
Fig. 1.
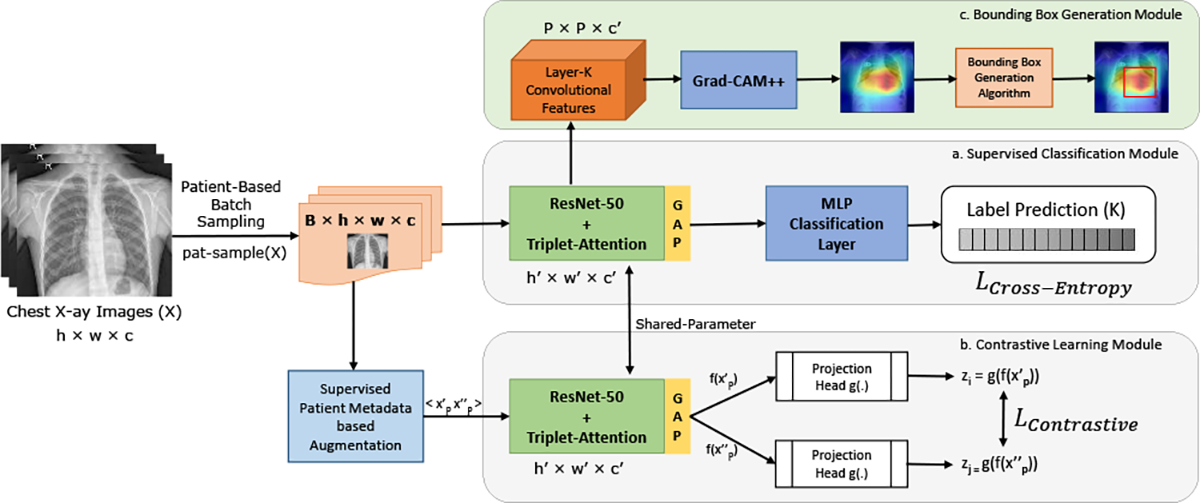
Model Overview. The input images are sampled in batches with a constraint that no two images in a batch are from the same patient. Learning is performed using a shared encoder (Resent-50) with triplet attention and joint loss from the supervised classification and contrastive learning module.