

Abstract
The asymptotic posterior normality (APN) of the latent variable vector in an item response theory (IRT) model is a crucial argument in IRT modeling approaches. In case of a single latent trait and under general assumptions, Chang and Stout (Psychometrika, 58(1):37–52, 1993) proved the APN for a broad class of latent trait models for binary items. Under the same setup, they also showed the consistency of the latent trait’s maximum likelihood estimator (MLE). Since then, several modeling approaches have been developed that consider multivariate latent traits and assume their APN, a conjecture which has not been proved so far. We fill this theoretical gap by extending the results of Chang and Stout for multivariate latent traits. Further, we discuss the existence and consistency of MLEs, maximum a-posteriori and expected a-posteriori estimators for the latent traits under the same broad class of latent trait models.
Supplementary Information
The online version contains supplementary material available at 10.1007/s11336-021-09838-2.
Keywords: multidimensional item response theory, empirical Bayes, posterior distribution, ability estimation, consistency, normal approximation, Bernstein–von Mises theorem
Introduction
In the context of item response theory (IRT) methodology, statistical inference for the examinee’s ability relies often on the assumption that its posterior distribution given the test response is a normal distribution. As this is usually hard to justify and in contradiction to common models of the examinees abilities distribution in the population, it can assumed to be, for a long test, well approximated by a normal distribution. This assumption of asymptotic posterior normality (APN) is part of the famous Dutch identity conjecture of Holland (1990), who mentioned then that he was not aware of a thorough discussion of APN of latent variables and this would be an interesting area for future research. Shortly after, Chang and Stout (1993) proved the APN for univariate latent traits (LTs), mentioning that APN for multivariate LTs can be proved, but without providing further details or discussing the associated regularity conditions required.
As far as we know, APN of multivariate LTs has not been proved so far for IRT models of a general context, although posterior normality or APN is assumed quite often under various IRT setups (e.g., Anderson & Vermunt, 2000; Anderson & Yu, 2017; Anderson et al., 2007; Hessen, 2012; Li, 2010; Paek, 2016). For example, Pelle et al. (2016) assume posterior multivariate normality for the latent variable vector of a log-linear multidimensional Rasch model for capture–recapture analysis of registration data.
Sometimes the APN-assumption is justified by the APN in a Bayesian framework (pointing to the “Bernstein–von Mises Theorem”) without however proceeding to further details (e.g., the computationally efficient adaptive quadrature methods for high-dimensional item factor analysis (Schilling & Bock, 2005) and for generalized linear mixed models (Rabe-Hesketh et al., 2002) are based on the APN assumption).
In this work, we study the APN for multivariate latent trait models, focusing on models for dichotomous items and targeting at conditions that are tailored to IRT models and thus simpler to verify. APN of LTs, univariate or multivariate, is related to Bayesian asymptotics. In the light of this connection, we deepen in the approach of Ghosal et al. (1995), who discussed asymptotic posterior distributions in a very general setup that includes the regular cases and some non-regular cases as well. They also proved a general result on the asymptotic equivalence of the Bayes and maximum likelihood estimators, a well-known result for the regular cases. In particular, we generalize the approach and results of Chang and Stout (1993), CS hereafter, linking them to the semiproper centering concept of Ghosal et al. (1995), GGS hereafter, and embedding them in their approach. We provide conditions for multivariate APN that correspond one to one to the conditions of CS for univariate LTs, which is the standard approach for IRT models, as alternatives to the conditions imposed in Ghosal et al. (1995). Even for the case of univariate LTs, the proposed approach could be an interesting alternative to that of CS, since it has the advantage of applying also to models with non-monotone item response functions, which is not the case in the CS setup. Furthermore, we discuss conditions under which the existence of the maximum likelihood estimators (MLEs) for latent variable vectors is ensured. The consistency of MLEs under mild conditions, which was indicated as an open issue by Sinharay (2015), follows as a natural consequence of the proof of the APN. Finally, we prove the consistency of maximum a-posteriori (MAP) and expected a-posteriori (EAP) estimators for multivariate LTs.
The paper is organized as follows. Basic notation and the adopted IRT framework is set in Sect. 2, while the CS-theory for a univariate LT is briefly reviewed in Sect. 3. The approach of Ghosal et al. (1995) is discussed and linked to the APN of LTs and the CS-results in Sect. 4. The CS-conditions are generalized for the multivariate case and commented in Sect. 5 while they are verified for characteristic examples in Sect. 6. The main result on APN for multivariate LTs and properties of the MLEs, MAPs and EAPs of LTs are provided in Sect. 7 and supported by a simulation study in Sect. 8. Finally, the results are summarized in Sect. 9. A brief version of the proofs of the results of Sect. 7 is given in “Appendix” while their extended version can be found in the web-appendix. For a preliminary version of these results, see also Chapter 3 in Kornely (2021).
Preliminaries
Consider a test consisting of d binary response variables , , with for the i-th item, where 1 (0) denotes a correct (incorrect) response, and defined over a probability space . Consider further the response vector , with superscript denoting the transpose of a vector. Thus, the manifest probability for a specific response pattern is given by . In an multidimensional IRT (MIRT) modeling framework, manifest probabilities are derived via conditioning on an absolutely continuous latent variable vector , defined over the same probability space as the binary items with probability density function (pdf) and cumulative distribution function (cdf) and , respectively. In particular, the conditional probability mass function (pmf) of is thus given by
| 1 |
with being known as the i-th item response function. In MIRT modeling, specific assumptions are usually imposed on the conditional distribution ; namely the assumption of local independence
| 2 |
and that of monotonicity for the item response functions , i.e., for
| 3 |
Note that assumption (3), which is required in the CS-approach, is relaxed in our setup. In the sequel, we denote by a sequence of Bernoulli random variables that fulfill (1) and (2) for all .
