
Figure 4.
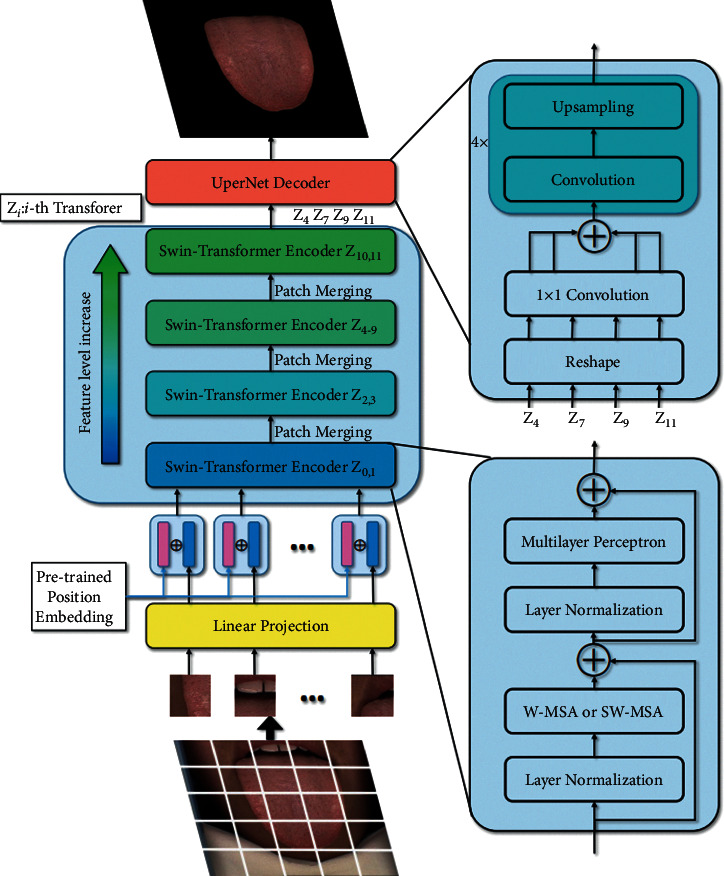
Architecture of tongue segmentor. The tongue image is divided into several patches and then added with position embeddings to retain spatial information. The encoder consists of cascaded Swin Transformers, while UperNet decoder is applied to aggregate multilevel features from encoder.