7.

The observed proportions of for the [M4–M6] process with (from left to right).
Figure 8.
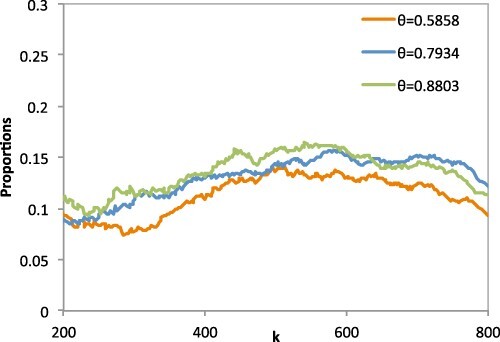
The observed proportions of for the [M7] process with .
Indeed processes [M2], [M3] and [M6] which are a special case of the general MARMA(p,q) processes introduced by Davis and Resnick [7] satisfies condition (9) for small values of θ, see Ferreira [11] and Martins and Sebastião [19]. Process [M4] does not verify that condition, see Süveges [27].
To apply this estimator to a given sample the levels should be chosen verifying However the joint distribution of is unknown and so the is. Under the validity of the condition, it seems reasonable to substitute , in each block, by adequate levels such that the number of up-crossings is equal to 1, but low enough to identify exceedances. More precisely, we can define,
| (14) |
For each of processes (even for process [M4], for which we know that condition is not verified) a n = 1000 sample-sized was generated and the estimator in (11) was applied. Figures 9 and 10 display the estimates obtained in each process for several values of block length.
Figure 9.

Estimates of of a sequence of length n = 1000, for different blocks lengths, from the [M1] process, (upper left); [M2] process (upper right); [M3] process (lower left) and [M4] process (lower right).
Figure 10.

Estimates of of a sequence of length n = 1000, for different blocks lengths, from the [M5] process, (left); [M6] process (middle); [M7] process (right).
For processes [M2], [M3] and [M6] the procedure presents very good results, a large stability region, very close to the true value of the parameter. It seems that we can consider the small value for for which a stability of the estimates path is obtained, and to estimate θ using that value of .
For the [M4] process, for which the condition is not verified, the stability region stays very far away from the true value of the parameter.
5. A choice of : an heuristic sample path stability criterion
A path stability algorithm, see Caeiro and Gomes [4] and Neves et al. [20] has revealed quite nice results for extreme value parameters estimation and can now be adapted to the choice of and to obtain a θ estimate. Let us see the description of the algorithm, for estimator:
Given an observed sample , compute the observed values of for a range of values of (in our simulations we have considered ).
Obtain the rounded values, to 0 decimal places, of the estimates in the previous step. Define , , the rounded values of to 0 decimal places.
Consider the sets of r values associated to equal consecutive values of , obtained in Step 2. Set and the minimum and maximum values, respectively, of the set with the largest range. The largest run size is then .
Consider all estimates, , for , now with two extra decimal places, i.e. compute . Obtain the mode of and denote the set of r-values associated with this mode.
Take as the maximum value of , and consider the adaptive estimate .
The best estimate is the value of that corresponds to the maximum run size computed in Step 3.
Table 1 present the result of an application of the algorithm to samples generated from models [M1–M7], with the choice of , , and the associated estimates.
Table 1. Values of and the best estimates, , for samples simulated from models [M1–M7], and n = 500, 1000, 2000, 5000 samples-sized.
