
Figure 1:
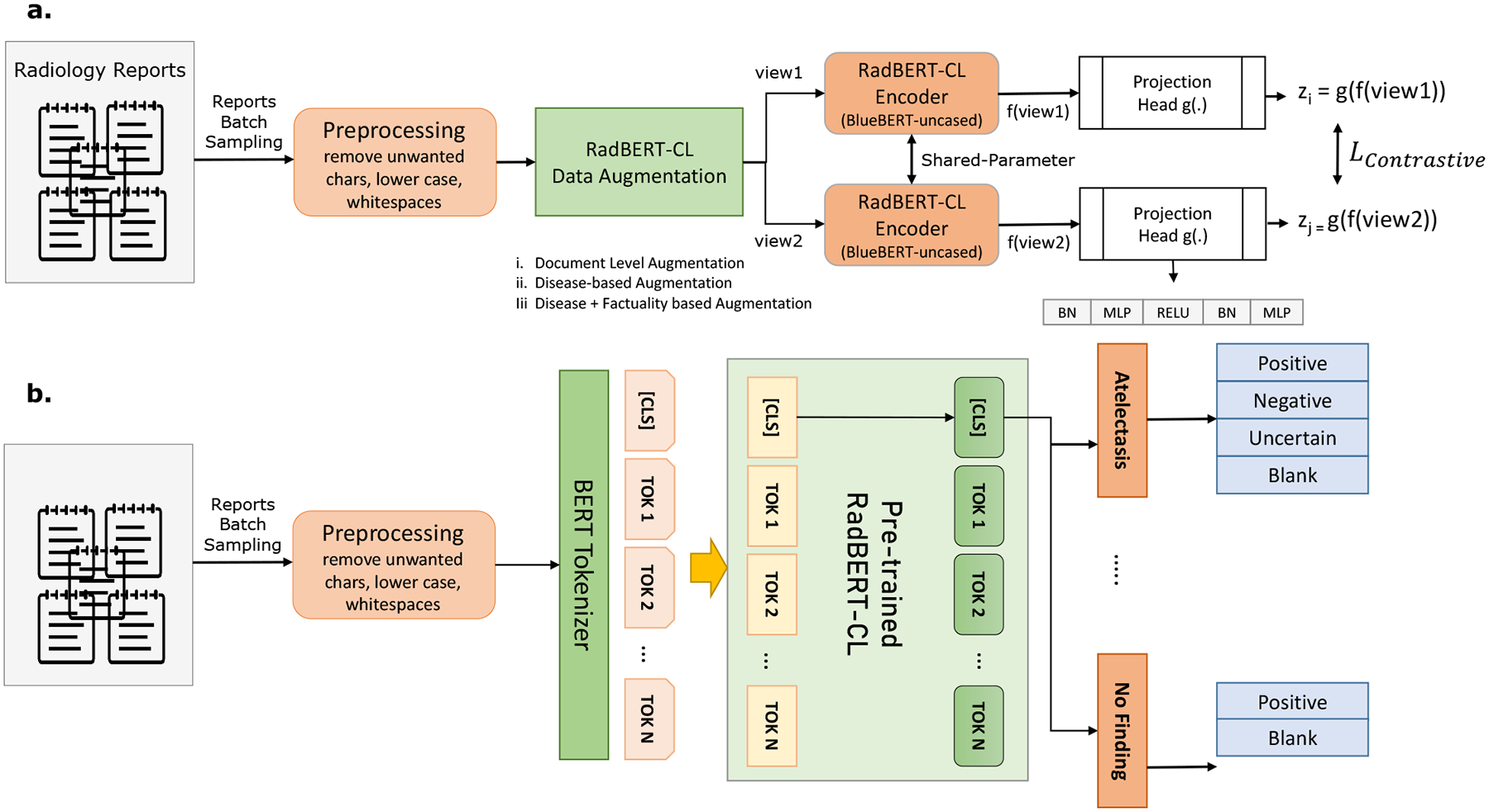
(a) Pre-training architecure of RadBERT-CL using contrastive learning. Two separate data augmentation views are generated using the augmentation techniques described in Section 3.2. Both views (query and key) are passed through RadBERT-CL, which is a transformer-based encoder f(.), and a projection head g(.). RadBERT-CL is trained to maximize agreement between the two augmented views using contrastive loss. (b) Fine-tuning Model architecture of RadBERT-CL. The model consists of 14 linear heads corresponding to 14 disease concepts. Among them, 13 linear heads can predict 4 outputs, while linear head corresponding to “No Finding” can predict 2 outputs.