Due to assumption (2) and using (1), the manifest probabilities are derived through the following integral
| 4 |
Remark 1
For simplicity of notation, we use to denote the random latent variable vector as well as a realization of it. If not clear from the context, we write explicitly for a realization or for the random vector with values in . In the sequel, we abbreviate the term latent variable vector to latent vector.
The posterior density of , given an observed response , is then given by
| 5 |
where is the log-likelihood corresponding to (1), given by
| 6 |
with denoting the item logit, i.e.,
| 7 |
and the function being defined as , .
Let denote the MLE of the true value of the latent vector , based on a test realization . Furthermore, the Fisher information matrix of the test at point is given by
| 8 |
where is the i-th item information matrix
This work studies the APN of for , based on a sequence of random variables , as defined above. Particularly, we shall prove that, under certain conditions, (8) is invertible at and is approximately normal distributed, , for a realization of . This enables the approximation of probabilities of the type
| 9 |
where denotes the Borel--algebra of . Practically speaking, a set B can be any countable union or intersection of q-dimensional real cubes.
Next, we define some functions that are useful for the sequel derivations. For all , set with
| 10 |
where , , are defined as
| 11 |
Note that for given d and , (10) is the likelihood ratio of the likelihoods for and . Furthermore,
| 12 |
while is the Kullback–Leibler divergence between the conditional distributions of given and , respectively. A basic approach for deriving APN results relies on a quadratic approximation of (12).
Review of APN for Univariate Latent Traits
In case of a single latent variable (, ), Chang and Stout (1993) proved the APN of the univariate latent trait, adopting the approach of Walker (1969) for binary , , that are independent but not identically distributed (inid). We briefly review their results, so that we can extend in the sequel their approach to the multivariate case ().
Additional to the general assumptions (2) and (3), they also introduced the following regularity conditions.
-
[i]Let , where is a bounded or unbounded interval.
-
[ii]Let the prior density be continuous and positive at the true value .
-
[i]
is twice continuously differentiable with the first two derivatives being uniformly bounded in absolute value with respect to both and i in some closed interval around .
- For every fixed , , there is a such that
and .13 - If restricted to , the following sets of functions are uniformly bounded:
- Asymptotically, the average information at is bounded away from 0, i.e.,
Remark 2
With respect to the prior of , additional to (CS1[ii]), Chang and Stout (1993) implicitly assumed its properness, which was stated explicitly in the earlier associated technical report (Chang & Stout, 1991, p. 15).
Remark 3
Reasonable models for applications do not depend on a specific compact interval in since usually is unknown. For this, also the conditions depending on should be satisfied for almost all and for almost each there should be some (arbitrary small) interval . In the usual models these conditions are satisfied.
Chang and Stout (1993) argued convincingly that conditions (CS1)–(CS5) are realistic and non-restrictive in practice for commonly used IRT models of well-designed tests. They particularly commented condition (CS3) and (13), which plays an important role in the proof of their main theorem. (CS3) is required when the item responses are independent but not identically distributed. If they are iid, (CS3) is automatically satisfied, which however is not necessarily the case in IRT models. Their main results are expressed in the three theorems given below.
Theorem 1
(Chang & Stout, 1993, Theorem 1) Suppose that conditions (CS1) through (CS5) hold for a fixed . Let be the MLE of and . Then, for , the posterior probability of approaches the probability of in for , that means
Theorem 2
(Chang & Stout, 1993, Theorem 2) Suppose that conditions (CS1) through (CS5) hold for fixed and let and be defined as in Theorem 1. Then, for , the posterior probability approaches A -almost surely, as .
Theorem 3
(Chang & Stout, 1993, Theorem 3) Assume , a finite interval. Suppose that conditions (CS1) through (CS5) hold for all and let and be defined as in Theorem 1. Then, for , the posterior probability approaches A in manifest probability , as .
The result of Theorem 3 does not depend on the true value and is thus of special practical interest for estimation and prediction purposes. As Chang and Stout (1993) comment, Theorems 1 and 3 treat sampling from a fixed ability sub-population and from the whole population, respectively. An important by-product of the proof of the APN of latent variables distributions was the establishment of the weak and strong consistency of the MLE of under milder conditions than Lord (1983).
Due to the theorems above, the following approximation for a large d and any observed response pattern , i.e., the construction of asymptotic credible intervals, is justified
| 14 |
for , where is the MLE of based on the sample , and denotes the cdf of . Approximation (14) is of special practical importance in the context of long tests where the exact computation of posterior probabilities for latent variables is commonly intractable. Furthermore, (14) allows the approximation of the posterior if the exact distribution of is unavailable or uncertain.
Finally, Chang and Stout (1993) noted that their theory, under suitable regularity conditions, can be extended to prove the APN for latent vectors of general multidimensional IRT models, without however commenting further the proving procedure or the regularity conditions required. Next, we discuss the asymptotic posterior distribution of multivariate latent traits in the context of MIRT.
APN for Multivariate Latent Traits
The theory of APN of the latent variables is naturally linked to Bayesian procedures and results on the convergence of posterior distributions. In particular, interesting and inspiring is the fundamental contribution by GGS (Ghosal et al., 1995), who consider asymptotic multivariate posterior distributions (not necessarily normal) in a very general and flexible framework discussing different types of convergence, relying on earlier works by Ghosh et al. (1994) and Ibragimov and Has’minskii (1981), denoted as IH hereafter. In particular, they studied posterior convergence of suitably centered and normalized posteriors. Their results provide a very general framework, which can be adopted for the APN in the IRT setup. Next, we adjust the GGS approach for MIRT models and discuss their conditions, embedding the CS approach in the GGS framework.
Following Ghosal et al. (1995, Definition 2), we distinguish two types of APN and link them to the statistic used for the centering of the posterior distribution of the latent vector.
