
Figure 3:
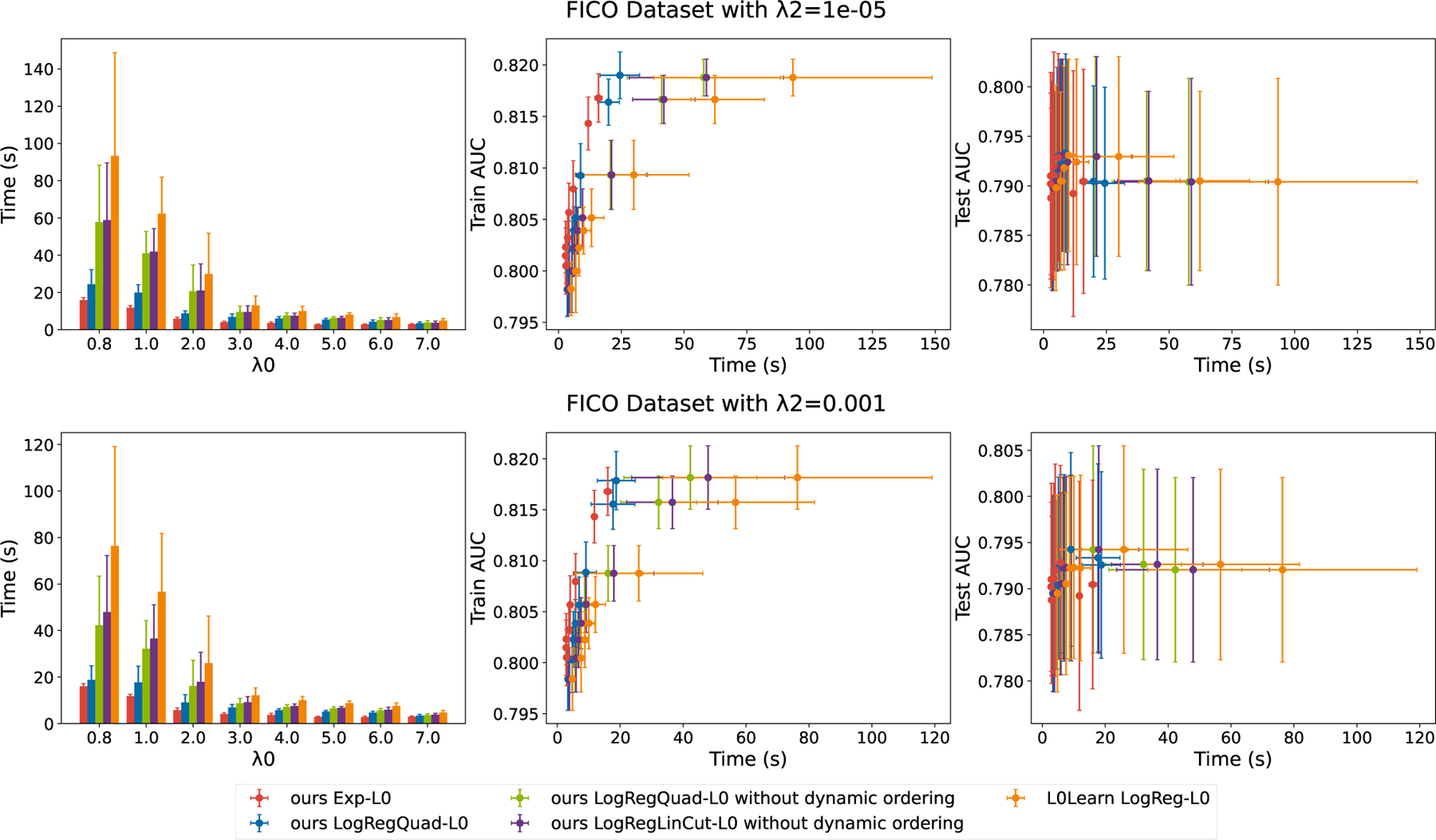
Computational times of different methods. “Exp” stands for exponential loss, “LogReg” stands for logistic loss, “LinCut” stands for linear cuts, and “Quad” stands for quadratic cuts. Note that there is no ℓ2 penalty for the exponential loss. Our Exp-L0 method is generally about 4 times faster than L0Learn. Note that the AUC axes indicate practically similar performance for these particular methods; the training time is what differentiates the methods. Additionally, when the ℓ2 penalty increases from λ2 = 1e − 05 to λ2 = 0.001, there is a computational speedup from using the linear cut to the quadratic cut due to the tighter lower bound.