
Figure 8.
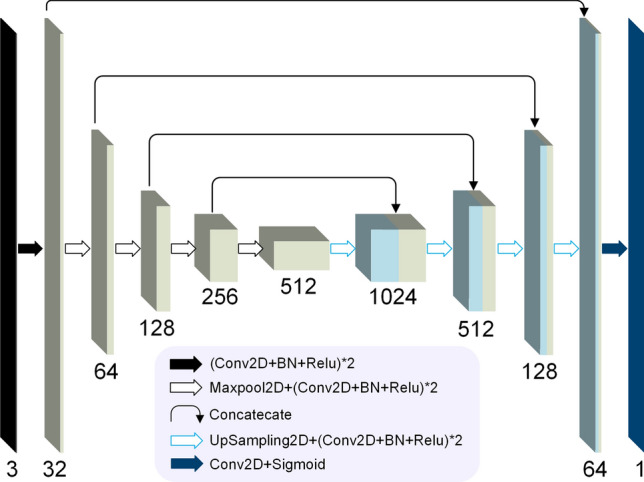
The architecture of our vessel segmentation model. It is an encoder–decoder convolutional neural network. Model input is a 1024 1024 color retinal image and model output is single channel 1024 1024 vessel prediction image. Conv2D is 2D convolutonal layer with kernel size of (3,3). Padding parameter of Conv2D is set to “same” in order to output the same dimension of the input. BN refers to BatchNormalization layer. Output channels of encoding blocks are 32, 64, 128, 256 and 512 respectively while output channels of decoding blocks are 512, 256, 128, 64 and 32.