Definition 1
Let be a q-variate standard normal distributed random vector. A -valued statistic is called a proper centering (with limiting normal distribution) if
| 15 |
A statistic is called semiproper centering (with limiting normal distribution) if, for all ,
| 16 |
A statistic is called compatible (with the posterior), if
as a random element in , converges in distribution for , where denotes the density of the posterior distribution of and stands for the space of all q-variate Lebesgue-integrable real functions on .
Proper and semiproper centering correspond to uniform and pointwise convergence of the posterior of the standardized latent vector , respectively. Hence, proper centering is a stronger property than semiproper centering, and is consequently expected to require stronger assumptions.
Under this view, one can easily recognize that Theorem 1 of Chang and Stout (1993) is the semiproper centering of the MLE, since it can be formulated as
for , and being the MLE of based on . Thus, for the extension of the CS-theory for multivariate LTs, we focus on semiproper centering.
The asymptotic results of GGS adjusted in our setup, primarily focus on the convergence of the posterior distribution of the standardized latent vector
| 17 |
with . We need the likelihood ratio (10) expressed in terms of , which is denoted by
| 18 |
In our setup, for binary response variables , , and log-likelihoods given by (6), the likelihood ratio takes the form
with the item logits provided in (7).
The primary conditions of GGS for APN are given as follows:
- For some , and holds
for all , satisfying , , where is the Euclidean norm. - For all holds
where is a sequence of real-valued functions on satisfying the following: (a) for a fixed , ; (b) for any , - For all and , the vector of the likelihood-ratios, defined in (18), satisfies
for , where denotes convergence in distribution and , , where .
Under these conditions, Ghosal et al. (1995) provided the following general result. Notice that they discussed a far more general framework, allowing further distributions for the response variable and considering cases for which the posterior may converge to another distribution than a normal. We refer to GGS for further details regarding these cases.
Theorem 4
(Ghosal et al., 1995, Theorem 1) Assume that conditions (GGS1) through (GGS3) hold. If either a proper centering or a semiproper compatible centering sequence exists, then it exists a random vector , such that (a) for and (b) for almost all , is nonrandom, where Z is as defined in condition (GGS3). Conversely, if (b) holds for a random vector , then any Bayes estimator (with respect to a prior and loss considered by Ghosal et al. (1995)) is a compatible proper centering.
Applying Theorem 4 for an appropriate Bayes estimator for , the APN of an MIRT model under conditions (GGS1) to (GGS3) is derived. The extension of Theorem 4 for an MLE, i.e., for , is based on its asymptotic equivalence to an arbitrary Bayes estimator, which has been proved by Ghosal et al. (1995, cf. Corollary 1) under (GGS2)–(GGS3) and the following strengthened form of (GGS1):
- For some , and holds
for all , satisfying , .
Remark 4
Alternatively to the GGS conditions discussed above, one could consider the conditions of Ibragimov & Has’minskii (1981, Section III.4) for general regular models for independent non-necessarily identical distributed (inid) random variables. They proved that these conditions are sufficient for the set of conditions N1–N4 of IH, Section III.1, where N1 is the uniform asymptotic normality and corresponds to (GGS3), while N3 and N4 correspond to (GGS1) and (GGS2), respectively.
Regularity Conditions for Asymptotic Properties of Latent Vectors
Aiming to generalize the CS approach, we provide conditions for APN of (multivariate) LTs that correspond one to one to the conditions of CS for univariate LTs, which is the standard approach for IRT models, as alternatives to the conditions imposed in Ghosal et al. (1995). Throughout, we assume that , i.e., are Bernoulli random variables fulfilling (1) and (2), and that the true latent vector lies in the interior of the parameter space, i.e., , where denotes the boundary of . The asymptotic results of Sect. 7 rely on the following regularity conditions.
-
[i]The set is closed, convex and has non-empty interior.
-
[ii]The prior density of is proper and continuous at with .
-
[i]
- is thrice continuously differentiable, . If restricted to a compact subset , all and are uniformly bounded for all , . Moreover, there exist constants , which are independent of , such that
19 - For each , , there is a such that
and if is unbounded holds additionally
where is the open ball of radius and center .20 - If restricted to any compact set , the following set of functions is uniformly bounded
- For all holds
where denotes the smallest eigenvalue.21
These regularity conditions correspond one to one to conditions (CS1)–(CS5), given in Sect. 3. For the comparison of these conditions, have in mind that convexity and connectivity are equivalent properties in . The convexity condition in (CS1’) is at first place stronger but it does not impose a real practical restriction, since non-convex are only rarely needed in MIRT. Analogue to the CS-theory (s. Remark 3), conditions involving , like , should be interpreted as almost surely. Condition (CS1’[ii]) on seems more strict than (CS1[ii]). However, Chang and Stout (1993) require additional a proper prior (s. Remark 2). Thus, under the consideration that is still unknown and we consider instead of , the requirements on proper priors in (CS1’[ii]) are analogue to (CS1[ii]). Finally note that in the generalization of conditions (CS3) and (CS4), some requirements have been removed as the remaining requirements on , , and its derivatives are implied by conditions (CS2’) and (CS4’).
A common assumption in one-dimensional IRT models () is the strict monotonicity assumption (3) of in , for all . Conceptually, this represents the notion that a more able subject has a higher probability of responding correct in any item of an educational test. Thus, models fulfilling this strict monotonicity assumption are easier to interpret. However, models with non-generalized-linear latent variable effects can be more adequate in practice. For example, Rizopoulos and Moustaki (2008) considered IRT models with possibly non-monotonic latent variable dependencies (like polynomial effects). Due to this reason, in order to allow for more flexible modeling options, in our semiproper centering theory, we abandon the requirement on strict monotonicity of , for all , in each component. Since the results of Chang and Stout (1993) rely on this monotonicity assumption, the merit of the current contribution is not only the extension of the CS-results for latent vectors () but also for univariate latent variables in case of a non-monotonic latent variable effect.
