
Figure 2.
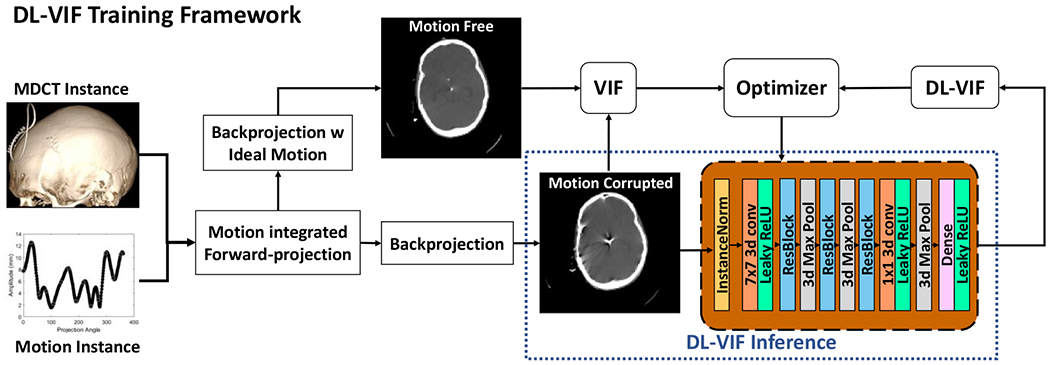
Training strategy for the DL-VIF deep CNN. Motion-free MDCT datasets were used as base instances for the generation of motion corrupted CBCT data. The motion-corrupted data were reconstructed without any motion compensation and with motion compensation using the same motion pattern used to generate the motion corrupted dataset, providing a ground truth for ideal motion compensation. Conventional VIF values were computed for each motion-corrupted volume, using the ideal compensation as reference, to serve as training labels for DL-VIF training. Note that at inference time (see dashed box), only the motion corrupted image is needed, making DL-VIF a true reference-free metric.