
Fig. 1.
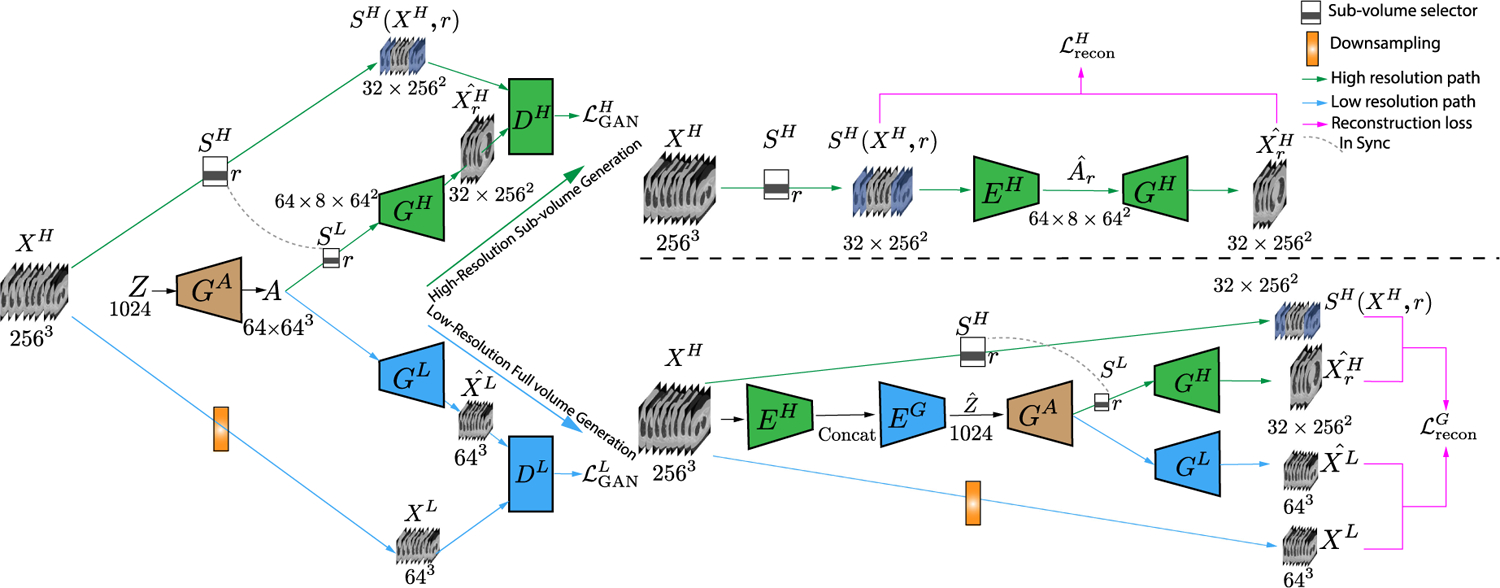
Left: The architecture of HA-GAN (encoder is hidden here to improve clarity). At the training time, instead of directly generating high-resolution full volume, our generator contains two branches for high-resolution sub-volume and low-resolution full volume generation, respectively. The two branches share the common block GA. A sub-volume selector is used to select a part of the intermediate feature for the sub-volume generation. Right: The schematic of the hierarchical encoder trained with two reconstruction losses, one on the high-resolution sub-volume level (upper right) and another one on the low-resolution full volume level (lower right). The meanings of the notations used can be found in Table I. The model adopts 3D architecture with details presented in Supplementary Material.