If all , , are strictly monotonic in each component, then requirement (19) of condition (CS2’) is satisfied as in the univariate case. Otherwise, the requirement in (19) is generally not really restrictive; it is the technical formulation of the notion that the response probabilities can (but not necessarily have to) approach zero or one only if . Assumption (20) in (CS3’) serves for ensuring the identifiability of the latent vector in case of . Hence, this condition is quite natural for a statistical model. In the univariate case, (20) of (CS3’) is implied by the strict monotonicity, too. But in contrast to (19), (20) cannot be concluded directly from the strict monotonicity of all in each component if . Moreover, while a single item can suffice in the univariate case for identifiability, there are always at least q needed in the q-dimensional one. Similarly, the average test information is always singular for , since it is a sum of d rank-one matrices. Condition (CS5’) ensures that becomes regular for and can be interpreted as a condition to ensure that the asymptotic posterior of is regular q-dimensional distributed and does not have a lower dimensional support (cf. Lemma W.6 in the web-appendix).
To get a better impression of the conditions, we exemplary discuss them next for model (22), the multidimensional version of a model of Lee and Bolt (2018) and a logit model with an interaction of the latent variables (Rizopoulos, 2006).
Verification of the CS Regularity Conditions for Multidimensional IRT Models
We shall verify the proposed conditions (CS1’) to (CS5’) for a multidimensional version of a model by Lee and Bolt (2018) and discuss them also for the models of Pelle et al. (2016) and a logit model with interaction of the latent variables (Rizopoulos, 2006).
Consider first the IRT model by Lee and Bolt (2018) or its multidimensional version
| 22 |
If is one of the usual structural models or any other regular distribution, for example , a mixture of normals or a uniform distribution on some compact set, then (CS1’) is directly satisfied. Further, considering the model parameters as random variables, we assume that the parameter sequences and behave as they were two independent iid sequences drawn from absolutely continuous regular distributions in some bounded region in and the sequence is in an arbitrary bounded subset of , then conditions (CS2’) and (CS4’) are directly satisfied. The assumption of regular distributions with a bounded support for the model parameters is reasonable, since in IRT practice items with arbitrarily large discrimination are not realistic and items of arbitrarily high or low difficulty are avoided. Furthermore, in almost all cases, the latent vector is identifiable if q arbitrary items are given. Hence, (CS3’) is satisfied, too. The gradient of the response probabilities is given by
| 23 |
for all and , where denotes the pdf of . In particular, we see from (23), that behaves in almost all cases for all as an iid sequence drawn from a regular distribution with bounded support in , since the parameters are iid distributed for all items and every is considered separately, i.e., is held fixed. Exceptions are pathological cases like the one in which zero belongs to the support of the distributions of all model parameters and all model parameters equal zero, i.e., for all and . However, the subset of such cases is of zero probability for regular continuous distributions, i.e., is a null-set. Thus,
converges to the second moment of the distribution of , as a random vector formed by the multivariate transformation of the randomly selected parameter values described directly after equation (23), and is thus positive definite.
With respect to (CS5’), note that (19) in (CS2’) implies that (21) is equivalent to
| 24 |
which in our case ensures that (CS5’) is satisfied (cf. Lemma W.6 in the web-appendix).
For illustrative purposes, consider an example with and and model parameter values, as given in Table 1, which are independently drawn from a uniform distribution on for , and on for all other parameters.
Table 1.
Hypothetical parameter values for model (22) and the first 30 items.
| i | i | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.906 | 0.946 | 0.398 | 0.230 | 0.327 | 16 | 0.104 | 0.498 | 0.298 | 0.359 | 0.622 |
| 2 | 1.337 | 0.893 | 0.085 | 0.696 | 0.622 | 17 | 0.458 | 0.496 | 0.267 | 0.677 | 0.551 |
| 3 | 0.913 | 0.363 | 0.703 | 0.052 | 0.605 | 18 | 1.882 | 0.259 | 0.484 | 0.101 | 0.022 |
| 4 | 0.387 | 0.166 | 0.313 | 0.352 | 0.447 | 19 | 0.801 | 0.066 | 0.488 | 0.282 | 0.697 |
| 5 | 0.676 | 0.677 | 0.199 | 0.701 | 0.283 | 20 | 1.953 | 0.169 | 0.963 | 0.467 | 0.443 |
| 6 | 0.084 | 0.865 | 0.833 | 0.957 | 0.724 | 21 | 1.712 | 0.326 | 0.979 | 0.146 | 0.347 |
| 7 | 0.138 | 0.688 | 0.444 | 0.942 | 0.043 | 22 | 1.725 | 0.146 | 0.875 | 0.843 | 0.092 |
| 8 | 1.608 | 0.296 | 0.472 | 0.096 | 0.101 | 23 | 1.980 | 0.826 | 0.517 | 0.195 | 0.825 |
| 9 | 0.882 | 0.016 | 0.378 | 0.088 | 0.458 | 24 | 0.171 | 0.197 | 0.722 | 0.069 | 0.442 |
| 10 | 1.240 | 0.320 | 0.924 | 0.250 | 0.386 | 25 | 0.499 | 0.101 | 0.319 | 0.943 | 0.071 |
| 11 | 0.919 | 0.867 | 0.391 | 0.051 | 0.202 | 26 | 1.775 | 0.530 | 0.188 | 0.819 | 0.336 |
| 12 | 0.216 | 0.093 | 0.028 | 0.152 | 0.339 | 27 | 1.523 | 0.302 | 0.646 | 0.581 | 0.718 |
| 13 | 1.900 | 0.726 | 0.007 | 0.842 | 0.072 | 28 | 1.548 | 0.272 | 0.469 | 0.207 | 0.241 |
| 14 | 0.510 | 0.068 | 0.105 | 0.132 | 0.256 | 29 | 0.823 | 0.113 | 0.147 | 0.027 | 0.282 |
| 15 | 1.109 | 0.072 | 0.017 | 0.370 | 0.623 | 30 | 0.822 | 0.661 | 0.485 | 0.277 | 0.017 |
In Fig. 1 (top) visualizations of are provided for two exemplary values of and the parameters in Table 1. In particular, we can recognize lines in , for which holds. In Fig. 1 (bottom), surfaces of are illustrated for further two exemplary values. The surfaces are drawn over . There is a nearly parabolic surface, which illustrates that there is no reason to doubt for (20) in (CS3’).
