
Figure 2.
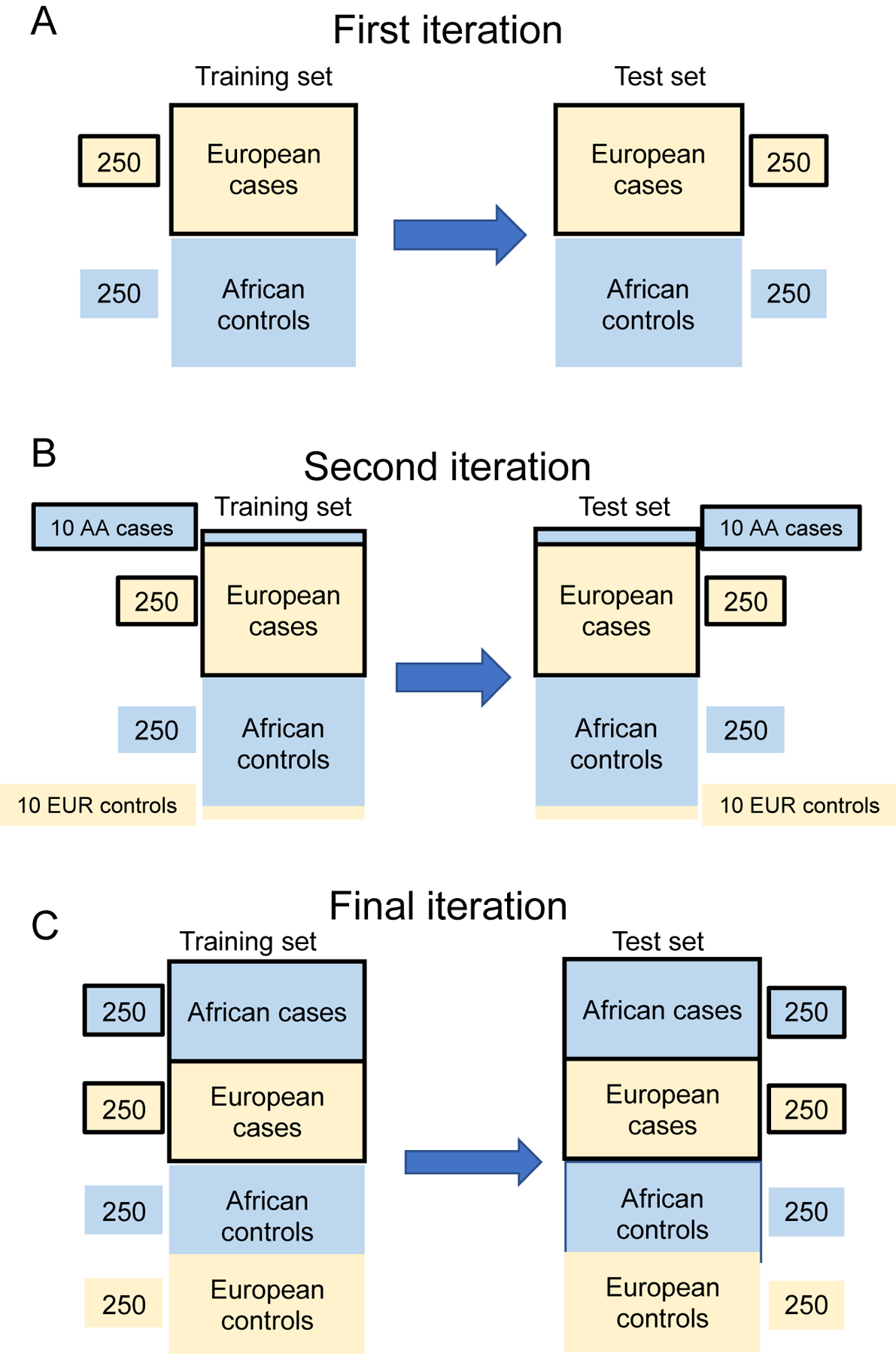
Learning curve procedure for all analyses. We had a complete and non-overlapping training and test set, each of 1000 subjects with 250 cases and controls of European and African descent. (A) For the first iteration we started with 250 subjects of European descent (tan) that were OUD cases, and 250 subjects of African descent (blue) that were controls. (B) At each iteration, we added 10 OUD individuals of African descent to the cases and 10 controls of European descent to the controls. We estimated the model in the training data and used it to predict OUD status in the non-overlapping test set. (C) By the final iteration, we had a training and test set that was balanced by major geographic ancestry and OUD status.