
Figure 13:
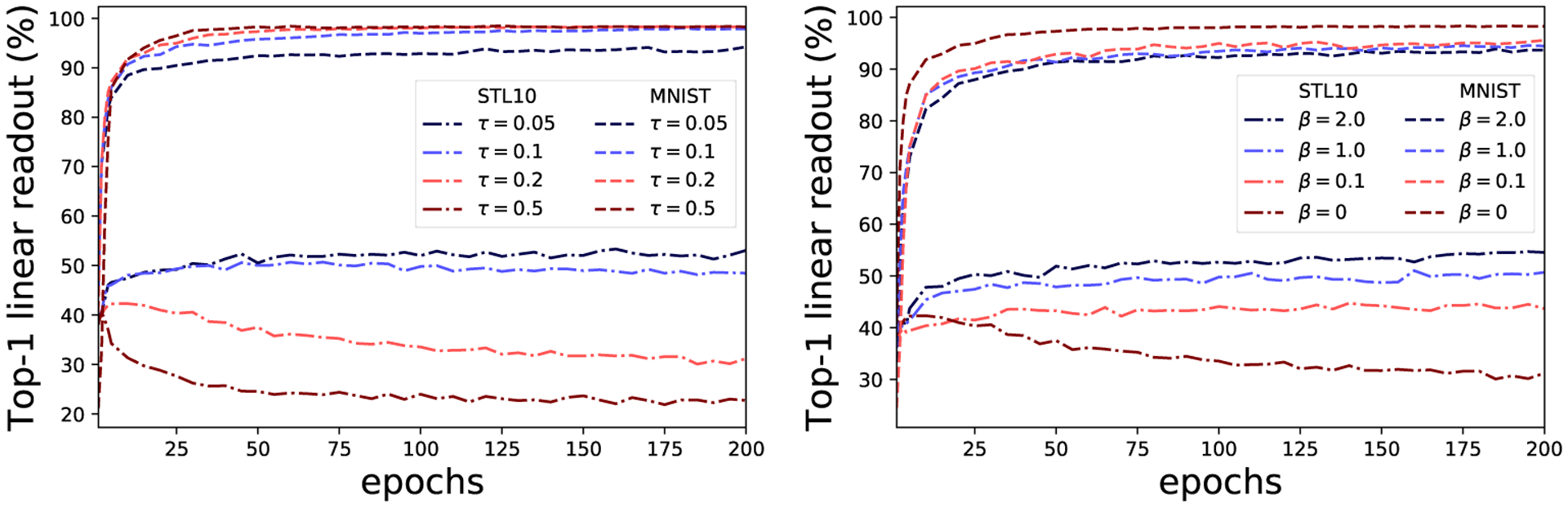
STL-digits dataset. Left: performance on STL10 and MNIST linear readout for different temperature τ values. Right: performance on STL10 and MNIST linear readout for different hardness concentration β values [40]. In both cases harder instance discrimination (smaller τ, bigger β) improves STL10 performance at the expense of MNIST. When instance discrimination is too easy (big τ, small β) STL10 features are suppressed: achieving worse linear readout after training than at initialization.