Fig. 1.

Top left:, top right: , bottom left: , bottom right: .
Figure 2 provides the minimal smallest eigenvalue of on for , cf. (CS5’). Overall, in this case, the regularity conditions can be considered as justified to apply the APN for arbitrary response patterns on the illustrated 30 items.
Fig. 2.
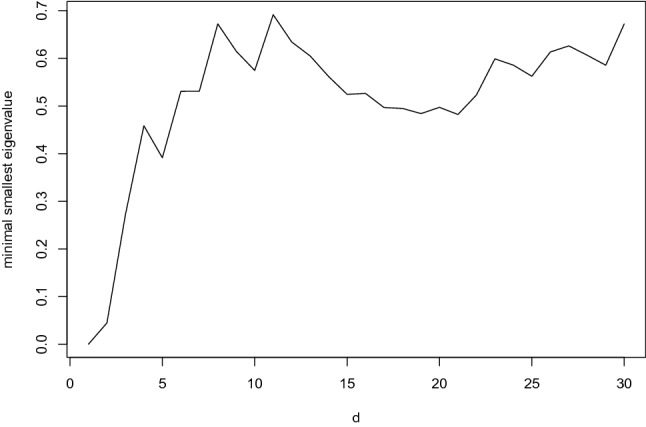
Minimal eigenvalue of for .
Conditions (CS1’) to (CS5’) for other models can be verified similarly. For example, the multidimensional Rasch model implemented in Pelle et al. (2016) is the logit model
| 25 |
where is the probability of inclusion in registration i, given the vector of latent variables. In this case,
would replace (23) for , while the subsequent arguments are the same as above.
Another example is the two-dimensional model
which is a logit model that contains an interaction term between the two latent variables and was considered by Rizopoulos (2006) (see Section 4). While it is still logit-linear in the model parameters , , , it is no longer linear in the latent variables. However, with
the same arguments still apply (compare also to Rizopoulos and Moustaki (2008), who discuss MIRT models within a more general form of the generalized latent variable model, allowing nonlinear effects of latent variables).
Main Results
Our main contribution is the generalization of Theorems 1 and 3 of Chang and Stout (1993) for , under the assumptions (CS1’) to (CS5’). Furthermore, we embed the CS-approach in the GGS framework (see Theorem 5 (iii)). Similarly to Chang and Stout (1993), the consistency of the MLE is received as a by-product, along with an assertion on its existence. Additionally, the consistency of a penalized MLE is derived. The results are provided in the next theorem, while their proofs along with some preliminary required lemmas are given in appendix.
Theorem 5
Let be a q-variate standard normal distributed random vector and is a sequence of binary response variables for a sequence of item response functions satisfying (CS1’[i]), (CS2’) and (CS3’) for . Then, the following statements holds:
-
(i)There is a sequence of measurable mappings so that
and for . -
(ii)Statement (i) remains valid if is replaced by the penalized log-likelihood
for some continuously differentiable, positive and bounded function .
-
(iii)If additional (CS1’[ii]), (CS4’) and (CS5’) are satisfied, then the following statement holds: If is held fix, then, for all ,
That is, the MLE is a semiproper centering (cf. Definition 1). If , where is an absolutely continuous proper distribution with , then furthermore26
for all .27
Remark 5
For , the penalized MLE in part Theorem 5 (ii) becomes the maximum a-posteriori estimator (MAP), which is an important estimator for in IRT, also because it ensures the existence of estimates in cases the MLE becomes infinite (for example when or d). The restriction on in part (ii) is stronger than (CS1’[ii]), but still mild.
As already noted in Sect. 3, Theorem 5 (iii) can be used for the construction of credible regions for . Additionally, it allows the interpretation of the MLE as a Bayesian estimator of and thus enables the use of to derive some kind of objective posterior, in the sense that it is prior-free constructed.
An important concept in the asymptotic analysis of Bayesian procedures is the consistency of the posterior distribution, which forms a basis for the asymptotic validity of inferential methods, and is proved in Theorem 6 (i). The consistency of the EAP is stated in Theorem 6 (ii).
Theorem 6
Consider the setup and the assumptions of Theorem 5(iii), the following statements hold:
-
(i)If is held fix, then
for all Borel-sets with . -
(ii)Suppose that is held fix and that there is a continuous mapping so that exists. Then, the posterior expected value exists for all and is weakly consistent for , i.e.,
If in particular exists, then the posterior expected value exists for all and is weakly consistent for .
Simulation Study
The simulation study that follows examines the convergence to zero of the error for the approximation of the MLE-centered normalized posterior by a standard normal distribution and its relation to the convergence of the MLE, for the case of a bivariate latent variable vector (). Convergences are evaluated based on the following measures. For the MLE, we use the root-mean-square error
For the approximation of the normalized posterior density by a bivariate normal pdf , we compute the density approximation error (also known as -distance)
the Hellinger-distance
and the Kullback–Leibler divergence
The simulation study is based on model (22) with the same item parameters across all replications, to mimic the situation that different persons respond on the same test. These are generated as in Sect. 6. For the structural model we assume , resulting in . The number of items d varies from 10 to 70 in steps of ten items, to mimic the asymptotic behavior with test lengthening. All involved integrals are approximated using an importance sampling Monte Carlo (MC) approximation with being the importance distribution.
