
Figure 2.
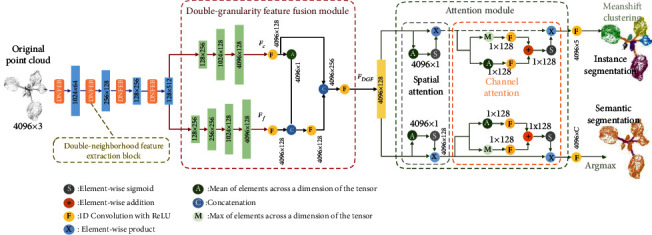
The architecture of PSegNet. The network is mainly composed of three parts. The front part has a typical encoder-like structure in deep learning. Four consecutive Double-Neighborhood Feature Extraction Blocks are applied in the front part computation, and the feature space is downsampled before each DNFEB to condense the features, respectively. The middle part is the Double-Granularity Feature Fusion Module, which fuses the outputs of two decoders with different feature granularity to obtain the mixed feature FDGF. In the third part of PSegNet, the features flow into two directions that, respectively, correspond to two tasks—instance segmentation and semantic segmentation. Spatial attention and channel attention mechanisms are sequentially applied on each feature flow.