
FIGURE 1.
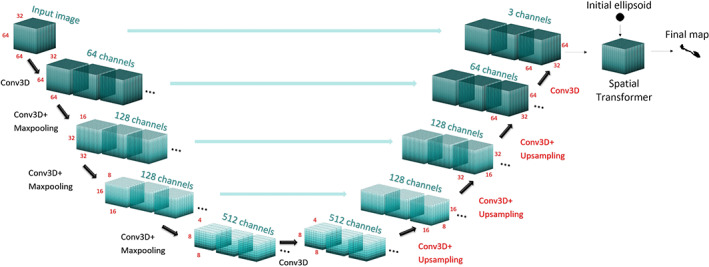
Structure of the u‐net: black layers were kept fixed for the transfer learning, while red layers were trained. Each layer uses a ReLu activation function (Nicola K. Dinsdale et al., 2019). The final section of the network, the spatial transformer, is not shown but only has fixed parameters