We replicate 1000 times () the following procedure.
Draw .
Draw from model (22) with underlying true latent variable vector and item parameter values as described above (setting if and otherwise, where is drawn from iid , ). Then set , for .
Compute the MLE and the test information matrix , based on , for .
Derive the posterior pdf of the normalized latent vector , estimating its normalization constant by a MC quadrature.
Compute , , and , for .
Our results are visualized in Fig. 3, where the box-plots of the RMS, DAE, HD and KLD values computed above are pictured, for all d values considered. As expected, all evaluation measures and their range are decreasing in d.
Fig. 3.

Box-Plots of the RMSE, DAE, HD and KLD simulated values for . Under every d value on the horizontal axis, the percentage of points located outside the corresponding whiskers is given.
Table 2 provides the average values of the evaluation measures, i.e., , and , , and , defined analogously. Notice that in our simulation study in case of relatively small number of items (), we observed simulation cycles for which the Kullback–Leibler divergence was numerically infinite (due to floating point arithmetics), indicating that the divergence between the two compared distributions for these cases was extremely large. In particular, this occurred in 112 cases for , 20 cases for and one case for (out of 1000). These cases were excluded from the calculation of the corresponding average KLD-values reported in Table 2.
Table 2.
Average values of the root-mean-square error (RMSE) for the MLE along with the density approximation error (DAE), the Hellinger distance (HD) and the Kullback–Leibler divergence (KLD) between the density of the MLE-centered normalized posterior distribution and a bivariate standard normal density, based on 1000 simulations of model (19) with , for different numbers of items d.
| d | ||||
|---|---|---|---|---|
| 10 | 1.4105 | 1.1416 | 0.1330 | 3.0803 |
| 20 | 0.8206 | 0.8267 | 0.0885 | 1.2698 |
| 30 | 0.6730 | 0.7272 | 0.0750 | 0.8601 |
| 40 | 0.5658 | 0.6314 | 0.0634 | 0.5922 |
| 50 | 0.4552 | 0.5222 | 0.0515 | 0.3850 |
| 60 | 0.3859 | 0.4510 | 0.0439 | 0.2776 |
| 70 | 0.3530 | 0.4184 | 0.0403 | 0.2303 |
Figure 4 visualizes the relation of the divergence measures of the normalized posterior from the standardized normal distribution to the RMSE of the MLE for the values of Table 2, pictured for . Observe that as d increases, and are linear in , while is linear in . This is an indication that DAE and HD have the same rate of convergence to zero as RMSE while that of KLD is scaled by .
Fig. 4.

Linear regression of and on and of on for (s. Table 2).
Notice that the convergence of the DAE to zero in probability is equivalent to proper centering. Thus, our simulation results suggest that the MLE is a proper centering for the multivariate version of the model of Lee and Bolt (2018) with the parameters we consider.
Simulation studies for other IRT models can be conducted similarly, expecting analogous results.
Discussion
In this work, we proved the APN of LTs under mild conditions that are fulfilled by a broad class of MIRT models for binary items. Furthermore, we obtained as by-products the existence and consistency of the MLE and the MAP estimator. Note that though the MLE is commonly known as consistent in IRT and MIRT settings, Sinharay (2015) indicated the lack of asymptotic results under milder conditions than some of the usual ones (such as test lengthening by strictly parallel forms). Thus, Theorem 5 (i) is a contribution toward this direction.
The distribution in Theorem 5 (iii) can be different from used in the model. Hence, the asymptotic result above is robust to misspecifications of as long as the support is sufficiently large. An interesting task for further investigation, pointed out by one of the reviewers, is the study of the effect of misspecified item response functions.
Under similar mild conditions we provided results on the weak consistency of posterior distributions. In Theorem 6 (ii), we get the existence and consistency of the expected a-posteriori estimator (EAP) for estimating as well as for estimating . To the best of our knowledge, a proof of these properties in such a general setup and under comparably mild or milder conditions on the MIRT model does not exist in the related literature.
Our results are under the assumption of a proper prior . This is appropriate in IRT settings, where the prior is a model of the population distribution of the latent traits. However, in a Bayesian framework, improper priors can also be considered. If this is the case, the proper prior assumption in (CS1’[ii]) can be replaced by the following condition if the posterior is still proper
| 28 |
Condition (28) is sufficient for the derivation of the results stated here and is satisfied by a proper prior.
The APN for a univariate LT for polytomous items was discussed by Chang (1996). The extension of the results for MIRT models with polytomous items is the subject of our current research.
Here, we derived conditions for APN of LTs by generalizing the contribution of Chang and Stout (1993) to . The methodology of GGS/IH, discussed in Sect. 4, provides a general framework for APN in various contexts, including MIRT. The results of Ghosal (1997, 1999) are helpful in deriving alternative conditions for APN tailored for MIRT models.
Supplementary Information
Below is the link to the electronic supplementary material.
Acknowledgements
The authors thank the associate editor and the reviewers for their constructive and useful comments on earlier versions of the manuscript.
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Appendix: Proofs of Theorems in Section 7
Here, we prove the main results Theorem 5 and 6 and provide required lemmas for their proof. More detailed versions of all proofs including preliminary results are provided in the web-appendix.
For the proof of Theorem 5 (i) the following lemma is required. This lemma ensures that for , a global maximum of the log-likelihood has to be in an arbitrarily small area around , thus being the main step to prove the consistency of the MLE.
