
Figure 3. A map of LCRs captures known differences in higher order assemblies.
(A) UMAP of all LCRs in the human proteome. Each point is a single LCR and its position is based on its amino acid composition (see Methods for details). Clusters identified by the Leiden algorithm are highlighted with different colors. Labels indicate the most prevalent amino acid(s) among LCRs in corresponding Leiden clusters. (B) LCRs of annotated nuclear speckle proteins (obtained from Uniprot, see Methods) plotted on UMAP. (C) Same as (B), but for extracellular matrix (ECM) proteins. (D) Same as (B), but for nucleolar proteins. (E) Barplot of Wilcoxon rank sum tests for amino acid frequencies of LCRs of annotated nuclear speckle proteins compared to all other LCRs in the human proteome. Filled bars represent amino acids with Benjamini-Hochberg adjusted p-value < 0.001. Positive Z-scores correspond to amino acids enriched in LCRs of nuclear speckle proteins, while negative Z-scores correspond to amino acids depleted in LCRs of nuclear speckle proteins. (F) Same as (E), but for extracellular matrix (ECM) proteins. (G) Same as (E), but for nucleolar proteins. See also Figure 3—figure supplements 1–3.
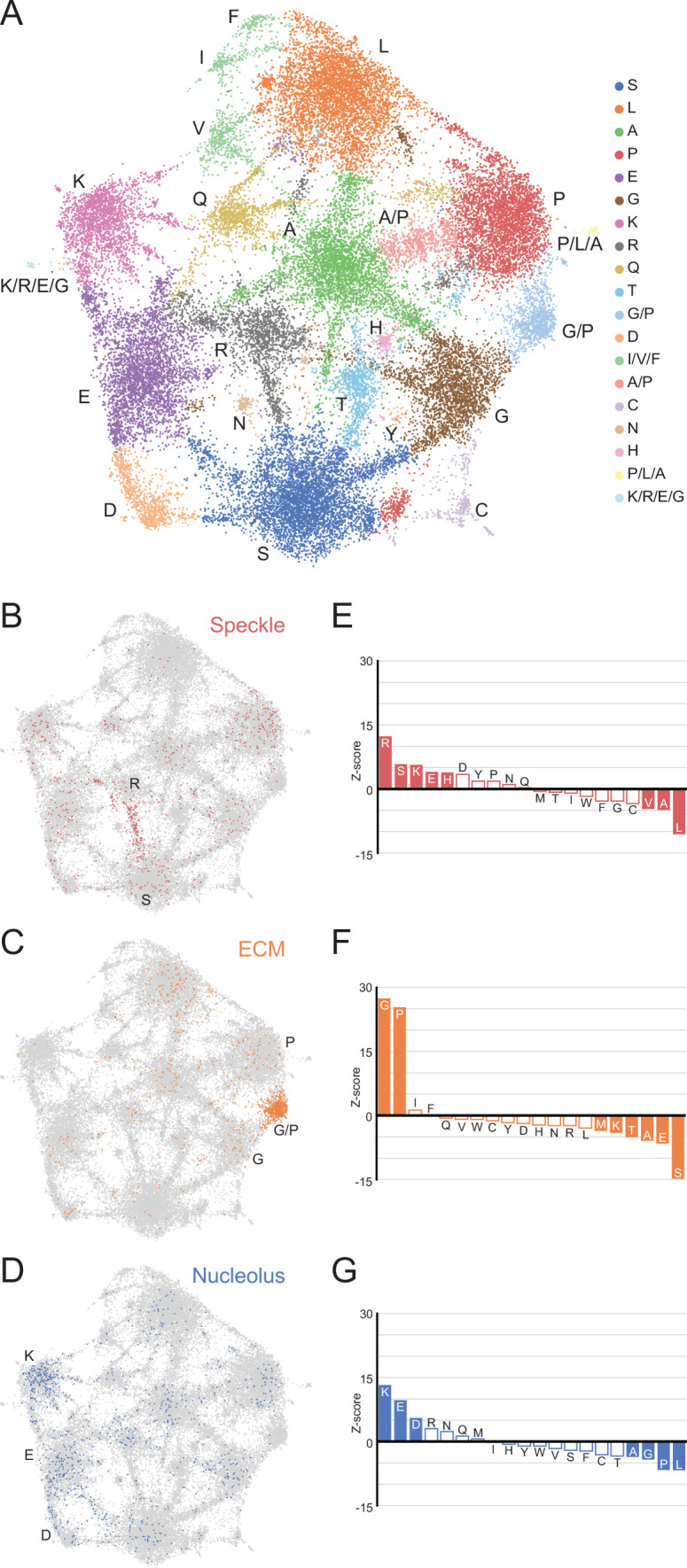
Figure 3—figure supplement 1. Amino acid frequency distributions on human proteome UMAP from Figure 3A.

Figure 3—figure supplement 2. Nuanced sequence differences among LCRs correspond to their positions in the UMAP.

Figure 3—figure supplement 3. LCRs of known higher order assemblies annotated on onto human proteome UMAP from Figure 3A.
