
FIGURE 1.
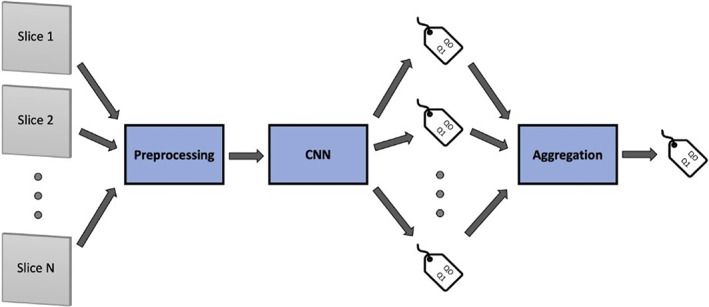
Graphical representation of the analysis pipeline. Individual slices from a given sequence are preprocessed (including normalization and voxel resampling, and data augmentation) and subsequently fed to the CNN algorithm that assigns a classification label to every slice. Classification results for all slices from the same sequence are then aggregated by means of a majority vote aggregation function, so that a classification label is assigned to the entire acquired sequence.