
Figure 2:
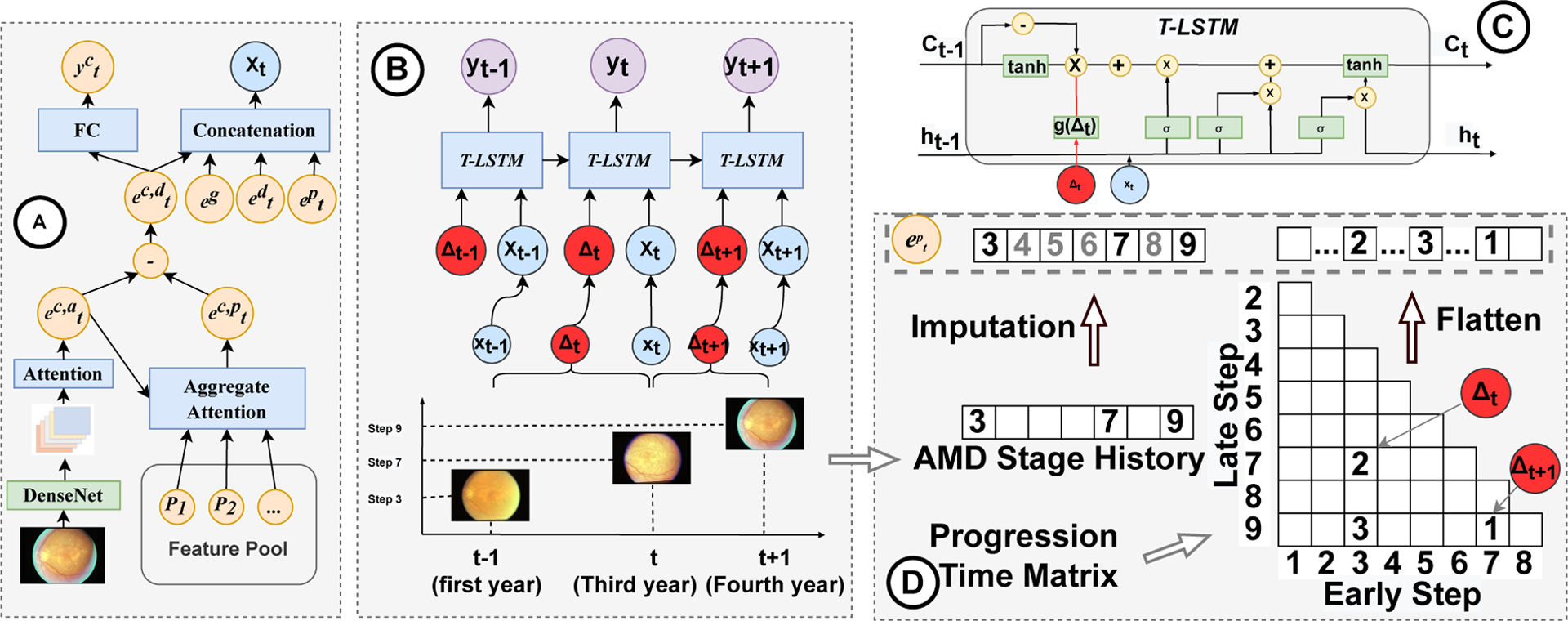
Framework of CAT-LSTM. (A) CNN with contrastive attention module. we adopt DenseNet and an attention module to represent an individual eye image as a vector . Contrastive attention module removes the common feature and generate an abnormal feature vector , which is used to predict AMD steps in current visit. (B) T-LSTM. We obtain tth visit’s feature xt by combining the CFP feature , genotype feature eg, sociodemographic feature and progression feature Then xt and time gaps Δt between successive visits are sent to T-LSTM to model the temporal CFP sequences. T-LSTM output the AMD prediction results yt at each time step. (C) Details of T-LSTM. (D) Progression embedding. We generate an AMD stage history vector based on previous visits and impute the missing AMD steps. Then we build a AMD progression time matrix to represent how many years it takes for the eye to progress from earlier AMD step to later AMD step. We flatten the matrix and concatenate it with the imputed AMD step history vector to generate the progression embedding .