
Figure 4:
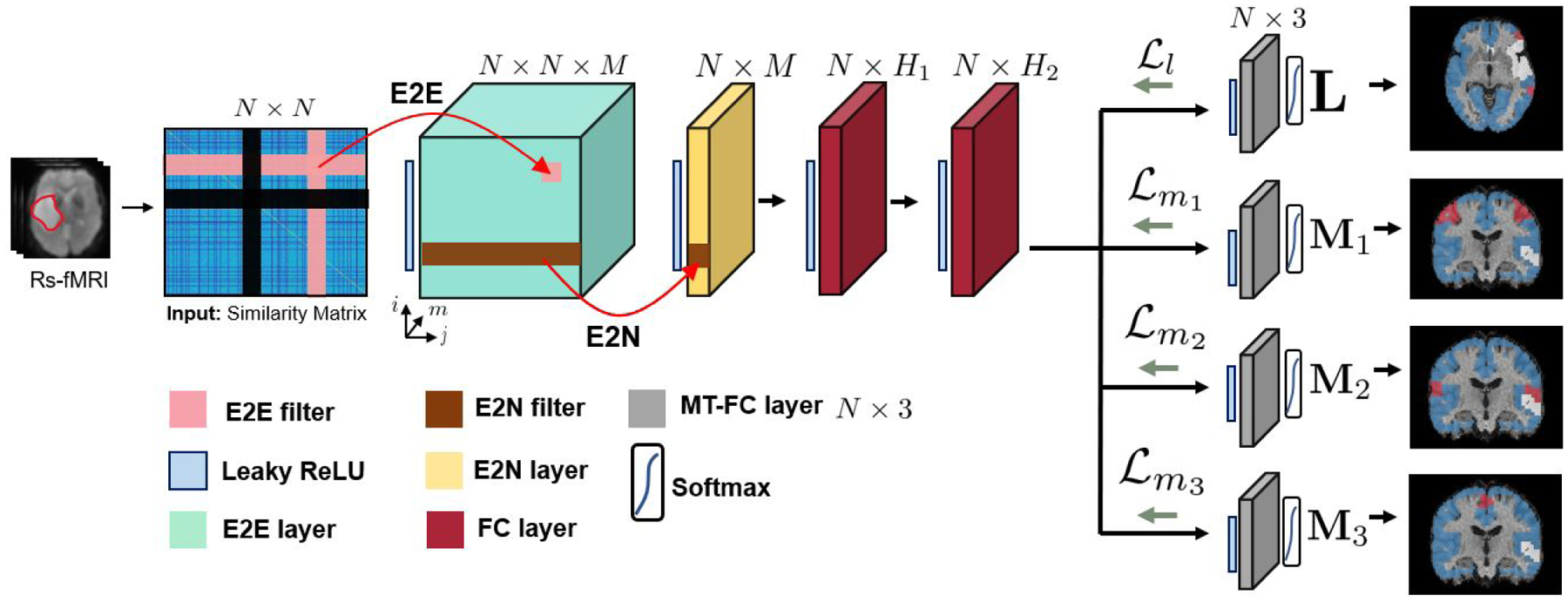
The overall workflow of our model. N is number of nodes, M is number of convolutional feature maps, H1 is number of neurons in the first FC layer and H2 is the number of neurons in the second FC layer. Our model uses specialized E2E and E2N filters as well as employs multi-task learning on a variety of available t-fMRI paradigms. Each grey module represents a separate 3-class segmentation task. The variables L, M1, M2 and M3 represent the language, finger, tongue, and foot networks respectively, as shown by the segmentation maps where red, blue, and white refer to the eloquent, neither, and tumor classes respectively.