
Figure 1.
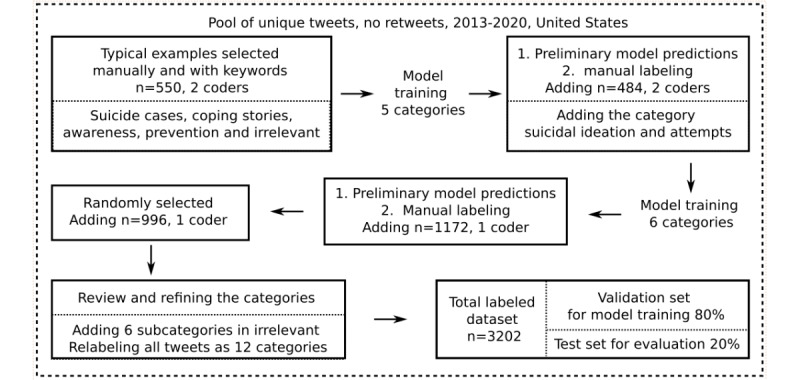
Creating the labeled data set and annotation scheme. Each box describes how tweets were selected from the large pool of available tweets, how many tweets were added to the training data set in each step (after removing duplicates), and how many coders labeled each tweet. When we used preliminary model predictions to identify potential candidates for each category, we deleted the model labels before manual coding. After rounds with 2 coders, we checked interrater reliability, adapted the annotation scheme until all disagreements were clarified, and relabeled the respective sample.