
Figure 5.
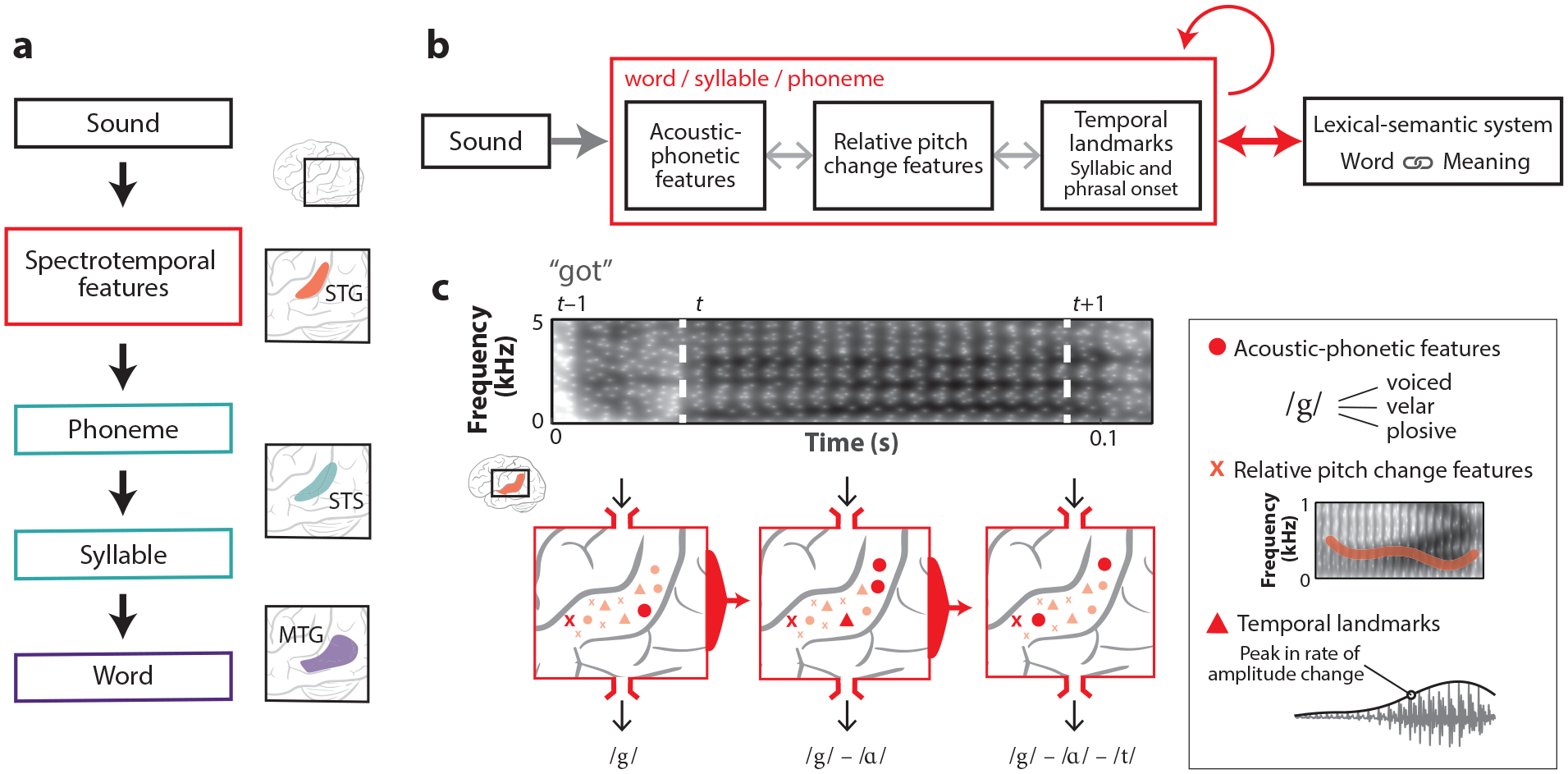
A new model of phonological analysis. (a) Classical model of auditory word recognition in which primarily serial, feedforward, hierarchical processing takes place. The first processing step is spectrotemporal analysis, through which relevant features are extracted. Spectrotemporal features are grouped into phonemic segments that are then sequentially assembled into syllables. Finally, the lexical interface maps phonological sequences onto word-level representations. In classic models of auditory word recognition, each processing step is assigned to an approximate anatomical location (the schematic to the right shows an example of these assignments). The neural representation of speech becomes of increasingly higher order as it moves through successive brain areas. (b) An alternative recurrent, multi-scale, and interactive model of auditory word recognition that more closely aligns with the presented neurophysiological evidence. Acoustic signal inputs are analyzed concurrently by local processors with selectivity for acoustic phonetic features, salient temporal landmarks (e.g., peakRate), and prosodic features that occur over phonemic segments. The light gray bidirectional arrows indicate that local processors interact with one another. Recurrent connectivity indicates an integration of temporal context and sensitivity to phonological sequences by binding inputs over time during word processing. Anticipatory top-down, word-level information arises from the lexical-semantic system and the internal dynamics of ongoing phonological analysis. (c) Three local neuronal populations (circles, triangles, and crosses) on the STG encode relative (speaker-normalized) formant values, relative pitch changes, and the magnitude of peakRate events. In addition to being functionally diverse, these populations likely show distinct electrophysiological signatures (i.e., sustained versus rapid responses) (see Figure 2). The encoding of normalized spectral content (formants and pitch) suggests the presence of a context-sensitive mechanism that enables rapid retuning to speaker-specific spectral bands. Together, this set of neural responses and the responses at the previous time step define a neural state from which the appropriate word form can be decoded. Every sound segment is processed by the STG in a highly specific context that is sensitive to both temporal and phonological information. Abbreviations: MTG, middle temporal gyrus, STG, superior temporal gyrus; STS, superior temporal sulcus.