Lemma 1
Consider and assume that conditions (CS1’[i]), (CS2’) and (CS3’) are satisfied for a fixed . Then, for any there is a so that
Proof
A more detailed version of the proof can be found in the web-appendix (p. 3).
Consider an arbitrary . One can show that the associated sequence of item response functions is equicontinuous on each compact set (compare Lemma W.1 in the web-appendix). This implies, applying the strong law of large numbers, that
for each compact for which a exists such that with a constant (compare the more detailed version of the proof in the web-appendix). This is in particular true for
for each and . Finally, we get with probability tending to one for that
Proof of Theorem 5(i)–(ii)
A more detailed version of the proof can be found in the web-appendix (p. 7).
Analogously to the proof of Corollary 3.1 of Chang and Stout (1991), notice that
| A1 |
if the MLE exists due to its definition as global maximum. From Lemma 1 follows, that every global maximum of the log-likelihood has to be in every arbitrary small region around with probability tending to one for , which implies consistency. The existence of the MLE and further its derivation as solution of the likelihood equations can be shown completely analogous to classical iid cases (e.g., Lehmann & Casella, 1998, Chapter 6, Theorem 5.1, p. 463).
Considering the modified log-likelihood function
of part (ii), the consistency is obtained by replacing by in Lemma 1 and part (i) of this theorem.
The following lemma ensures the log-likelihood-ratio can be well approximated by a quadratic form of the test information matrix, which is an essential part for the proof of Theorem 5(iii). Lemma 3 and Corollary 1 provided in the sequel, are additionally required for the proof of Theorem 5(iii) and Theorem 6.
Lemma 2
Suppose that conditions (CS1’) through (CS5’) hold. Denote by the Hessian matrix of . Set , which is estimated by , if exists, and by otherwise, where is the identity matrix, . Then, we have the following.
- There is a sequence , , such that for
where , it holds with probability tending to 1 for , thatA2
.A3 - For any , there is a such that
where denotes the spectral norm for a matrix .A4 - For any , there is a so that for all
where
Recall that if a matrix is symmetric and positive definite, then and hold, where and denote the largest and smallest eigenvalues of a matrix.
Proof
An extended proof is provided in the web-appendix (p. 14).
Equation (A2) follows directly from a second-order Taylor expansion of at . Theorem 5(i) and conditions (CS2’) and (CS5’) imply the existence of with probability tending to one for (compare Lemma W.6 in the web-appendix) and, therefore, (A3). Condition (CS5’) further implies for some constant and that
One can show that the conditions imposed imply that
are equicontinuous in every compact and convex region in (compare Lemma W.4 in the web-appendix on p. 11). Kolmogorov’s strong law of large numbers leads then to
for and some appropriate constants . Since the MLE is consistent and for every it holds
(recall lies between and ), we get for
Notice that
for every , symmetric and positive definite and any further matrix . The final part follows by selecting and for .
Lemma 3
Let for all with . Consider a sequence for a fixed , for which conditions (CS1’ [i]), (CS2’) through (CS5’), and either (CS1’ [ii]) or (28) are satisfied. Then, the following holds.
- For every function f that is either absolutely bounded by a constant or for which the integral exists, and for every , it holds
A5 - Consider a sequence with satisfying either
orA6
for all bounded . Then, for , it holdsA7
In particular, in case of (A7), it holds
Proof
A more detailed version of the proof can be found in the web-appendix (p. 17). 1. With regard to the left-hand side of (A5), note that, in terms of the log-likelihood function, it can be written as
| A8 |
where
while it always fulfills
If is improper and f is bounded by a constant, (28) directly implies
In any other case, Lemma 1 leads to
Finally, from the polynomial grows of , it follows
2. Let be an arbitrary bounded Borel set and define for and the set
and the integral
Using the definition of in Lemma 2, it holds
| A9 |
By (CS1’), i.e., the continuity of and , it follows that for every , it exists a , such that
| A10 |
Furthermore, by Lemma 2 we get for any and appropriate :
| A11 |
| A12 |
In the case of (A6), it holds . Selecting and arbitrarily small leads to
In the case of equation (A7), we get for each : . Condition (CS5’) implies
Finally, the further valid selection of arbitrary small in (A12) and the application of Lemma 3(1.) on completes the proof.
For , Lemma 3(2.) leads directly to the following Corollary.
Corollary 1
Suppose a sequence for a fixed , for which conditions (CS1’) through (CS5’) hold. Then holds for
Proof of Theorem 5(iii)
An extended proof can be found in the web-appendix (p. 21).
Analogously to the proof of Lemma 2, we can assume without loss of generality that exists. Set
Then, (26) for bounded B follows directly from the reformulation
due to Lemma 3 part 2 and Corollary 1. The case of unbounded B can be shown by considering a decomposition for bounded and pairwise disjoint (compare to the web-appendix, p. 21–22). Next, set for all , and
where is the pdf of . Then, (27) follows from
for each , which is valid due to (26) and Lebesgue’s theorem of dominated convergence.
Proof of Theorem 6
A more detailed proof is provided in the web-appendix (p. 23).
Part (i) follows directly from Lemma 3 and Corollary 1 by using the reformulation
| A13 |
for an arbitrary with .
Next, we prove part (ii). In a first step, the existence of for all functions , which are continuous and for which the integral exists, will be proved. In a second step its consistency for will be discussed.
For every , it holds
for all , since , is positive and independent of , and exists if and only if exists. Hence, exists. Furthermore, it remains integrable for , as shown next. Notice that the last statement does not follow directly, since for any sequence and .
Adjusting representation (A13), we have
with for an arbitrary .