| n = 500 | n = 1000 | n = 2000 | n = 5000 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | θ | ||||||||
| M1 | 0.25 | 95 | 0.1405 | 245 | 0.1423 | 490 | 0.1424 | 1200 | 0.1428 |
| M2 | 0.1 | 90 | 0.1017 | 155 | 0.1086 | 195 | 0.1005 | 995 | 0.1204 |
| 0.5 | 85 | 0.5219 | 190 | 0.5257 | 315 | 0.5395 | 445 | 0.5188 | |
| 0.9 | 105 | 0.9 | 200 | 0.9 | 395 | 0.9089 | 830 | 0.9117 | |
| M3 | 0.1 | 90 | 0.1071 | 195 | 0.1121 | 320 | 0.1131 | 995 | 0.1174 |
| 0.5 | 65 | 0.5053 | 120 | 0.5144 | 270 | 0.5174 | 550 | 0.5266 | |
| 0.9 | 95 | 0.8668 | 240 | 0.8986 | 355 | 0.9027 | 1225 | 0.9116 | |
| M4 | 0.23 | 105 | 0.608 | 60 | 0.6076 | 425 | 0.5568 | 1245 | 0.5386 |
| M5 | 0.1 | 70 | 0.0418 | 135 | 0.0491 | 495 | 0.0584 | 1225 | 0.0596 |
| 0.5 | 75 | 0.3421 | 240 | 0.3748 | 230 | 0.3436 | 520 | 0.3476 | |
| 0.9 | 45 | 0.7855 | 245 | 0.8931 | 385 | 0.848 | 1055 | 0.8392 | |
| M6 | 0.1813 | 115 | 0.2131 | 195 | 0.2045 | 255 | 0.193 | 990 | 0.2125 |
| 0.5034 | 60 | 0.5044 | 95 | 0.5106 | 220 | 0.5182 | 680 | 0.5345 | |
| 0.9093 | 80 | 0.8913 | 225 | 0.9133 | 420 | 0.9149 | 815 | 0.9186 | |
| M7 | 0.5858 | 90 | 0.6891 | 150 | 0.6896 | 390 | 0.7235 | 995 | 0.7208 |
| 0.7934 | 35 | 0.837 | 120 | 0.9333 | 265 | 0.9667 | 1140 | 0.9297 | |
| 0.8803 | 85 | 0.8357 | 190 | 0.881 | 385 | 0.8973 | 1030 | 0.9289 | |
6. An application
The data under study refers to the daily mean flow discharge rate values () from 1 October, 1946 to 30 April, 2012 (‘SNIRH: Sistema Nacional de Informação dos Recursos Hídricos’). After some previous studies the stationarity of the data can be assumed from November until April (n = 11947).
Figure 11 illustrates the effect of considering different thresholds, when the block length was fixed as , for defining the clusters of exceedances, plotting a subset of the dataset available while Figure 12 displays the obtention of clusters, applying procedure (14) and considering three blocks, for the same subset used in Figure 11.
Figure 11.

Daily mean flow discharge rate values () from 1 January 1947 to 30 March 1947 from hydrometric station at Fragas da Torre.
Figure 12.
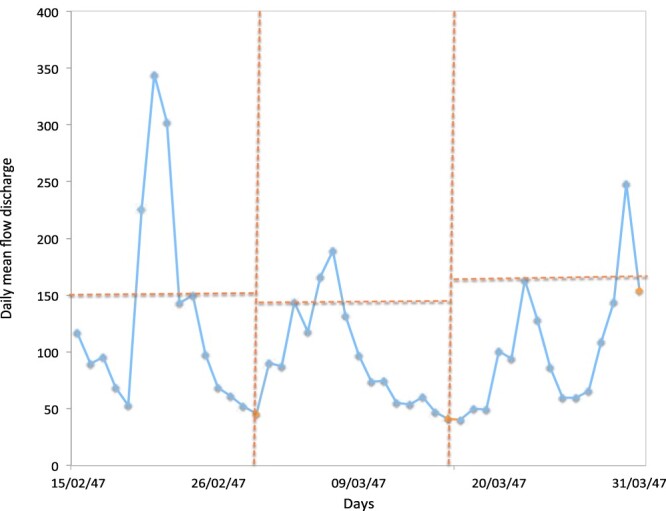
Daily mean flow discharge rate values () from 1 January 1947 to 30 March 1947 from hydrometric station at Fragas da Torre.
We also checked the proportion of the anti- events in our data and we verify that satisfies condition , see Figure 13.
Figure 13.
