
Figure 1:
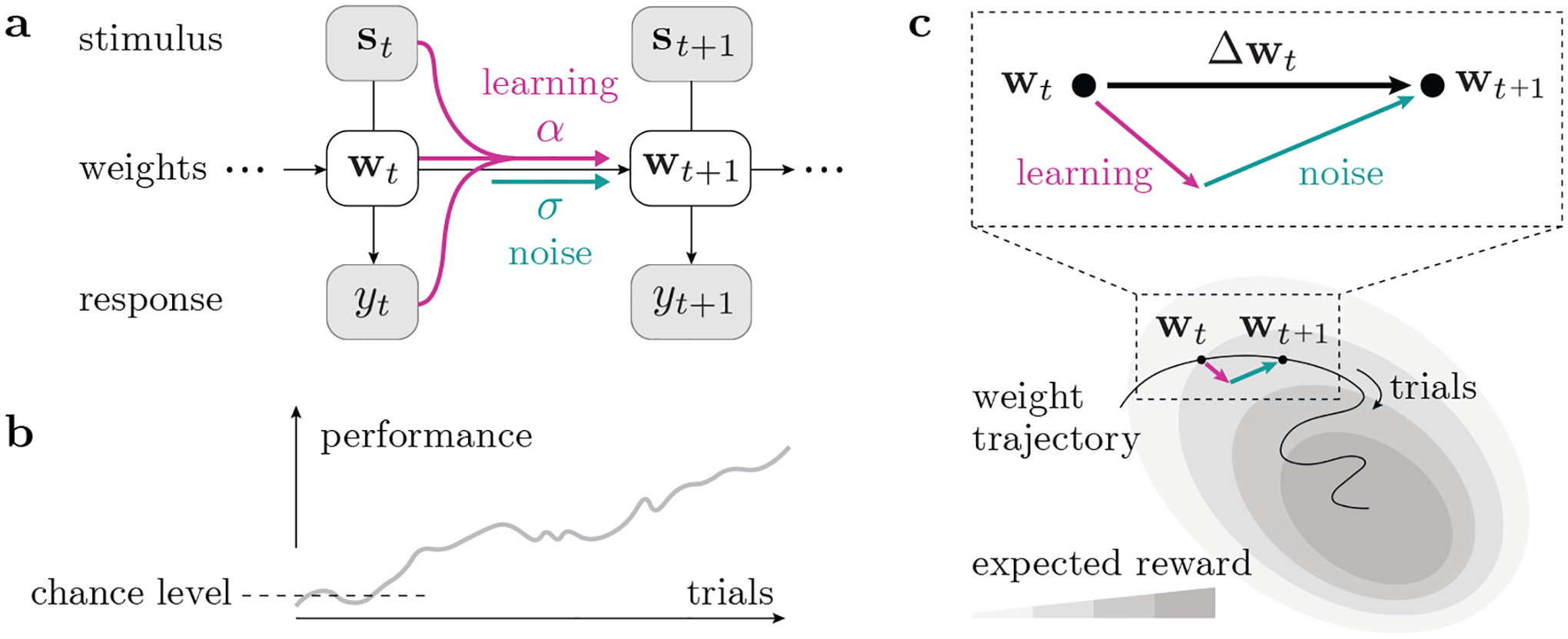
Model schematic. (a) We use a state-space representation with a set of time-varying weights wt, whose change is driven by a learning process as well as noise. (b) Animals usually improve their task performance with continued training, such that their expected reward gradually increases; however, the trial-to-trial change of behavior is not always in the reward-maximizing direction. (c) Considering the animal’s learning trajectory in weight space, we model each step Δwt as a sum of a learning component (ascending the expected reward landscape) and a random noise component.