
Figure 6. Identification of mental states shows poor predictability.
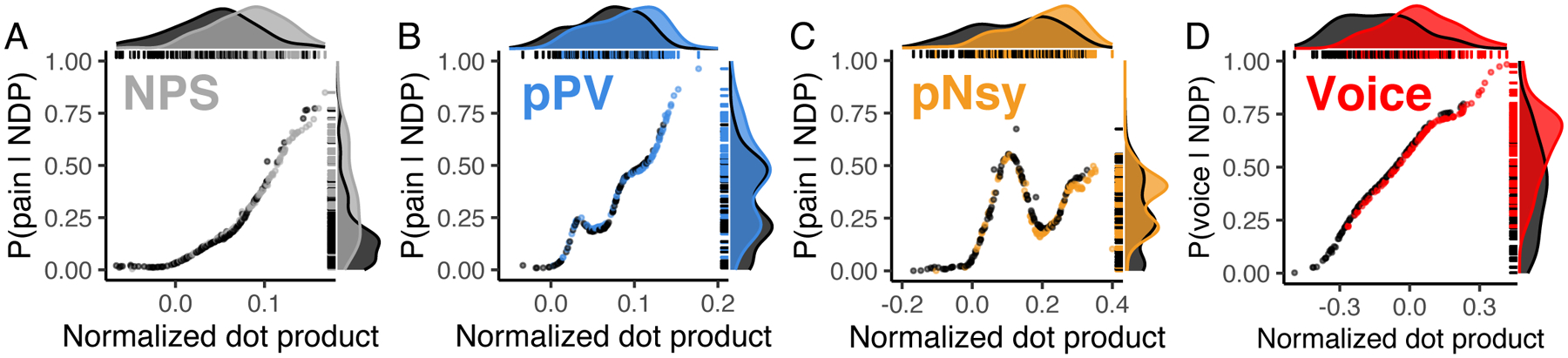
Three pain decoders (NPS, pPV, and pNsy in A–C) and a voice decoder (D) were used to test identification for mental states. x-axes are the normalized dot products between decoder and decodee, while y-axes are the posterior probability of being in pain (A–C) or listening to voices (D). Distributions of normalized dot products and posterior probabilities include both the decodee (light grey & colors) and comparator (dark grey) tasks. (A–C) Normalized dot products of the pain condition span the entire distribution of comparator normalized dot products, and as a result, pain is not adequately isolated from the comparator conditions. Quantitatively, this is evidenced by the strong decodee-comparator overlap for (A) NPS (overlap (95%CI) = 68% (59–82)), (B) pPV (79% (73–90)), and (C) pNsy (73% (66–84)). This is reflected in the Bayesian model, which shows similar probabilities of being in pain for both pain and pain-free conditions (each dot/line). To this end, all three decoders perform similarly, and cannot unequivocally identify pain, as indicated by their sensitivity/specificity (threshold from Youden’s J statistic, chosen in-sample) of (NPS, A) 0.64/0.74, (pPV, B) 0.6/0.64, and (pNsy, C) 0.54/0.76. (D) In contrast to pain, a contrast map decoder for identifying when a participant is listening to human voices separates more clearly the normalized dot products of the decodee (red) from comparator (dark grey), but still performs poorly (overlap = 54% (46–66)). This separation is reflected in the Bayesian model, which shows high probabilities when individuals are listening to human voices and lower probabilities when they are not. Using a threshold determined by Youden’s J statistic (chosen in-sample), the voice decoder has a sensitivity/specificity of 0.77/0.64. In (A), (B), (C) the dataset used were not used in the training of the decoders (NPS, pPV, pNsy); tests are all out of sample. In (D), we split the dataset into a training set (107 subjects) and a testing set (106 subjects).