Further, for every it holds
where the last two terms converge to zero in probability by Lemma 3, Corollary 1 and part (i). Last, the continuity of f implies for each and appropriate :
The second part follows directly by considering the mappings , , in the first part, which are continuous and by assumption integrable.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Footnotes
Mia J. K. Kornely appreciates the financial support of the Heinrich-Böll-Stiftung e.V. in form of a PhD scholarship (Grant No. P127357)
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Anderson CJ, Li Z, Vermunt JK. Estimation of models in a Rasch family for polytomous items and multiple latent variables. Journal of Statistical Software. 2007;20(6):1–36. doi: 10.18637/jss.v020.i06. [DOI] [Google Scholar]
- Anderson CJ, Vermunt JK. Log-multiplicative association models as latent variable models for nominal and/or ordinal data. Sociological Methodology. 2000;30:81–121. doi: 10.1111/0081-1750.00076. [DOI] [Google Scholar]
- Anderson, C. J., & Yu, H.-T. (2017). Properties of Second-Order Exponential Models as Multidimensional Response Models. In L. A. van der Ark, M. Wiberg, S. Culpepper, J. A. Douglas, & W. C. Wang (Eds.), Quantitative Psychology. IMPS 2016. Springer Proceedings in Mathematics & Statistics (Vol. 196). Springer.
- Chang H-H. The asymptotic posterior normality of the latent trait for polytomous IRT models. Psychometrika. 1996;61(3):445–463. doi: 10.1007/BF02294549. [DOI] [Google Scholar]
- Chang, H.-H., & Stout, W. (1991). The asymptotic posterior normality of the latent trait in an IRT model. Technical Report ONR Research Report 91-4, Department of Statistics, University of Illinois at Urbana-Champaign.
- Chang H-H, Stout W. The asymptotic posterior normality of the latent trait in an IRT model. Psychometrika. 1993;58(1):37–52. doi: 10.1007/BF02294469. [DOI] [Google Scholar]
- Ghosal S. Normal approximation to the posterior distribution for generalized linear models with many covariates. Mathematical Methods of Statistics. 1997;6:332–348. [Google Scholar]
- Ghosal S. Asymptotic normality of posterior distributions in high dimensional linear models. Bernoulli. 1999;5:315–331. doi: 10.2307/3318438. [DOI] [Google Scholar]
- Ghosal S, Ghosh JK, Samanta T. On convergence of posterior distributions. The Annals of Statistics. 1995;23(6):2145–2152. doi: 10.1214/aos/1034713651. [DOI] [Google Scholar]
- Ghosh, J. K., Ghosal, S., & Samanta, T. (1994). Stability and convergence of the posterior in non-regular problems. Statistical Decision Theory and Related Topics V (pp. 183–199). Springer.
- Hessen DJ. Fitting and testing conditional multinormal partial credit models. Psychometrika. 2012;77(4):693–709. doi: 10.1007/s11336-012-9277-1. [DOI] [Google Scholar]
- Holland PW. The Dutch identity: A new tool for the study of item response models. Psychometrika. 1990;55(1):5–18. doi: 10.1007/BF02294739. [DOI] [Google Scholar]
- Ibragimov, I. A., & Has’minskii, R. Z. (1981). Statistical estimation: Asymptotic theory. Springer.
- Kornely, M. J. K. (2021). Multidimensional Modeling and Inference of Dichotomous Item Response Data. PhD thesis, RWTH Aachen University, Germany.
- Lee S, Bolt DM. An alternative to the 3pl: Using asymmetric item characteristic curves to address guessing effects. Journal of Educational Measurement. 2018;55(1):90–111. doi: 10.1111/jedm.12165. [DOI] [Google Scholar]
- Lehmann, E. L., & Casella, G. (1998). Theory of point estimation (2nd ed.). Springer.
- Li, Z. (2010). Loglinear models as item response models. PhD thesis, University of Illinois at Urbana-Champaign.
- Lord FM. Unbiased estimators of ability parameters, of their variance, and of their parallel-forms reliability. Psychometrika. 1983;48(2):233–245. doi: 10.1007/BF02294018. [DOI] [Google Scholar]
- Paek, Y. (2016). Pseudo-Likelihood Estimation of Multidimensional Polytomous Item Response Theory Models. PhD thesis, University of Illinois at Urbana-Champaign.
- Pelle E, Hesse D, van der Heijden PGM. A log-linear multidimensional rasch model for capture-recapture. Statistics in Medicine. 2016;35:622–634. doi: 10.1002/sim.6741. [DOI] [PubMed] [Google Scholar]
- Rabe-Hesketh S, Skrondal A, Pickles A. Reliable estimation of generalized linear mixed models using adaptive quadrature. The Stata Journal. 2002;2(1):1–21. doi: 10.1177/1536867X0200200101. [DOI] [Google Scholar]
- Rizopoulos D. ltm: An R package for latent variable modeling and item response theory analyses. Journal of Statistical Software. 2006;17(5):1–25. doi: 10.18637/jss.v017.i05. [DOI] [Google Scholar]
- Rizopoulos D, Moustaki I. Generalized latent variable models with non-linear effects. British Journal of Mathematical and Statistical Psychology. 2008;61(2):415–438. doi: 10.1348/000711007X213963. [DOI] [PubMed] [Google Scholar]
- Schilling S, Bock RD. High-dimensional maximum marginal likelihood item factor analysis by adaptive quadrature. Psychometrika. 2005;70(3):533–555. [Google Scholar]
- Sinharay S. The asymptotic distribution of ability estimats: Beyond dichotomous items and unidimensional IRT models. Journal of Educational and Behavioral Statistics. 2015;40(5):511–528. doi: 10.3102/1076998615606115. [DOI] [Google Scholar]
- Walker AM. On the asymptotic behaviour of posterior distributions. Journal of the Royal Statistical Society. Series B (Methodological) 1969;31(1):80–88. doi: 10.1111/j.2517-6161.1969.tb00767.x. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.