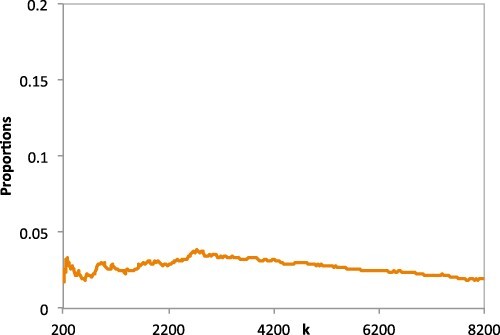
The observed proportions of for the daily mean flow discharge rate values with .
Figure 14 presents sample paths for the block-method EI- estimates. The difficulties of choosing the block size, , as well as of choosing the adequate level k, are clear on the left plot of this figure.
Figure 14.

Estimates of plotted against k () (left) and estimates of plotted against block length (right) with the choice of for the daily mean flow discharge rate values.
The right plot of Figure 14 presents the application of estimator (11). The application of the stability algorithm led to a block length and an EI-estimate equal to 0.9231.
7. A few comments
The extremal index estimation is still an issue that needs some more research. Although some estimators have been recently proposed, the problem of choosing the threshold and/or the block or run length is not completely solved.
With the proposed estimator, the problem of the threshold choice is solved and here was proposed to consider a stability criterion for the choice of the block size and the corresponding estimate.
This is a preliminary approach for trying to consider a more reliable extremal index estimation procedure.
Acknowledgements
The authors are grateful to the Special Issue Editor and Referees for their careful reviews and helpful suggestions, which have highly improved this version of the article.
Funding Statement
This work has been supported by National Funds through FCT Fundação para a Ciência e a Tecnologia, Portugal, through the projects UID/MAT/00006/2019 (CEA/UL), UID/MAT/00297/2019 and UIDB/00297/2020.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- 1.Alpuim M.T., An extremal Markovian sequence, J. Appl. Probab. 26 (1989), pp. 219–232. doi: 10.2307/3214030 [DOI] [Google Scholar]
- 2.Beirlant J., Goegebeur Y., Segers J., and Teugels J.L., Statistics of Extremes. Theory and Applications, 1st ed., John Wiley and Sons, England, 2004. [Google Scholar]
- 3.Berghaus B. and Bucher A., Weak convergence of a pseudo maximum likelihood estimator for the extremal index, Ann. Stat. 46 (2018), pp. 2307–2335. doi: 10.1214/17-AOS1621 [DOI] [Google Scholar]
- 4.Caeiro F. and Gomes M.I., Threshold selection in extreme value analysis, in Extreme Value Modeling and Risk Analysis: Methods and Applications, Dipak Dey and Jun Yan, eds., Chapman-Hall/CRC, Boca Raton, 2015, pp. 69–87.
- 5.Canto e Castro L., Estudo de um método de estimação do indice extremal, I Congresso Ibero-Americano de Estadística e Investigación Operativa, Salamandra,1992.
- 6.Chernick M.R., Hsing J.T., and McCormick W.P., Calculating the extremal index for a class of stationary sequences, Adv. Appl. Probab. 23 (1991), pp. 835–850. doi: 10.2307/1427679 [DOI] [Google Scholar]
- 7.Davis R.A. and Resnick S.I., Basic properties and prediction of Max-ARMA processes, Adv. Appl. Probab. 21 (1989), pp. 781–803. doi: 10.2307/1427767 [DOI] [Google Scholar]
- 8.Díaz-Delgado R., Lloret F., and Pons X., Spatial patterns of fire occurrence in Catalonia, NE, Spain, Landscape Ecol. 19 (2004), pp. 731–745. doi: 10.1007/s10980-005-0183-1 [DOI] [Google Scholar]
- 9.Drees H., Bias correction for estimators of the extremal index, preprint (2011), submitted for publication. Available at https://arxiv.org/abs/1107.0935.
