
Figure 3:
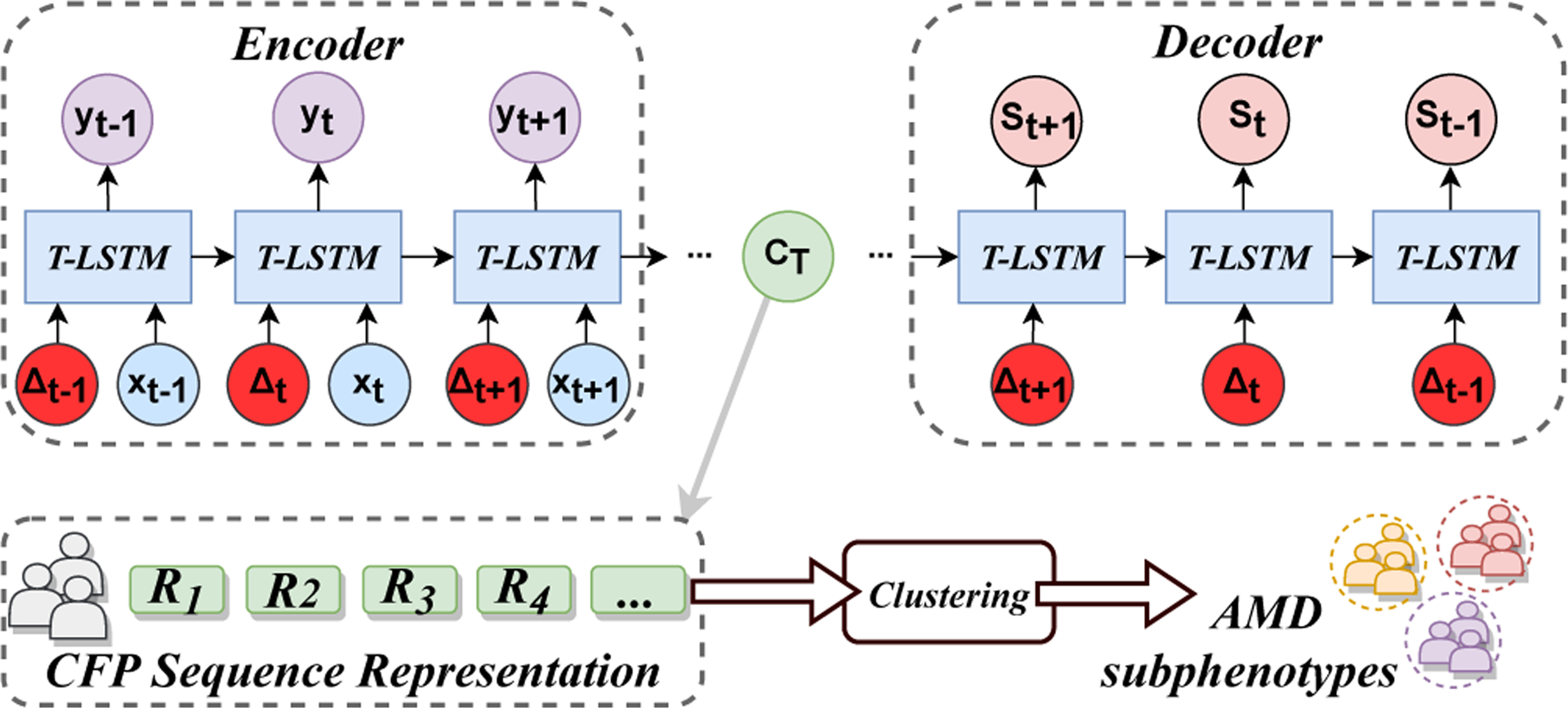
We use an auto-encoder represent the CFP sequences as vectors. Encoder takes visits’ feature xt and time gaps Δt as inputs. Decoder output the previous AMD steps st at different time. The memory vector CT contains the CFP sequence information of the eye. Finally, we group eye representations CT into AMD subphenotypes.