
Figure 1.
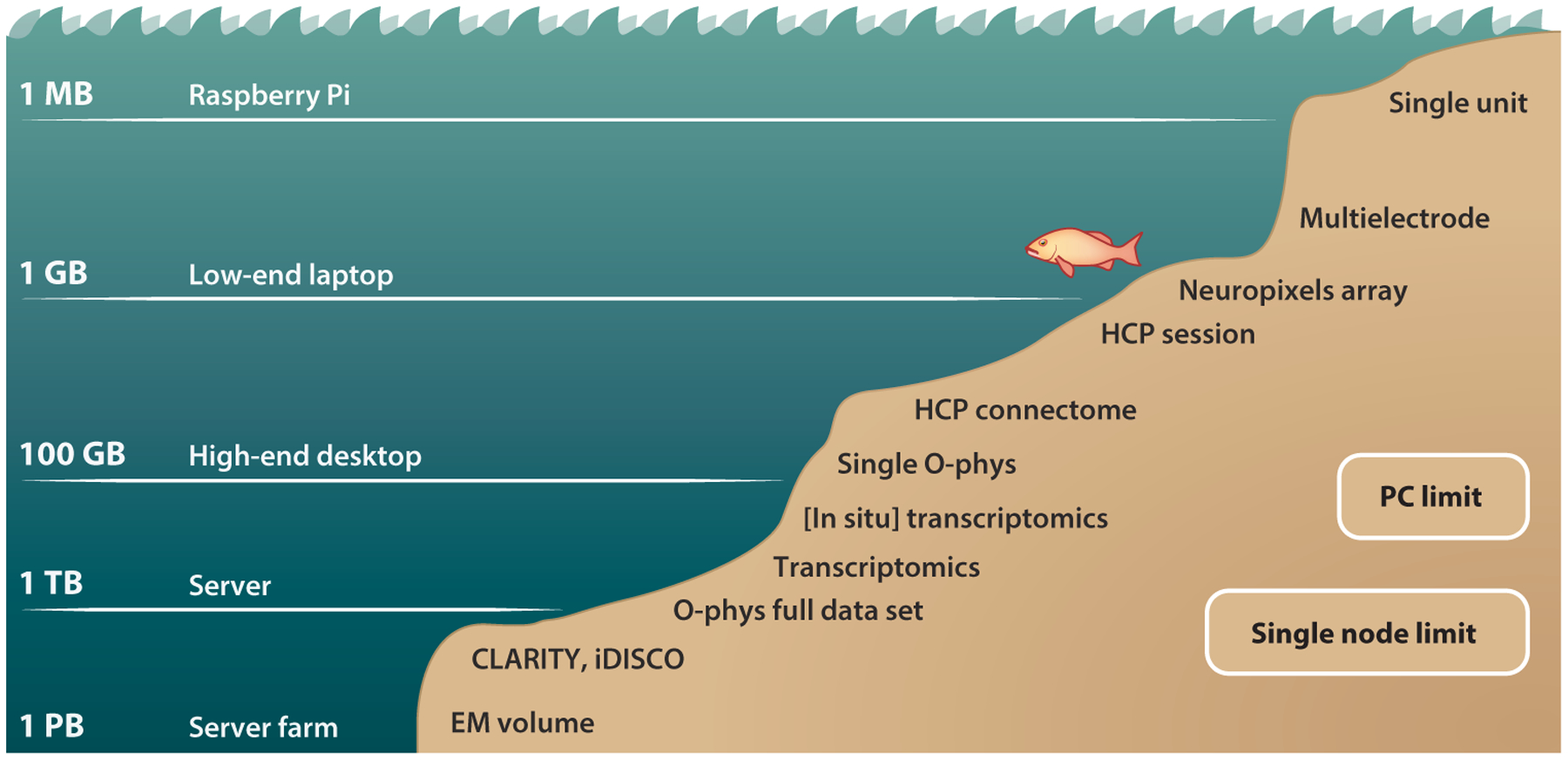
The big data deluge puts different pressure on different applications. At greater data sizes, more powerful systems are needed to operate in these ever–more challenging regimes. Most neuroscience data sets currently still reside at sizes computationally tractable on a single PC or, at worst, a single HPC node. All these modalities, however, are seeing a steady rise in data sizes. The methods that will enable neuroscientists to make use of these ever-richer data sets must be developed now.