- 10.Drees H., Extreme quantile estimation for dependent data with applications to finance, Bernoulli 9 (2003), pp. 617–657. doi: 10.3150/bj/1066223272 [DOI] [Google Scholar]
- 11.Ferreira M., Heuristic tools for the estimation of the extremal index: A comparison of methods, REVSTAT – Stat. J. 16 (2018), pp. 115–136. [Google Scholar]
- 12.Ferro C.A.T. and Segers J., Inference for clusters of extreme values, J. R. Stat. Soc. Ser. B 65 (2003), pp. 545–556. doi: 10.1111/1467-9868.00401 [DOI] [Google Scholar]
- 13.Hsing J.T., Extremal index estimation for a weakly dependent stationary sequence, Ann. Stat. 21 (1993), pp. 2043–2071. doi: 10.1214/aos/1176349409 [DOI] [Google Scholar]
- 14.Hsing J.T., Hüsler J., and Leadbetter M.R., On the exceedance point process for a stationary sequence, Probab. Theory Relat. Fields 78 (1988), pp. 97–112. doi: 10.1007/BF00718038 [DOI] [Google Scholar]
- 15.Laurini F. and Tawn J.A., New estimators for the extremal index and other cluster characteristics, Extremes 6 (2003), pp. 189–211. doi: 10.1023/B:EXTR.0000031179.49454.90 [DOI] [Google Scholar]
- 16.Lavanda B. and Cipollone E., Extreme value statistics and thermodynamics of earthquakes: Aftershock sequences, Ann. Geofis. 43 (2000), pp. 967–982. [Google Scholar]
- 17.Leadbetter M.R. and Nandagopalan L., On exceedance point process for stationary sequences under mild oscillation restrictions, in Extreme Value Theory: Proceedings, Lecture Notes in Statistics 52, Oberwolfach, J. Hüsler and R. D. Reiss, eds., Springer-Verlag, Berlim, 1989, pp. 69–80.
- 18.Leadbetter M.R., Lindgren G., and Rootzén H., Extremes and Related Properties of Random Sequences and Series, Springer-Verlag, New York, 1983. [Google Scholar]
- 19.Martins A.P. and Sebastião J.R., Methods for estimating the upcrossings index: Improvements and comparison, Stat. Papers 60 (2017), pp. 1317–1347. doi: 10.1007/s00362-017-0876-x [DOI] [Google Scholar]
- 20.Neves M.M., Gomes M.I., Figueiredo F., and Gomes D.P., Modelling extreme events: Sample fraction adaptive choice in parameter estimation, J. Stat. Theory Practice 9 (2015), pp. 184–199. doi: 10.1080/15598608.2014.890984 [DOI] [Google Scholar]
- 21.Northrop P.J., An efficient semiparametric maxima estimator of the extremal index, Extremes 18 (2005), pp. 585–603. doi: 10.1007/s10687-015-0221-5 [DOI] [Google Scholar]
- 22.Reiss R.-D. and Thomas M., Statistical Analysis of Extreme Values: With Applications to Insurance, Finance, Hydrology and Other Fields, 3rd ed., Birkhäuser Verlag, Basel, 2007. [Google Scholar]
- 23.Robert C.Y., Segers J., and Ferro C.A.T., A sliding blocks estimator for the extremal index, E. J. Stat. 3 (2009), pp. 993–1020. doi: 10.1214/08-EJS345 [DOI] [Google Scholar]
- 24.Schoenberg F.P., Peng R., Huang Z., and Rundel P., Detection of nonlinearities in the dependence of burn area on fuel age and climatic variables, Int. J. Wildland Fire 12 (2003), pp. 1–10. doi: 10.1071/WF02053 [DOI] [Google Scholar]
- 25.Smith R.L., The extremal index for a markov chain, J. Appl. Probab. 29 (1992), pp. 37–45. doi: 10.2307/3214789 [DOI] [Google Scholar]
- 26.Smith R. and Weissman I., Estimating the extremal index, J. R. Stat. Soc. B 56 (1993), pp. 515–528. [Google Scholar]
- 27.Süveges M., Likelihood estimation of the extremal index, Extremes 10 (2007), pp. 41–55. doi: 10.1007/s10687-007-0034-2 [DOI] [Google Scholar]
- 28.Weissman I. and Novak S.Y., On blocks and runs estimators of the extremal index, J. Stat. Plann. Inf. 66 (1998), pp. 281–288. doi: 10.1016/S0378-3758(97)00095-5 [DOI] [Google Scholar]